Command Palette
Search for a command to run...
ClawKeeper:通过技能、插件与监视器实现 OpenClaw Agents 的全面安全防护
ClawKeeper:通过技能、插件与监视器实现 OpenClaw Agents 的全面安全防护
摘要
OpenClaw 已迅速确立其作为领先开源自主 Agent 运行时环境的地位,具备工具集成、本地文件访问及 Shell 命令执行等强大功能。然而,这些广泛的运行权限也引入了关键的安全漏洞,将模型错误转化为实质性的系统级威胁,例如敏感数据泄露、权限提升以及恶意第三方技能执行。目前,OpenClaw 生态系统的安全措施高度碎片化,仅针对 Agent 生命周期的孤立阶段进行防护,未能提供整体性保护。为弥补这一差距,我们提出了 ClawKeeper——一个实时安全框架,该框架在三个互补的架构层中集成了多维度的保护机制:(1) 基于技能(Skill-based)的保护在指令层运行,将结构化的安全策略直接注入 Agent 上下文,以强制执行特定环境的约束及跨平台边界。(2) 基于插件(Plugin-based)的保护作为内部运行时执行器,在整个执行流水线中提供配置加固、主动威胁检测及持续的行为监控。(3) 基于监控器(Watcher-based)的保护引入了一种新颖的、解耦的系统级安全中间件,持续验证 Agent 的状态演化。该机制能够在不与 Agent 内部逻辑耦合的前提下,实现实时执行干预,支持诸如中止高风险操作或强制人工确认等行动。我们认为,这种 Watcher 范式具有巨大潜力,有望成为构建下一代自主 Agent 系统安全基石。广泛的定性与定量评估证明了 ClawKeeper 在多样化威胁场景下的有效性与鲁棒性。我们已开源相关代码。
一句话总结
