Command Palette
Search for a command to run...
CUA-Suite:面向计算机使用 Agent 的大规模人工标注视频演示数据集
CUA-Suite:面向计算机使用 Agent 的大规模人工标注视频演示数据集
Xiangru Jian Shravan Nayak Kevin Qinghong Lin Aarash Feizi Kaixin Li Patrice Bechard Spandana Gella Sai Rajeswar
摘要
计算机使用代理(CUAs)在自动化复杂桌面工作流方面展现出巨大潜力,然而,迈向通用型代理的进程却受限于连续、高质量人类演示视频的稀缺。近期研究强调,连续视频而非稀疏截图,才是扩展此类代理能力的关键缺失要素。然而,目前最大的开源数据集 ScaleCUA 仅包含 200 万张截图,相当于不足 20 小时的视频内容。为突破这一瓶颈,我们推出了 CUA-Suite——一个面向专业桌面计算机使用代理的大规模专家演示视频与稠密标注生态系统。其核心组件 VideoCUA 提供了约 10,000 个由人类演示的任务,涵盖 87 种多样化应用程序,包含连续 30 fps 的屏幕录制、运动光标轨迹以及多层推理标注,总计约 55 小时、600 万帧专家级视频数据。与仅记录最终点击坐标的稀疏数据集不同,这些连续视频流完整保留了人类交互的时序动态,构成了可无损转换为现有代理框架所需格式的信息超集。此外,CUA-Suite 还提供两项互补资源:UI-Vision,一个用于严格评估 CUA 在 grounding(定位)与规划能力的基准测试;以及 GroundCUA,一个包含 56,000 张标注截图和超过 360 万个 UI 元素标注的大规模 grounding 数据集。初步评估显示,当前的基础动作模型在处理专业桌面应用程序时表现显著不足(任务失败率约 60%)。除评估功能外,CUA-Suite 丰富的多模态语料还支持新兴研究方向,包括通用型屏幕解析、连续空间控制、基于视频奖励建模以及视觉世界模型等。所有数据与模型均已公开释放。
一句话总结
ServiceNow、Mila 及其他机构的研究人员推出了 CUA-SUITE,这是一个大型生态系统,包含 VIDEOCUA。该生态提供连续 30 fps 的屏幕录制和密集推理标注,旨在解决训练通用计算机使用代理所需的高质量人类演示数据稀缺的问题。
主要贡献
- 本文介绍了 VIDEOCUA,这是一个包含约 55 小时连续 30 fps 专家视频录制的大型语料库,涵盖 87 款桌面应用中的 10,000 个任务。该语料库富含运动学光标轨迹和多层推理标注,以保留完整的时间动态。
- 本工作将连续视频演示、来自 GROUNDCUA 的像素级 UI 定位数据以及名为 UI-VISION 的严格评估基准统一整合到 CUA-SUITE 生态系统中,为计算机使用代理的训练和测试提供密集、因果的监督信号。
- 与 CUA-SUITE 框架相关的所有基准、训练数据和模型均已作为开源资源发布,以支持通用屏幕解析、连续空间控制和视觉世界模型等新兴研究方向。
引言
计算机使用代理旨在将数字工具转变为能够导航复杂界面并执行工作流的活跃协作者,然而当前模型在处理专业桌面应用时仍显得脆弱。以往解决这一问题的努力依赖于自动生成的数据(引入噪声)或基于稀疏截图的数据集(缺乏学习平滑光标移动和长视野规划所需的时间连续性)。为了克服这些限制,作者推出了 CUA-SUITE,这是一个综合生态系统,将 55 小时的高保真专家视频演示、像素级 UI 标注以及严格的评估基准统一起来。该资源在 87 款应用中提供了密集、因果的监督,使得训练基础动作模型成为可能,这些模型能够掌握真实软件环境中的连续空间控制和复杂推理。
数据集
-
数据集构成与来源
- 作者推出了 CUA-SUITE,这是一个基于 87 种不同开源桌面应用的高保真人类演示构建的统一生态系统。
- 该套件包含三个互补资源:用于连续视频训练的 VIDEOCUA、用于细粒度 UI 定位的 GROUNDCUA,以及用于评估视觉感知和规划的 UI-VISION 基准。
- 数据收集涉及约 70 名专业标注员,他们设计并执行了超过 10,000 个专家任务,范围从简单操作到复杂工作流。
