Command Palette
Search for a command to run...
WildWorld:面向生成式 ARPG 的、具备动作与显式状态的大规模动态世界建模数据集
WildWorld:面向生成式 ARPG 的、具备动作与显式状态的大规模动态世界建模数据集
Zhen Li Zian Meng Shuwei Shi Wenshuo Peng Yuwei Wu Bo Zheng Chuanhao Li Kaipeng Zhang
摘要
动力系统理论与强化学习将世界演化视为由动作驱动的潜在状态动力学过程,其中视觉观测仅提供关于状态的局部信息。近期的视频世界模型试图从数据中学习这种以动作为条件的动力学机制。然而,现有数据集往往难以满足该需求:它们通常缺乏多样化且具有语义意义的动作空间,且动作直接关联于视觉观测,而非通过底层状态进行中介。因此,动作常与像素级变化相互纠缠,导致模型难以学习结构化的世界动力学,并难以在长视界范围内维持一致的演化过程。本文提出 WildWorld,这是一个大规模、以动作为条件的世界建模数据集,包含显式的状态标注,数据自动采集自一款高保真 AAA 级动作角色扮演游戏《怪物猎人:荒野》(Monster Hunter: Wilds)。WildWorld 包含超过 1.08 亿帧图像,涵盖 450 余种动作(包括移动、攻击和技能释放),并同步提供每帧的角色骨骼、世界状态、相机位姿及深度图标注。基于该数据集,我们进一步构建了 WildBench,通过“动作跟随”(Action Following)与“状态对齐”(State Alignment)两项指标对模型进行评估。大量实验表明,当前模型在建模富含语义的动作以及维持长视界状态一致性方面仍面临持续挑战,凸显了发展具备状态感知能力的视频生成方法的迫切需求。项目主页:https://shandaai.github.io/wildworld-project/。
一句话总结
Alaya Studio 与多所大学的研究人员推出了 WildWorld,这是一个包含 1.08 亿帧的《怪物猎人:荒野》(Monster Hunter: Wilds)数据集,该数据集提供了明确的状态标注,旨在克服现有视频模型在长程一致性和语义丰富动作空间方面存在的局限性。
主要贡献
- 本文介绍了 WildWorld,这是一个从写实级 3A 游戏中收集的大规模视频数据集,包含超过 1.08 亿帧数据。该数据集提供了玩家动作、角色骨骼、世界状态、相机姿态和深度图的明确真值标注,以支持状态感知的世界建模。
- 本研究提出了 WildBench,这是一个专为评估交互式世界模型而设计的基准测试,包含两个特定指标:“动作跟随”(Action Following)用于衡量与真值子动作的一致性,“状态对齐”(State Alignment)用于通过骨骼关键点量化状态转换的准确性。
- 在 WildBench 上进行的广泛实验将基线模型与现有方法进行了对比,揭示了当前在状态转换建模方面的局限性,并为改进生成式 ARPG 环境中的长程一致性提供了见解。
