Command Palette
Search for a command to run...
UI-Voyager:一种基于失败经验进行自我演进的 GUI Agent
UI-Voyager:一种基于失败经验进行自我演进的 GUI Agent
摘要
随着多模态大语言模型(MLLMs)的进步,自主移动图形用户界面(GUI)代理(Agent)日益受到关注。然而,现有方法在处理长周期 GUI 任务时,仍面临从失败轨迹中学习效率低下以及在稀疏奖励下难以进行明确信用分配(credit assignment)的问题。针对上述挑战,我们提出了 UI-Voyager,这是一种新颖的两阶段自进化移动 GUI 代理。在第一阶段,我们采用拒绝微调(Rejection Fine-Tuning, RFT),实现了数据与模型在完全自主循环中的持续协同进化。第二阶段引入了组相对自蒸馏(Group Relative Self-Distillation, GRSD),该方法能够识别组 rollout 中的关键分叉点,并从成功轨迹中构建稠密的步骤级监督信号以修正失败轨迹。在 AndroidWorld 数据集上的大量实验表明,我们的 4B 模型取得了 81.0% 的 Pass@1 成功率,不仅超越了众多近期基线模型,更达到了超越人类水平的性能。消融实验与案例分析进一步验证了 GRSD 的有效性。我们的方法代表了迈向高效、自进化且高性能的移动 GUI 自动化的一大飞跃,且无需昂贵的人工数据标注。
一句话总结
腾讯混元团队提出了 UI-Voyager,这是一种两阶段自进化移动 GUI 智能体,利用拒绝微调(Rejection Fine-Tuning)和组相对自蒸馏(Group Relative Self-Distillation)来克服长视野任务中的稀疏奖励问题。该方法在无需昂贵人工标注的情况下,在 AndroidWorld 上实现了人类水平的性能,显著推动了高效移动自动化的发展。
主要贡献
- 本文介绍了 UI-Voyager,这是一种两阶段自进化移动 GUI 智能体,通过拒绝微调实现数据与模型的协同进化,无需人工标注即可自动化完成这一过程。
- 提出了一种组相对自蒸馏方法,通过识别组 rollout 中的关键分叉点,从成功轨迹中生成稠密的步骤级监督信号以纠正失败轨迹,从而解决模糊的信用分配问题。
