Command Palette
Search for a command to run...
GameplayQA:面向三维虚拟智能体决策密集型第一人称视角同步多视频理解的基准测试框架
GameplayQA:面向三维虚拟智能体决策密集型第一人称视角同步多视频理解的基准测试框架
Yunzhe Wang Runhui Xu Kexin Zheng Tianyi Zhang Jayavibhav Niranjan Kogundi Soham Hans Volkan Ustun
摘要
多模态大语言模型(Multimodal LLMs)正日益被部署为三维环境中自主智能体(autonomous agents)的感知骨干,应用场景涵盖从机器人技术到虚拟世界。此类应用要求智能体能够从第一人称视角感知快速的状态变化、将动作准确归因于相应实体,并对并发多智能体行为进行推理;然而,现有基准测试尚不足以充分评估上述能力。为此,我们提出了 GameplayQA,这是一个基于视频理解来评估以智能体为中心的感知与推理能力的框架。具体而言,我们在多人三维游戏视频中进行了密集标注,标注密度达到每秒 1.22 个标签;标注内容包含与时间同步的并发描述,涵盖状态、动作与事件,并围绕“自我(Self)”、“其他智能体(Other Agents)”与“世界(World)”这一三元系统构建,该结构天然契合多智能体环境的分解需求。基于这些标注,我们构建了 2,400 对诊断性问答(QA pairs),并将其划分为三个认知复杂度层级,同时配套了一套结构化的干扰项分类体系(distractor taxonomy),以支持对模型幻觉产生位置进行细粒度分析。对前沿多模态大语言模型(MLLMs)的评估结果显示,其表现与人类水平之间存在显著差距,常见失败案例包括时间定位与跨视频定位能力不足、智能体角色归因错误,以及难以应对游戏的高决策密度。我们期望 GameplayQA 能够激发未来在具身智能(embodied AI)、智能体感知与世界建模交叉领域的研究。
一句话总结
南加州大学的研究人员推出了 GAMEPLAYQA,这是一个新颖的基准测试,通过对多人 3D 游戏画面进行密集标注,以评估多模态大语言模型(LLM)在代理感知方面的能力。该框架独特地采用“自我 - 他人 - 世界”三元系统,揭示了先前基准测试所忽略的时间定位和代理归因方面的关键缺陷。
主要贡献
