Command Palette
Search for a command to run...
SpecEyes:通过推测性感知与规划加速代理式多模态LLM
SpecEyes:通过推测性感知与规划加速代理式多模态LLM
Haoyu Huang Jinfa Huang Zhongwei Wan Xiawu Zheng Rongrong Ji Jiebo Luo
摘要
代理式多模态大语言模型(MLLMs)(例如 OpenAI o3 和 Gemini Agentic Vision)通过迭代式的视觉工具调用实现了卓越的推理能力。然而,级联的感知、推理与工具调用循环引入了显著的顺序开销。这种开销被称为“代理深度”(agentic depth),会导致难以接受的延迟,并严重限制系统级的并发能力。为此,我们提出了 SpecEyes,这是一种代理级的推测加速框架,旨在打破这一顺序瓶颈。我们的核心洞察在于:一个轻量级、无需调用工具的多模态大语言模型(MLLM)可作为推测性规划器来预测执行轨迹,从而在不牺牲准确性的前提下实现昂贵工具链的提前终止。为规范此类推测性规划,我们引入了一种基于答案可分离性(answer separability)的认知门控机制,该机制能够在无需真实标签(oracle labels)的情况下量化模型自我验证的置信度。此外,我们设计了一种异构并行漏斗结构,利用小模型的无状态并发特性来掩盖大模型的有状态串行执行,从而最大化系统吞吐量。在 V* Bench、HR-Bench 和 POPE 上的大量实验表明,SpecEyes 相比代理基线实现了 1.1 至 3.35 倍的加速,同时保持甚至提升了准确率(最高提升达 +6.7%),从而显著提升了并发负载下的服务吞吐量。
一句话总结
来自厦门大学、罗切斯特大学和俄亥俄州立大学的研究人员提出了 SpecEyes,这是一个agentic-level的推测加速框架。该框架采用一个轻量级、无需工具的 MLM 作为规划器来预测执行轨迹。通过认知门控和并行漏斗,该方法减少了多模态大语言模型中的顺序开销,在保持复杂推理基准测试准确性的同时实现了显著的速度提升。
主要贡献
- 本文介绍了 SpecEyes,这是一个agentic-level推测加速框架,它利用轻量级、无需工具的模型来预测执行轨迹,从而绕过那些不需要深度推理的查询所需的昂贵工具链。
- 提出了一种基于答案可分性(answer separability)的认知门控机制,用于量化模型的自我验证置信度,使得无需依赖 oracle 标签即可在小型推测模型和大型Agent模型之间可靠切换。
- 在 V* Bench、HR-Bench 和 POPE 上的实验表明,该方法相比Agent基线实现了 1.1 到 3.35 倍的速度提升,同时保持或提高了准确性,并在并发工作负载下提升了服务吞吐量。
引言
Agentic多模态大语言模型(MLLM)通过迭代调用视觉工具实现了卓越的推理能力,但这一过程引发了严重的效率危机:感知与推理步骤之间严格的数据依赖导致延迟激增,并阻碍了 GPU 批处理。先前的优化方法(如 token 级推测解码或 token 剪枝)未能解决这一问题,因为它们仅加速了固定串行工具使用循环内的单个步骤,而未质疑该循环本身的必要性。作者利用一个轻量级、无需工具的模型来推测那些不需要深度工具交互的查询的答案,从而提出了 SpecEyes,这是首个将推测加速从 token 级提升至agentic-level的框架。通过采用基于答案可分性的新型认知门控机制来验证置信度,并利用异构并行漏斗掩盖串行执行,SpecEyes 能够绕过简单查询的昂贵工具链,同时保持或提高准确性。