引言
理解世界的演变对于构建具备长程规划和推理能力的 AI 智能体至关重要,然而现有方法因依赖动作语义有限且缺乏明确状态信息的数据集而举步维艰。先前的工作通常将动作视为直接的视觉变化,或从含噪观测中隐式推断潜在状态,这无法捕捉如弹药数量等驱动未来结果的关键内部变量。为弥补这些不足,作者推出了 WildWorld,这是一个来自写实级游戏的大规模数据集,包含超过 1.08 亿帧,提供了动作、骨骼和世界状态的明确真值标注。此外,他们还提出了 WildBench,这是一个包含“动作跟随”和“状态对齐”指标的新基准,旨在严格评估模型在多大程度上能将状态转换与视觉变化解耦,并随时间保持一致性。
数据集
-
数据集构成与来源:作者推出了 WildWorld,这是一个从 3A 动作角色扮演游戏《怪物猎人:荒野》(Monster Hunter: Wilds)中自动收集的大规模数据集。该数据集包含超过 1.08 亿帧,涵盖 450 多种不同的动作,包括移动、攻击和技能释放。数据捕捉了 29 种怪物、4 名玩家角色和 4 种武器类型在 5 个不同环境阶段中的多样化交互。
-
各子集的关键细节:
- 观测数据:包含 RGB 帧、无损深度图以及同步的相机姿态(内参和外参)。
- 状态与动作:提供明确的真值数据,如角色骨骼、绝对位置、旋转、速度、动画 ID,以及生命值和耐力等游戏属性。
- 标注:每帧包含 119 个标注列,包括由大型语言模型生成的细粒度动作级描述和样本级摘要。
- WildBench:一个衍生基准子集,包含 200 个人工精选样本,旨在评估动作跟随和状态对齐,涵盖合作战斗和一对一战斗场景。
-
数据使用与处理:
- 采集流程:作者利用自动化的游戏系统,该系统可导航菜单并利用基于规则的同伴 AI,在无人为干预的情况下生成多样化的战斗和移动轨迹。
- 同步机制:基于 OBS Studio 和 Reshade 的自定义录制系统同时捕获 RGB 和深度流,并嵌入时间戳以对齐来自多个源的数据。
- 训练应用:该数据集通过提供结构化的状态动态而非仅依赖视觉观测,支持训练动作条件化的世界模型。
-
过滤与构建策略:
- 质量过滤器:作者应用多维过滤器以剔除低质量样本,包括丢弃短于 81 帧的片段、消除超过 50 毫秒的时间间隔,以及移除具有极端亮度水平的序列。
- 遮挡处理:排除存在相机遮挡(通过弹簧臂收缩检测)或严重角色重叠(投影面积超过 30%)的样本,以确保视觉清晰度。
- 描述生成:通过将样本分割为动作序列、以 1 FPS 采样帧,并利用视觉 - 语言模型生成包含动作和状态真值的详细描述,从而创建分层描述。
- 视觉清理:该流程禁用了 HUD 着色器,以生成干净的无 HUD 帧,更好地反映游戏世界以用于模型训练。
方法