- 在 AndroidWorld 基准测试上的实验表明,4B 参数模型达到了 81.0% 的 Pass@1 成功率,优于近期基线模型,并超过了报告的人类水平性能。
引言
自主移动 GUI 智能体对于使 AI 能够导航复杂、动态的智能手机界面至关重要,然而现有方法在学习稀疏的轨迹级奖励时,往往面临数据效率低下和信用分配模糊的困境。先前的方法通常丢弃失败的交互尝试,且缺乏识别导致任务失败的具体步骤的精度,阻碍了长视野任务的稳定策略优化。为了解决这些问题,作者提出了 UI-Voyager,这是一种自进化智能体,采用两阶段流程:结合拒绝微调以实现自主的数据 - 模型协同进化,并利用组相对自蒸馏从成功轨迹中生成稠密的步骤级监督信号以纠正失败轨迹。
数据集
- 作者专注于 AndroidWorld 环境,这是一个专为在移动设备上训练和评估 GUI 智能体而设计的动态交互式基准。
- 该数据集包含 116 个多样化的程序化任务,其复杂度和最优交互步骤各不相同,旨在挑战智能体的性能。
- 与静态数据集不同,该环境允许操作改变 UI 状态,并在任务成功完成时提供奖励信号。
- 本文利用该设置来评估智能体处理不可预测的 UI 行为的能力,以及其从试错中学习而非仅依赖预收集交互日志的能力。
- 提供的文本中未详细说明具体的训练划分、混合比例或图像裁剪策略,因为该环境主要作为严格的评估基准使用。
方法
作者提出了 UI-Voyager,这是一种自进化训练流程,旨在通过两阶段迭代过程优化移动 GUI 智能体。整体框架集成了用于高质量数据筛选的拒绝微调(RFT)和用于步骤级策略细化的组相对自蒸馏(GRSD)。请参阅框架图以了解完整的流程结构。
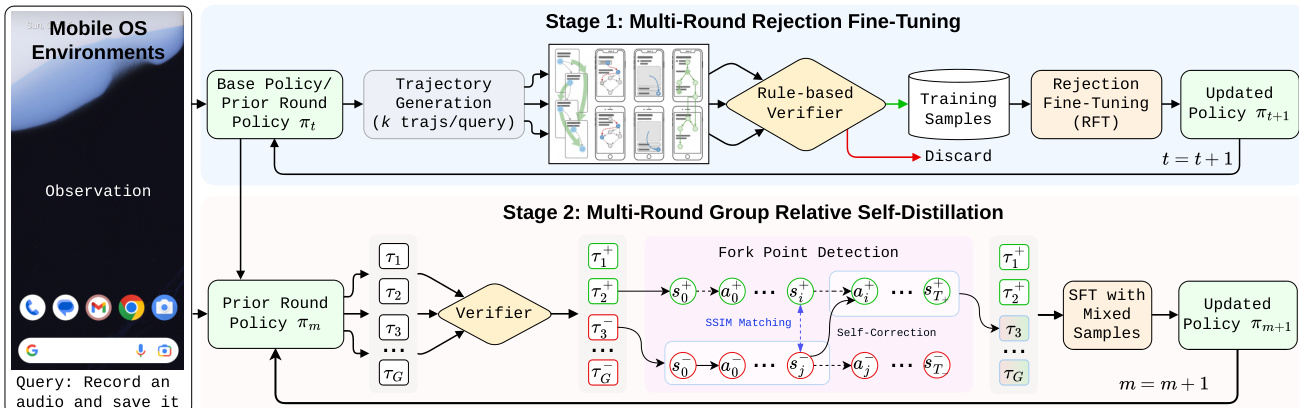
第一阶段是拒绝微调(RFT),旨在建立一个闭环系统以提升数据质量。基础策略为给定任务生成多条轨迹,随后由基于规则的验证器进行评估。仅保留成功完成任务或通过验证器的轨迹用于监督微调(SFT)。这种拒绝采样机制确保模型使用高保真样本进行更新,从而形成一个协同进化循环,即模型改进会在后续轮次中带来更优的轨迹合成。