方法
作者将Agentic多模态大语言模型(MLLM)形式化为一个有状态推理系统,其中模型在多个推理步骤中维护状态轨迹。该系统的一个关键特性是,后续的工具选择在因果上依赖于先前的观察,从而形成了严格的数据依赖。这种依赖使得Agent流水线本质上具有顺序性,因为步骤 d+1 必须等到步骤 d 完成后才能开始。因此,单个查询的端到端延迟与Agent深度呈线性增长。
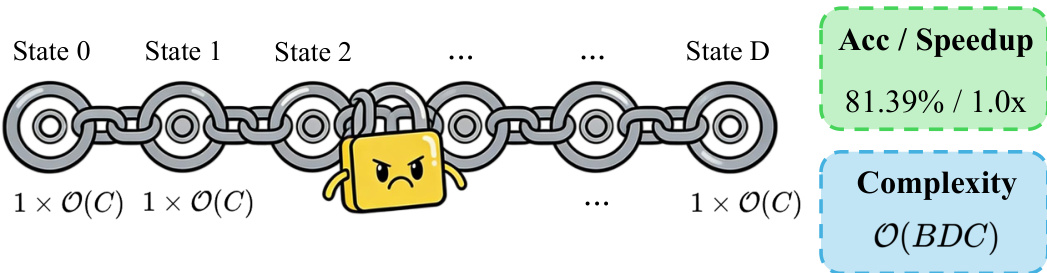
为了应对这一瓶颈,作者提出了 SpecEyes,这是一个四阶段推测加速框架,旨在当较小的非Agent模型具有足够置信度时,绕过昂贵的工具链。该流水线通过一个漏斗处理一批查询,将其分为无需工具和需要工具两条路径。
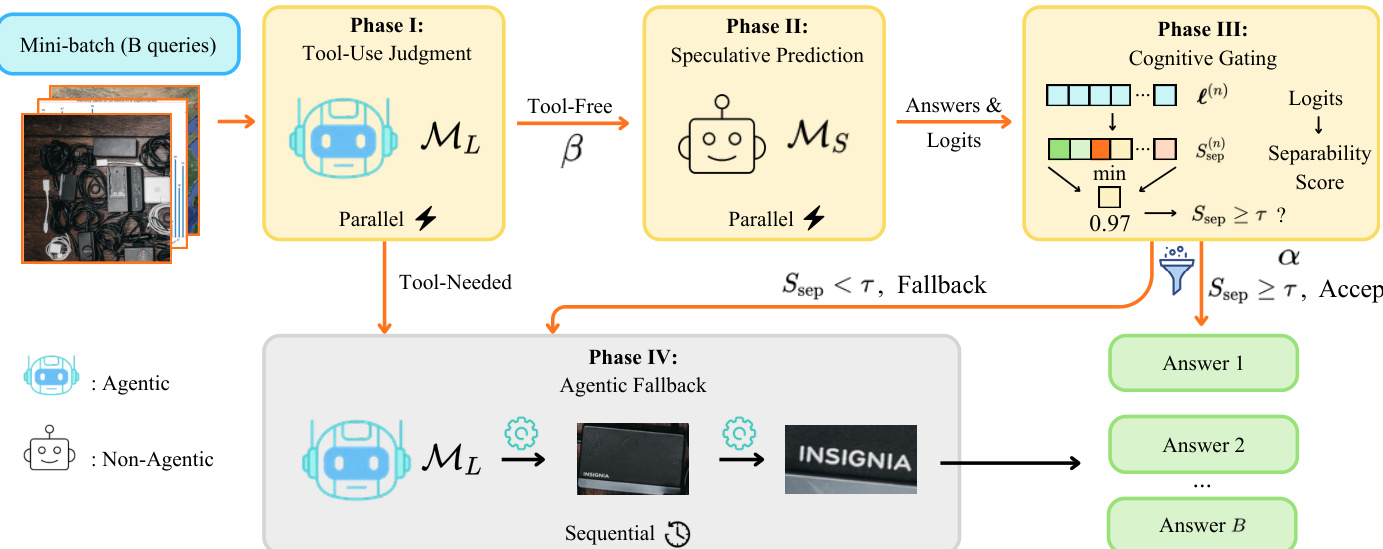
执行流程始于第一阶段:工具使用判断。大型Agent模型 ML 通过生成单个二元 token 来判断是否需要调用工具。被判定为无需工具的查询进入第二阶段:推测预测。在此阶段,小型无状态模型 MS 生成答案及完整的输出 logit 分布,无需执行任何工具。该推理过程针对批次中的所有查询并发执行。
在第三阶段:认知门控中,来自小型模型的 logits 被传递给一个门控函数,以量化答案置信度。作者引入了一个答案可分性分数 Ssep,用于衡量最高预测与其竞争者之间的决策边界,而不是依赖原始的 softmax 概率。如果该分数超过阈值 τ,则立即接受该答案。否则,查询将回退到第四阶段:Agent回退,此时完整的Agent模型 ML 将执行完整的有状态感知 - 推理循环。
除了降低单个查询的延迟外,该框架通过将各阶段组织成异构并行漏斗,实现了系统级的吞吐量提升。前端筛选和推测推理是无状态的且完全可并行批处理,而回退过程则保持串行。这种架构将无状态并发与有状态执行解耦,显著减少了需要承担完整Agent成本的查询数量。
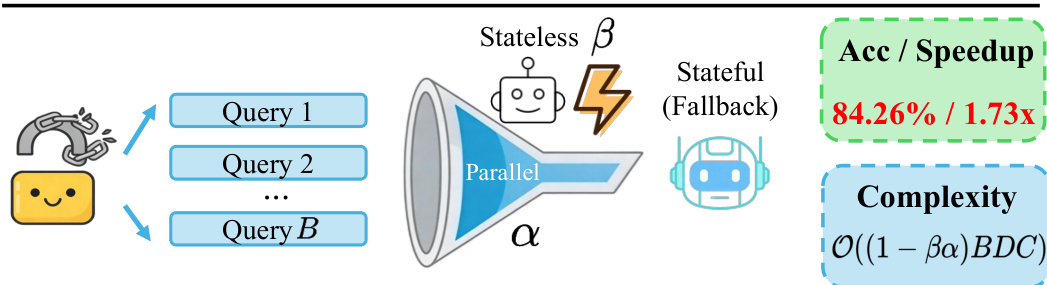
当筛选比率和门控接受率较高时,预期的单查询延迟主要由轻量级前端成本主导。由此产生的吞吐量加速比约为 1/(1−βα),其中 β 是无需工具的筛选比率,α 是认知门控接受率。该方法有效地将单查询延迟节省转化为系统级吞吐量提升,同时保持了与Agent基线相当的准确性。
实验
- 在 V*、HR-Bench 和 POPE 基准测试上的实验验证,与Agent基线相比,SpecEyes 在提高或保持准确性的同时实现了显著的速度提升,其中在减少幻觉和空间推理任务中观察到了最显著的增益。
- 定性分析证实,最小 token 置信度聚合策略通过有效区分正确与错误答案,提供了最佳的精度 - 速度权衡,而其他聚合方法则因分布重叠而表现不佳。
- 消融研究表明,门控阈值是平衡效率与性能的稳健控制旋钮,而更大的服务批次大小通过摊销无状态推测阶段提高了吞吐量,且不影响模型准确性。
- 结果表明,SpecEyes 在不同的Agent骨干网络上具有良好的泛化能力,并优于那些产生高 token 开销的替代推测方法,尽管由于频繁需要工具辅助检查,高分辨率任务仍然是一个瓶颈。