- 本文介绍了 GAMEPLAYQA,这是一个用于评估以代理为中心的感知和推理的框架。该框架以每秒 1.22 个标签的密度对多人 3D 游戏视频进行标注,并生成与时间同步的说明文本,其结构围绕“自我”、“其他代理”和“世界”的三元系统展开。
- 这项工作提出了 2.4K 个诊断性问答对,按三个认知复杂度层级组织,并设计了结构化的干扰项分类法,旨在实现对模型幻觉发生位置的细粒度分析。
- 实验表明,前沿多模态大语言模型(MLLM)与人类基准之间存在显著的性能差距,揭示了模型在时间定位、代理角色归因以及处理游戏环境高决策密度方面的具体缺陷。
引言
多模态大语言模型正越来越多地作为自主代理在 3D 环境(如机器人和虚拟世界)中的感知骨干,在这些环境中,它们必须从第一人称视角跟踪快速的状态变化,并对并发多代理行为进行推理。现有的基准测试无法评估这些能力,因为它们依赖于缓慢、被动的观察,缺乏现实世界代理所需的高频决策循环和密集具身化。为了填补这一空白,作者推出了 GAMEPLAYQA,这是一个对多人 3D 游戏视频进行密集标注的框架,其时间同步的说明文本围绕“自我”、“其他代理”和“世界”的三元系统构建。作者将这些标注细化为 2.4K 个诊断性问答对,按认知复杂度组织,并采用结构化的干扰项分类法,以 pinpoint 特定的失败模式,如时间定位错误和代理角色归因错误。
数据集
-
数据集构成与来源 作者推出了 GAMEPLAYQA,这是一个源自 9 款涵盖不同流派的商业多人游戏同步游戏画面的基准测试。数据来源包括 YouTube、Twitch 直播流以及现有数据集。对于多视角(multi-POV)场景,团队识别出在同一场比赛中游玩的主播群体,并手动对齐他们的独立录制内容,以创建时间同步的视频集。
-
每个子集的关键细节 最终基准测试包含 2,365 个高质量问答对,这些问答对由 2,709 个真实标签和 1,586 个干扰项标签生成,覆盖 2,219.41 秒的视频画面。数据围绕“自我 - 他人 - 世界”实体分解进行组织,涵盖六种基本类型:自我动作、自我状态、他人动作、他人状态、世界物体和世界事件。问题被分为三个认知层级:第 1 级用于基本感知,第 2 级用于时间推理,第 3 级用于跨视频理解。
-
数据使用与生成策略 作者采用基于组合模板的算法来生成数据集,最初生成 399,214 个候选对,随后下采样至 4,000 个以确保类别覆盖的平衡。该过程系统地结合了五个维度的已验证标签,包括视频数量、实体类型和干扰项类型。生成的基准测试用于评估 MLLM 在细粒度幻觉分析方面的表现,其中干扰项专门设计用于诊断词汇、时间、角色或跨视频推理方面的失败。