-
各子集的关键细节
- VIDEOCUA:包含约 55 小时的连续 30 fps 视频(600 万帧),涵盖 10,000 个任务。其中包括同步的运动学光标轨迹和多层推理标注,平均每步 497 个单词。
- GROUNDCUA:一个源自视频数据的训练语料库,包含 56,000 张带标注的截图和超过 360 万个 UI 元素标注。其中 50% 的元素包含边界框、文本标签和功能类别。
- UI-VISION:一个基准数据集,由 450 个高质量任务演示组成,旨在评估元素定位、布局定位和动作预测能力。
-
数据使用与处理
- 作者利用 VIDEOCUA 作为训练通用计算机使用代理的高质量扩展数据,确保与 OpenCUA 和 ScaleCUA 等现有框架兼容。
- 多层推理标注是使用 Claude-Sonnet-4.5 合成的,为每个轨迹步骤生成观察、思维链、动作描述和反思层。
- GROUNDCUA 支持两阶段训练方案,包括监督微调(SFT) followed by 强化学习(RL),用于训练如 GROUND-NEXT 等高效的视觉 - 语言模型。
- UI-VISION 作为主要的评估指标,用于诊断视觉定位和规划中的瓶颈,揭示空间推理仍是当前模型的重大挑战。
-
裁剪、元数据与标注策略
- 关键帧是从连续视频流中提取的,专门选取在改变状态的用户操作发生前的瞬间,以捕捉决策上下文。
- 标注员手动标记这些关键帧中每个可见的 UI 元素,添加边界框,并为长文本段落提供文本标签或简洁摘要。
- 应用 PaddleOCR 进行 OCR 处理,以提取源代码等长内容的原始文本,作为手动摘要的补充。
- 该数据集保留了完整的时间动态和中间光标移动,允许无损转换为各种代理训练格式,如截图 - 动作对或连续运动学轨迹。
方法
作者提出了 CUA-Suite,这是一个统一的框架,旨在通过大规模软件覆盖和密集统一标注来促进通用计算机使用代理的开发。该架构将严格的数据创建流程与用于视觉理解和轨迹建模的专用模块相结合。
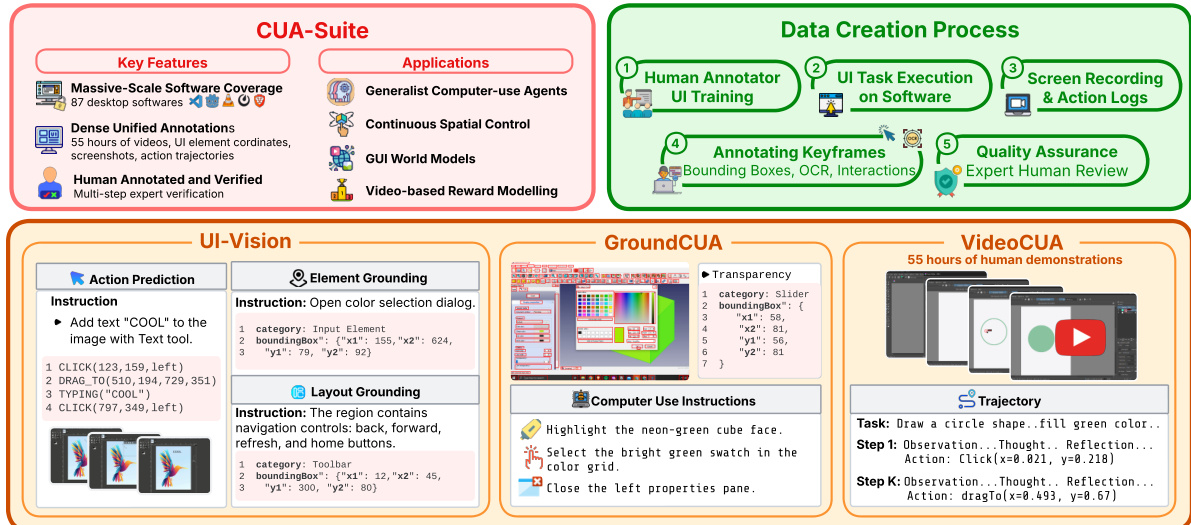
数据创建过程分为五个连续阶段。首先进行人类标注员 UI 培训以建立基准熟练度,随后在目标软件上执行 UI 任务。在执行过程中,捕获屏幕录制和动作日志。标注员随后通过添加边界框、OCR 数据和交互细节来标注关键帧,处理这些日志。流程最后以质量保证结束,由专家人工审查验证标注。
该套件包含三个核心组件。UI-Vision 处理动作预测、元素定位和布局定位,使代理能够解释界面元素并预测空间坐标。GroundCUA 专注于计算机使用指令,提供如高亮特定 UI 区域或选择颜色样本等任务的示例。VideoCUA 利用 55 小时的人类演示来建模轨迹,将任务分解为包含观察、思考、反思和动作的步骤。
为了确保稳健的评估并防止有关光标位置的信息泄露,作者采用了特定的预处理策略。关键帧提取在连续动作之间的时间中点执行。对于时间戳为 τt 的动作 at,关键帧在 (τt−1+τt)/2 处捕获。这确保了光标尚未到达目标位置,从而对空间定位提供更公平的评估。此外,作者实施了 moveTo 处理,将 moveTo 步骤排除在评估和动作历史之外,因为这些是预备性移动。对于直接跟随 moveTo 的 click 动作,使用 moveTo 步骤的关键帧而不是 click 步骤的关键帧,以避免揭示目标位置。
实验
- 在 87 款桌面应用的 256 个任务上进行的动作预测实验证实,当前的基础模型难以处理复杂的多面板界面,即使模型规模从 7B 扩展到 32B 参数,准确率仍然有限。
- 定性分析显示,模型经常无法区分专业创意工具和基于画布的应用中视觉相似的元素,通常导致跨面板错误或错误的 UI 区域选择。
- 人工评估确认,虽然模型通常能识别正确的动作意图,但在空间定位方面缺乏精度,导致动作正确性与坐标准确性之间存在显著差距。
- 应用级分析表明,性能高度依赖于界面设计,与专业软件中发现的密集、非标准工具栏相比,类网页布局的成功率更高。
- Krita 和 GIMP 中的详细轨迹案例研究表明,代理可以成功执行涉及工具选择、形状创建和效果应用的多步骤工作流,但在复杂交互期间仍容易出现坐标错位和冗余动作。