来自北京邮电大学和北京人工智能研究院的研究人员提出了 ClawKeeper,这是一个面向 OpenClaw 智能体的统一安全框架。该框架集成了技能、插件以及一种新颖的解耦 Watcher 模块,旨在实现对系统级威胁的实时自适应防御,同时解决安全性与实用性之间的权衡问题。
主要贡献
- 本文介绍了 ClawKeeper,这是一个实时安全框架,通过整合三个架构层面的多维度防护,解决了 OpenClaw 生态系统中安全措施碎片化的问题。这种统一的方法结合了指令级策略注入、运行时强制执行以及解耦的系统监控,为智能体的整个生命周期提供了全面覆盖。
- 提出了一种基于 Watcher 的新型保护机制,作为一种独立的外部中间件,用于验证智能体状态的演变,并实现无需耦合内部逻辑的实时干预。该设计将安全监督与任务执行分离,使系统能够阻止高风险操作或强制要求人工确认,从而避免了传统的安全性 - 实用性权衡。
- 广泛的定性和定量评估证明了该框架在多种威胁场景(包括敏感数据泄露和恶意技能执行)下的有效性和鲁棒性。研究证实,这种三层架构通过适应新兴威胁并提供持续的行为监控,优于现有的单点防御方案。
引言
随着像 OpenClaw 这样的自主智能体演变为具有直接访问本地文件和 shell 命令能力的类操作系统环境,它们引入了关键的安全风险,其中模型错误可能升级为数据泄露和权限滥用等系统级威胁。以往的安全措施存在覆盖碎片化的问题,仅针对孤立的生命周期阶段,同时还面临安全性与实用性的权衡、被动的事后分析以及无法适应智能体自我演化特性的静态防御机制等挑战。为了填补这些空白,作者提出了 ClawKeeper,这是一个统一的实时安全框架,整合了三个层面的多维度防护:指令级技能策略、运行时插件强制执行,以及一种新颖的解耦 Watcher 中间件,该中间件能够在不耦合智能体内部逻辑的情况下实现主动干预和监管分离。
数据集
- 作者构建了一个基准测试集以评估 CLAWKEEPER 的安全能力,该测试集包含七个安全任务类别,与 OWASP 智能体安全倡议及开源防御分类法保持一致。