第二阶段是组相对自蒸馏(GRSD),旨在解决长视野多轮任务中固有的信用分配问题。与依赖稀疏轨迹级奖励的标准强化学习方法(如 PPO 或 GRPO)不同,GRSD 利用组内的成功轨迹为失败尝试提供稠密的步骤级监督。如下图所示,该方法识别成功轨迹与失败轨迹之间的具体分歧点,以指导自我修正。
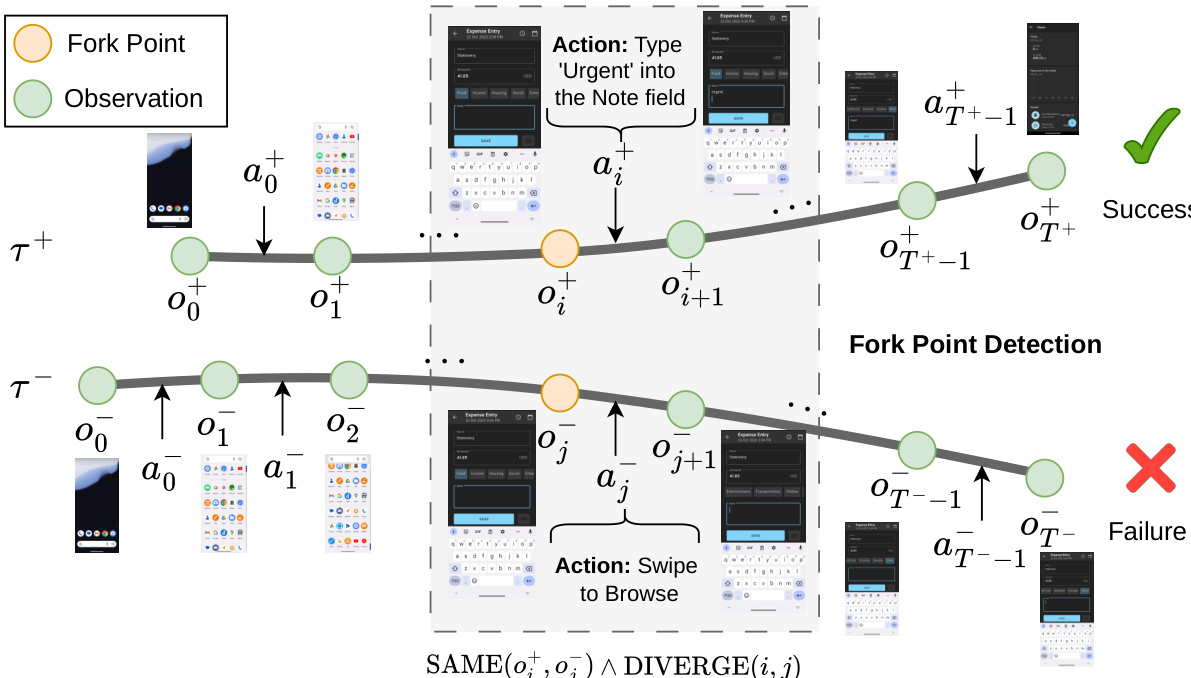
GRSD 的核心机制是分叉点检测。给定一条成功轨迹 τ+和一条失败轨迹 τ−,系统搜索智能体观察到相同屏幕状态但采取不同操作的步骤。为了确定状态等价性,作者对预处理后的截图使用了结构相似性指数(SSIM)。如果在成功轨迹中存在步骤 i,使得观测值匹配(记为 SAME(oi+,oj−)),但后续转移发生分歧(记为 DIVERGE(i,j)),则在失败轨迹的步骤 j 处识别出分叉点。
一旦识别出分叉点,模型将进行步骤级自蒸馏。对于每一对匹配项,构建训练样本时使用失败轨迹的上下文和成功轨迹中的正确操作作为目标。训练目标是最小化这些构建样本上的自回归下一个 token 预测损失:
LGRSD=−∣D∣1x∈D∑Tx1t=1∑Txlogπθ(yt∣s1,…,spx,y<t),其中 D 表示源自分叉点的样本集。这种方法有效地将稀疏反馈转化为精确的校正信号,使智能体能够从自身错误中学习,而无需外部教师策略。
实验
- 在 AndroidWorld 基准测试上的评估表明,UI-Voyager 的表现优于多种基线模型,包括专用 GUI 智能体和大规模专有模型,同时仅用 4B 参数就超越了报告的人类水平成功率。
- 拒绝微调(RFT)被验证为一种关键的初始化策略,它提供了持续的性能提升并作为高效的预热启动,而直接从基础模型应用标准 RL 算法(如 GRPO 和 PPO)仅带来边际改进且样本效率低下。
- 分叉点检测有效地识别了成功与失败轨迹之间的关键分歧时刻,使系统能够提供稠密的步骤级监督,并在长视野任务的关键决策点纠正错误操作。
- GRSD 框架利用自蒸馏将失败轨迹转化为高质量的监督数据,通过解决信用分配挑战并促进快速错误修正,在稀疏奖励环境中显著优于标准 RL 基线。
- 对实时执行的分析强调,虽然基于 SSIM 的匹配是有效的,但它面临时间错位和瞬态视觉扰动的挑战,这表明未来可通过时间感知匹配和去噪技术进行改进。