作者通过专为高保真录制设计的自动化游戏系统建立了坚实的数据基础。请参阅框架图。该系统采用嵌入时间戳的录制机制,确保多个数据流之间的逐帧同步。数据采集平台捕获多种模态,包括相机姿态、位置、旋转、速度、动画 ID、健康状态和骨骼姿态。收集完成后,数据需经过严格的处理流程,包括时间戳对齐,以及针对异常帧和存在持续时间短、镜头切换、极端亮度或遮挡等问题的样本进行过滤。
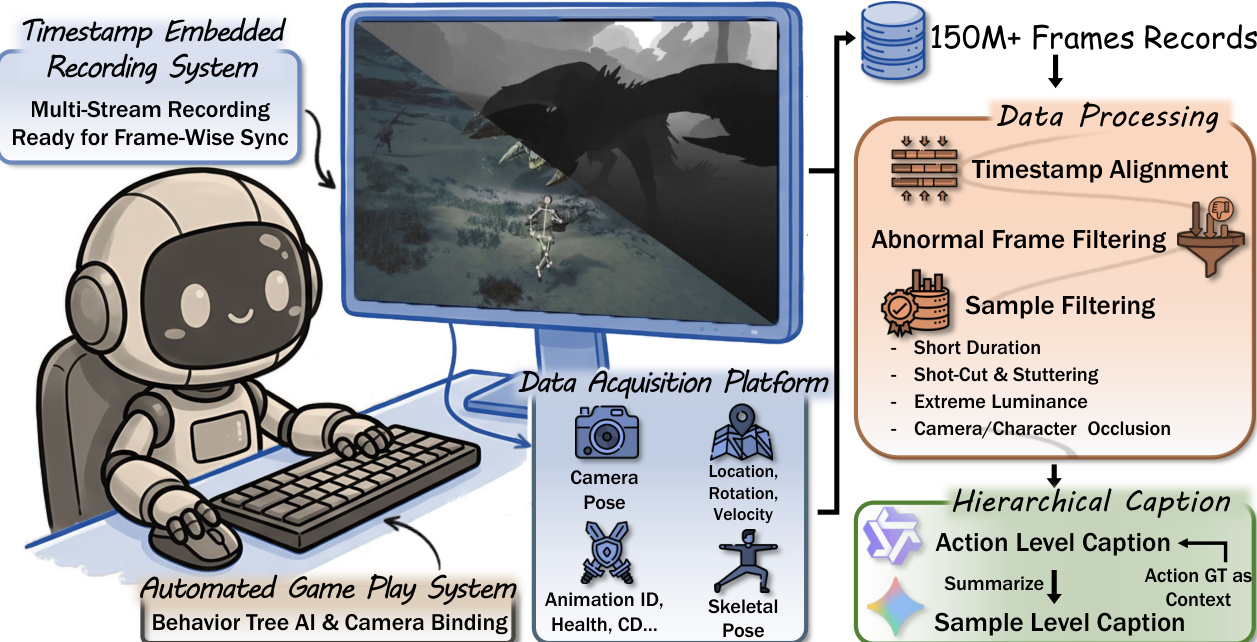
基于该数据集,作者开发了三种不同的视频生成方法。对于相机条件化生成,他们利用逐帧相机姿态的真值对 Wan2.2-Fun-5B-Control-Camera 模型进行微调,创建了 CamCtrl 模型。这与依赖离散动作基于规则转换的基线方法形成对比。对于骨骼条件化生成,引入了 SkelCtrl 模型。该方法利用在真值相机姿态下投影到屏幕坐标的逐帧 3D 骨骼关键点,渲染彩色骨骼视频作为 Wan2.2-Fun-5B-Control 模型的控制信号。
最全面的方法是状态条件化的 StateCtrl 模型。该架构将结构化的状态信息注入视频生成过程。状态被分为离散类型(如怪物类型和武器类别)和连续类型(如坐标和健康值)。离散状态通过可训练嵌入进行映射,而连续状态则使用 MLP 进行编码。作者采用分层建模策略,区分实体级状态(如记录时间)和全局级状态。Transformer 架构对实体间的关系进行建模,以生成统一的状态嵌入。该嵌入与视频帧对齐,并作为条件信号注入 DiT 的中间层。为了确保这些表示的质量,状态解码器从嵌入中恢复状态信息,状态预测器则预测下一帧的状态。在训练期间,应用解码器损失和预测器损失以保持状态保真度并增强时间一致性。在推理阶段,该模型支持基于第一帧真值状态(记为 StateCtrl-AR)的自回归后续状态预测。
所有模型均在 544×960 分辨率下训练,每个样本包含 81 帧,帧率为 16 FPS。训练过程使用批量大小为 1 和学习率为 1×10−5,运行 250,000 次迭代,并使用 Adam 优化器,批量大小为 8。在推理期间,系统保持相同的分辨率和帧率,同时采用 50 个采样步。
实验
- WildBench 基准测试通过评估视频质量、相机控制、动作跟随和状态对齐来验证交互式世界模型,使其区别于主要关注感知质量的现有基准。
- 可靠性实验证实,提出的“动作跟随”指标与人类判断的一致性达到 85%,而“状态对齐”指标有效衡量了生成状态与真值状态演变之间的一致性。
- 对比评估表明,在 WildWorld 数据集上训练的各种方法在交互相关指标上优于基线,证明了该数据集在改进相机控制和动作响应性方面的实用性。
- 分析显示,标准的视频质量指标(如 VBench)已趋于饱和,无法捕捉动态运动中的细微差异,而动作和状态指标提供了必要的细粒度评估。
- 定性发现表明存在一种权衡:使用视觉信号进行控制的模型实现了更好的交互保真度,但与使用学习嵌入的模型相比,其美学和图像质量有所下降。
- 关于自回归模型的实验显示出未来发展的潜力,但目前由于迭代状态预测中的误差累积,其动作跟随性能有所下降。