- 这七个类别中的每一个都包含 20 个对抗性实例,平均分为 10 个简单示例和 10 个复杂示例。
- 人类标注员独立对每个实例进行评分,以确定防御是否成功,遵循 AgentSafetyBench 的评估协议。
- 该数据集作为系统化的评估工具而非训练语料,文中未提及用于模型开发的特定训练划分或混合比例。
- 每个类别的代表性示例和定义总结在论文的表 4 中。
方法
作者提出了 ClawKeeper,这是一个综合安全框架,旨在将三种互补的保护范式统一为面向 OpenClaw 生态系统的多层架构。该系统集成了基于技能的上下文强制、基于插件的运行时加固以及用于外部行为验证的独立 Watcher。请参阅框架图以概览这三个支柱如何汇聚成统一的安全核心。
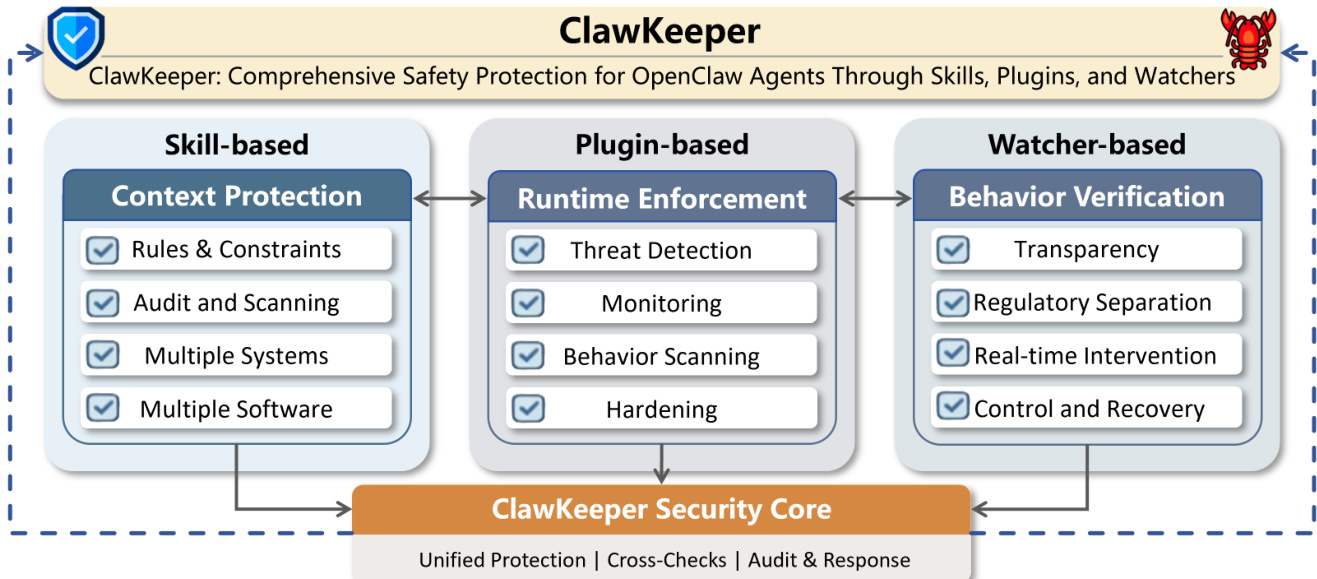
第一层是基于技能的防护,在智能体构建推理上下文时于指令层面运行。安全规则被定义为智能体可以直接解释和执行的结构化 Markdown 文档。这种设计允许在不修改底层框架的情况下进行低成本部署。该保护机制涵盖两个维度:针对 Windows 和 Linux 等不同操作系统的系统级约束,以及针对 Telegram 或飞书等通信平台的软件级约束。为了增强鲁棒性,该框架集成了检查脚本,执行定期的安全扫描和交互总结。如下图所示,这种方法允许策略在整个交互生命周期中持续应用。
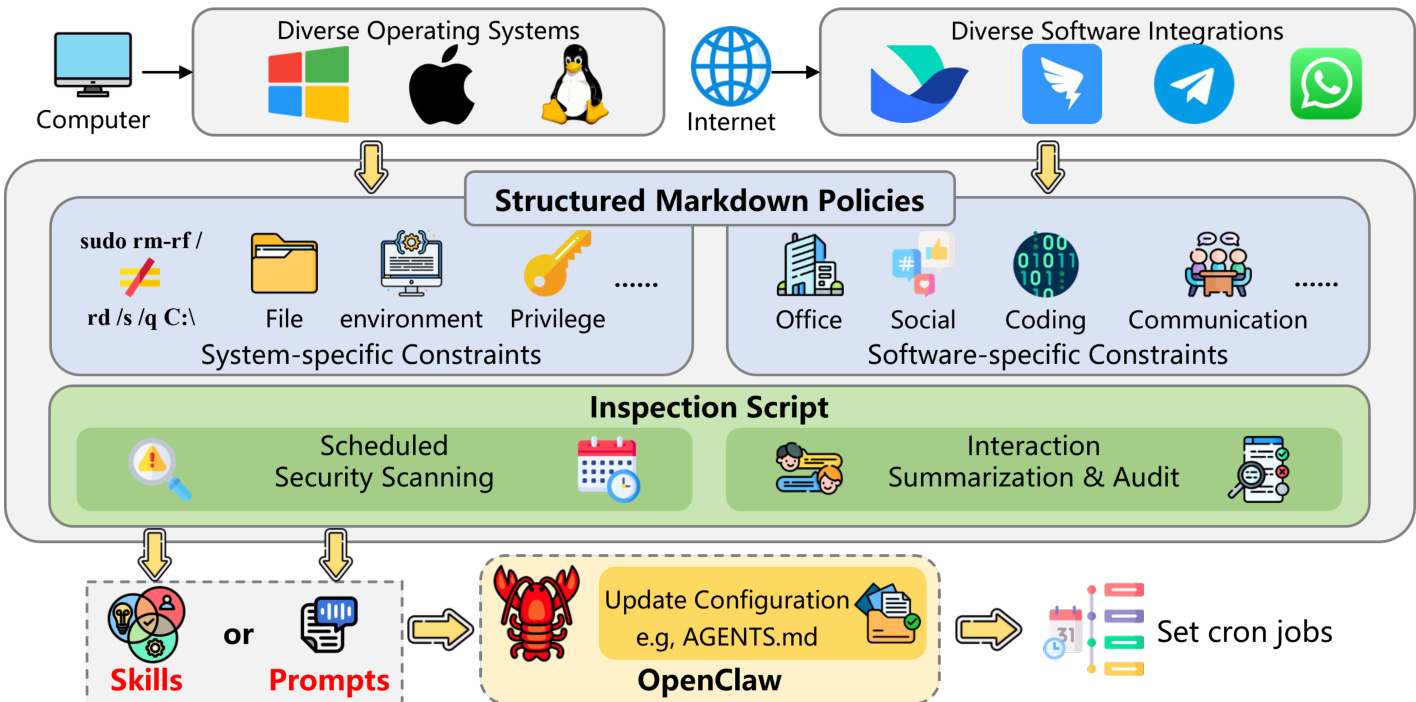
第二层是基于插件的防护,作为 OpenClaw 运行时内部的硬编码强制层。与提示级防御不同,该模块提供对系统行为的直接控制,以确保全面的安全覆盖。该插件充当全面的安全审计员、扫描器和加固执行器。它执行详细的威胁检测,以识别符合 OWASP 智能体安全指南的错误配置和已知漏洞。为了维护完整性,配置保护模块会生成关键操作文件的加密哈希备份。此外,行为扫描机制分析历史执行流,以检测潜在的威胁模式,如提示注入或危险命令。下图展示了包括威胁检测、配置保护、监控、行为扫描和加固在内的具体模块。