-
处理与标注工作流 该流程采用密集多轨道时间线标注方法,决策密度约为每秒 1.22 个标签。标注遵循两阶段的人机回环工作流,其中 Gemini-3-Pro 生成初始候选项,随后由研究生标注员进行验证和细化。该过程包括一个语言先验过滤步骤,移除无需视频输入即可解答的问题,随后进行人工评估以解决歧义并确保语义准确性。
方法
作者建立了一套结构化的游戏问答方法论,始于详细的问题分类法。请参阅分类法图表,该图表概述了定义每个问题的五个正交维度:视频数量、上下文目标、实体类型、干扰项和问题形式。这种层次结构允许系统地生成多样化的查询类型,范围从简单的识别到复杂的时间定位。
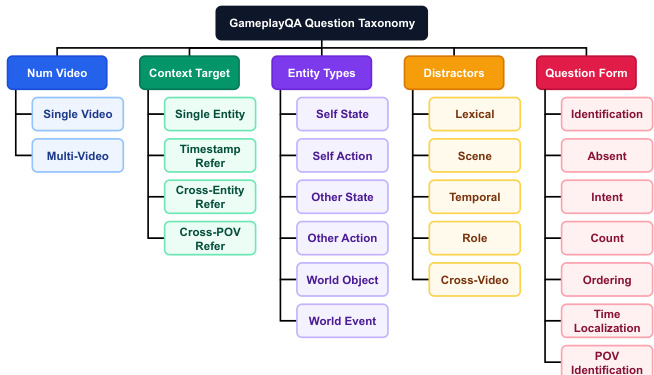
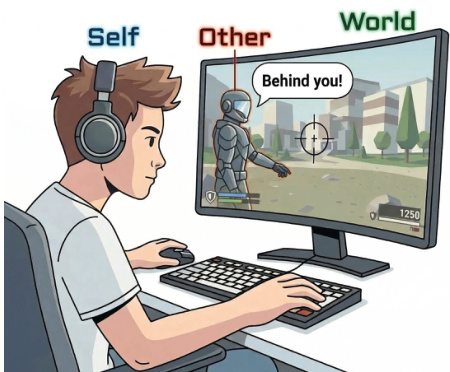
实体定义的核心是“自我 - 他人 - 世界”视角。如下图所示,该框架将实体分为三组:玩家(自我)、队友或 NPC(他人)以及游戏环境(世界)。这种三分法确保问题涵盖广泛的游戏互动和观察。
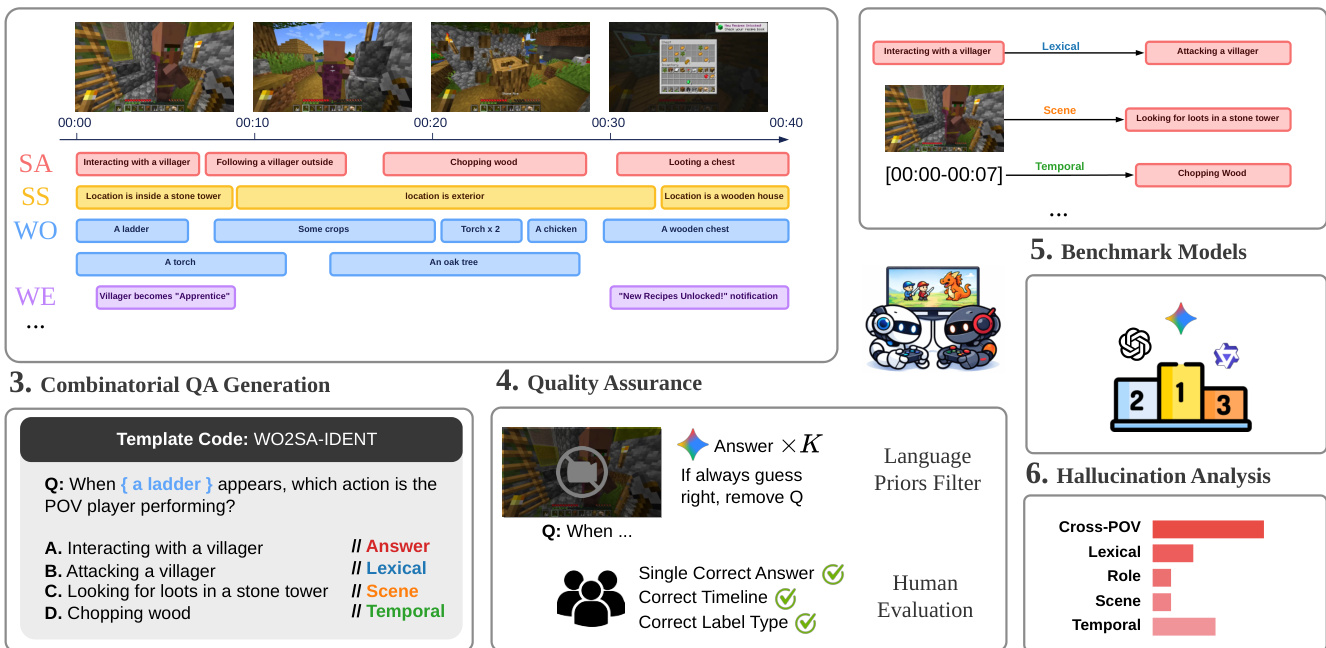
数据集构建采用组合式问答生成流程。请参阅生成流程图,该图详细说明了从时间事件标注到最终问题模板化的过程。系统提取语义片段(如自我动作和世界物体),然后应用模板代码来构建多项选择题。为了维护数据完整性,实施了严格的质量保证阶段。这包括自动化的语言先验过滤器,以消除无需视觉输入即可解答的问题,以及人工评估以验证答案键和时间线准确性。对于模型评估,作者利用大语言模型作为裁判(LLM as a Judge)来解析并提取模型原始输出中的选定选项,确保不同基准模型之间评分的一致性。
实验
- 在 GAMEPLAYQA 上对 16 个开源和专有 MLLM 的评估验证了三级认知层级,其中性能从基本感知到时间推理再到跨视频理解呈现一致的下降趋势。
- 实验确定了“出现次数”和“跨视频排序”是关键瓶颈,证实当前架构在持续时间注意力和对齐多视角事件方面存在困难。
- 错误分析显示,模型处理静态视觉输入的效果优于处理时间或跨视频干扰项,在快节奏、高决策密度的环境以及跟踪其他代理时,性能显著下降。
- 消融研究表明,真正的视觉定位对于任务成功至关重要,而时间排序对于高级推理任务尤为关键,但对于基本感知则相对次要。
- 在自动驾驶和人类协作数据集上的跨领域迁移实验证实,该基准框架可推广到现实世界的时空任务,同时保持了相对难度排名和模型性能趋势。