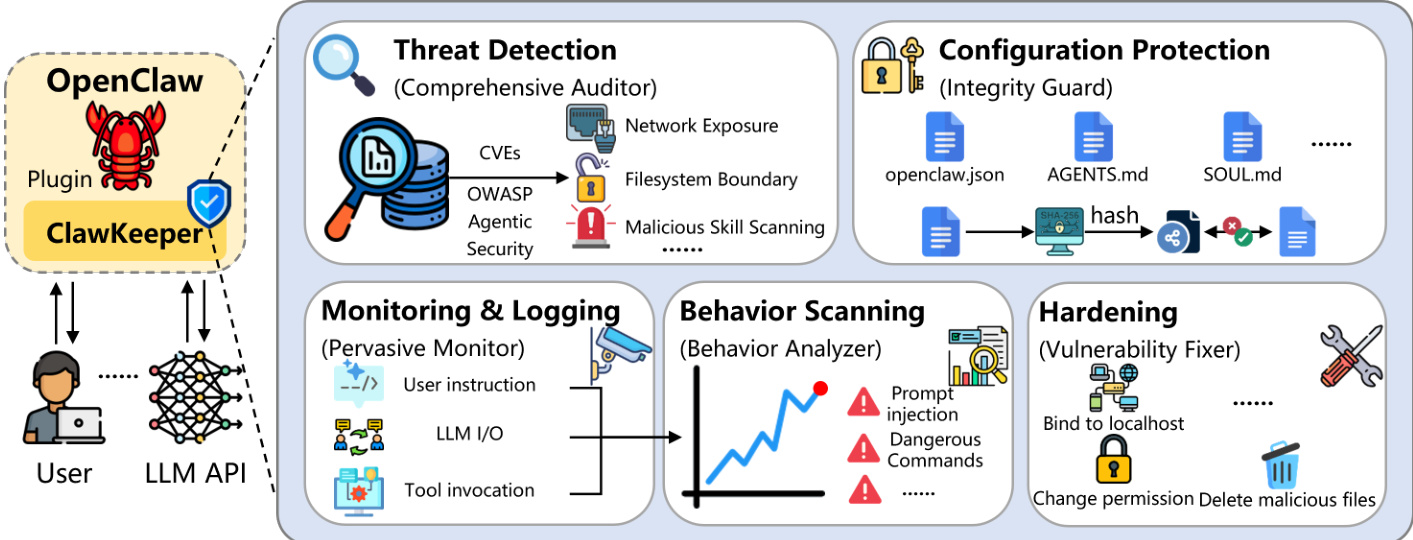
第三层是基于 Watcher 的防护,引入一个独立的外部智能体作为专用的安全审计员。这种解耦架构通过将任务执行与安全强制分离,解决了紧密耦合的安全组件的局限性。Watcher 被实现为一个配备专用监控技能的独立 OpenClaw 实例。它通过持久的 WebSocket 连接与执行任务的智能体通信,以执行实时安全诊断。如果检测到潜在的不安全轨迹,Watcher 会向智能体发出信号以暂停并寻求用户确认。该框架支持灵活的部署配置,包括用于隐私敏感场景的本地部署和用于集中治理的云端部署。如下图所示,Watcher 在保持解耦设计的同时,提供了可观测性、触发感知和执行干预能力。
实验
- 与七个开源基线的对比评估证实,CLAWKEEPER 的统一三层架构在所有七个安全任务类别中均实现了显著更高的防御成功率,而现有方法则存在严重的覆盖碎片化问题,且在其有限范围内仅表现出中等效果。
- 自我演化实验表明,Watcher 组件通过处理新的对抗性案例持续改进其防御能力,通过动态更新监控技能和风险阈值来提高成功率,这是静态插件或基于技能的方法所不具备的能力。
- 定性案例研究证实,基于技能的防护有效地在系统和软件边界强制执行上下文感知的安全协议,同时支持无需人工干预的自主定期自我审计。
- 基于插件的评估验证了加固模块通过向核心配置注入风险感知规则来防止敏感数据泄露,而集成的扫描器成功识别了潜在漏洞并提供了可操作的修复步骤。
- 基于 Watcher 的场景展示了系统实时拦截不安全行为的能力,包括阻止危险命令执行、停止过度的工具链调用,以及在上游故障后停止自动重试循环,从而强制执行严格的人机回环安全策略。