Command Palette
Search for a command to run...
EVA:面向端到端视频 Agent 的高效强化学习
EVA:面向端到端视频 Agent 的高效强化学习
Yaolun Zhang Ruohui Wang Jiahao Wang Yepeng Tang Xuanyu Zheng Haonan Duan Hao Lu Hanming Deng Lewei Lu
摘要
利用多模态大语言模型(MLLMs)进行视频理解仍面临严峻挑战,主要原因在于视频数据包含极长的 token 序列,其中蕴含复杂的时序依赖关系及大量冗余帧。现有方法通常将 MLLMs 视为被动的识别器,直接处理完整视频或均匀采样的帧,缺乏自适应推理能力。近期基于 Agent 的方法虽然引入了外部工具,但仍依赖于人工设计的工作流和“感知优先”策略,导致在处理长视频时效率低下。为此,我们提出了 EVA(Efficient Video Agent,高效端到端视频 Agent),这是一种基于强化学习的框架。EVA 通过迭代式的“总结 - 规划 - 行动 - 反思”推理机制,实现了“先规划后感知”的范式。该框架能够自主决策观看内容、观看时机及观看方式,从而实现以查询驱动的高效视频理解。为训练此类 Agent,我们设计了一套简洁而有效的三阶段学习 pipeline,包含监督微调(SFT)、Kahneman-Tversky 优化(KTO)以及广义奖励策略优化(GRPO),成功桥接了监督模仿学习与强化学习。此外,我们为每个阶段构建了高质量数据集,以支持训练过程的稳定性与可复现性。我们在六个视频理解 benchmark 上对 EVA 进行了评估,结果展示了其全面的能力。与现有基线相比,EVA 相较于通用 MLLM 基线实现了 6% 至 12% 的显著提升,相较于先前的自适应 Agent 方法也进一步提升了 1% 至 3%。我们的代码和模型已开源,地址为:https://github.com/wangruohui/EfficientVideoAgent。
一句话总结
商汤科技研究院的研究人员提出了 EVA,一种面向端到端视频智能体的高效强化学习框架,该框架将范式从被动识别转变为“先规划后感知”。通过利用结合 KTO 和 GRPO 的三阶段训练流程,EVA 能够自主选择视频片段以进行查询驱动的理解,在六个基准测试中超越了以往的自适应方法。
主要贡献
- 本文介绍了 EVA,一种用于端到端视频智能体的高效强化学习框架。该框架通过“总结 - 规划 - 行动 - 反思”的迭代推理机制实现“先规划后感知”,使智能体能够自主决定观看的内容、时机和方式。
- 设计了一个三阶段训练流程,通过结合监督微调、Kahneman-Tversky 优化(KTO)和广义奖励策略优化(GRPO),在监督模仿学习与强化学习之间架起桥梁,从而实现稳定且可扩展的策略学习。
- 构建了名为 EVA-SFT、EVA-KTO 和 EVA-RL 的高质量数据集以支持各个训练阶段。在六个基准测试上的评估表明,该方法相比通用多模态大语言模型(MLLM)基线提升了 6–12%,相比以往的自适应智能体方法提升了 1–3%。
引言
利用多模态大语言模型(MLLM)进行视频理解对于问答和检索等应用至关重要,但其在处理长视频固有的海量 token 序列和时间冗余方面仍面临挑战。以往的方法通常将 MLLM 视为被动识别器,处理均匀采样的帧,或依赖僵化的人工设计智能体工作流,导致感知效率低下且推理能力有限。为了解决这些挑战,作者提出了 EVA,一种高效的强化学习框架,转向“先规划后感知”的范式,智能体基于“总结 - 规划 - 行动 - 反思”的迭代循环,自主决定观看的内容、时机和方式。此外,作者开发了一个结合监督微调、Kahneman-Tversky 优化和广义奖励策略优化的三阶段训练流程,以稳定学习过程并在多个基准测试中实现最先进(SOTA)的性能。
数据集
-
数据集构成与来源 作者构建了一个多阶段数据集流程,起始于由 Qwen2.5-VL-72B 教师 MLLM 生成的合成智能体视频理解数据。基础的视频问答对来源于 llava-video(针对短视频)和 cgbench(针对长视频)。后续阶段融入了 HD-VILA 的数据,以确保模型接触未见过的视频内容。
-
各子集的关键细节
- SFT 子集:实例遵循“总结 + 规划 + 行动 + 反思”的格式。提示词包含“过往成功经验”、“多样化工作流提示”和“反思性思维提示”,以指导教师模型。
- KTO 子集:该集合包含源自 SFT 流程的单样本偏好标签。被拒绝的样本是由"LLM 作为裁判”识别出的缺乏视觉证据或纯属猜测的错误轨迹,而被选中的样本则是重采样的高质量成功轨迹。
- GRPO 子集:这个动态数据集始于 KTO 训练模型的失败案例。随后,教师 MLLM 基于这些失败案例生成新的开放式问答对,并从 HD-VILA 中采样进行增强。
-
模型使用与训练策略 作者采用三阶段训练方法。首先,基础模型经过监督微调(SFT)以学习工具调用格式和推理模式。其次,应用 Kahneman-Tversky 优化(KTO),利用偏好数据帮助模型区分成功与失败的策略。最后,实施数据增强的多阶段 GRPO 流程,模型从自身的失败中迭代学习,数据集由教师 MLLM 持续刷新,以防止对静态查询过拟合。
-
处理与元数据构建 SFT 数据构建明确将元数据结构化为四个阶段,以锚定视觉证据并估算行动成本。KTO 阶段根据推理质量而非对话轮次对数据进行过滤,以更好地适应多轮交互。对于 GRPO 阶段,作者避免使用多项选择题以防止奖励黑客行为,转而生成简洁的开放式答案。该流程还利用"LLM 作为裁判”对轨迹进行分类,并采用包含失败案例的上下文学习来指导新训练样本的生成。
方法
作者将主动视频理解问题形式化为马尔可夫决策过程(MDP)。在每个时间步 t,智能体观察信念状态 st={q,ht,Ft},其中 q 表示用户查询,ht 表示交错文本 - 帧历史,Ft 对应于通过工具调用获得的视觉证据。智能体的策略参数化为 πθ(at∣st)。区分该框架的核心理念是“先规划”范式,这与传统的“先感知”方法形成对比。如下图所示:
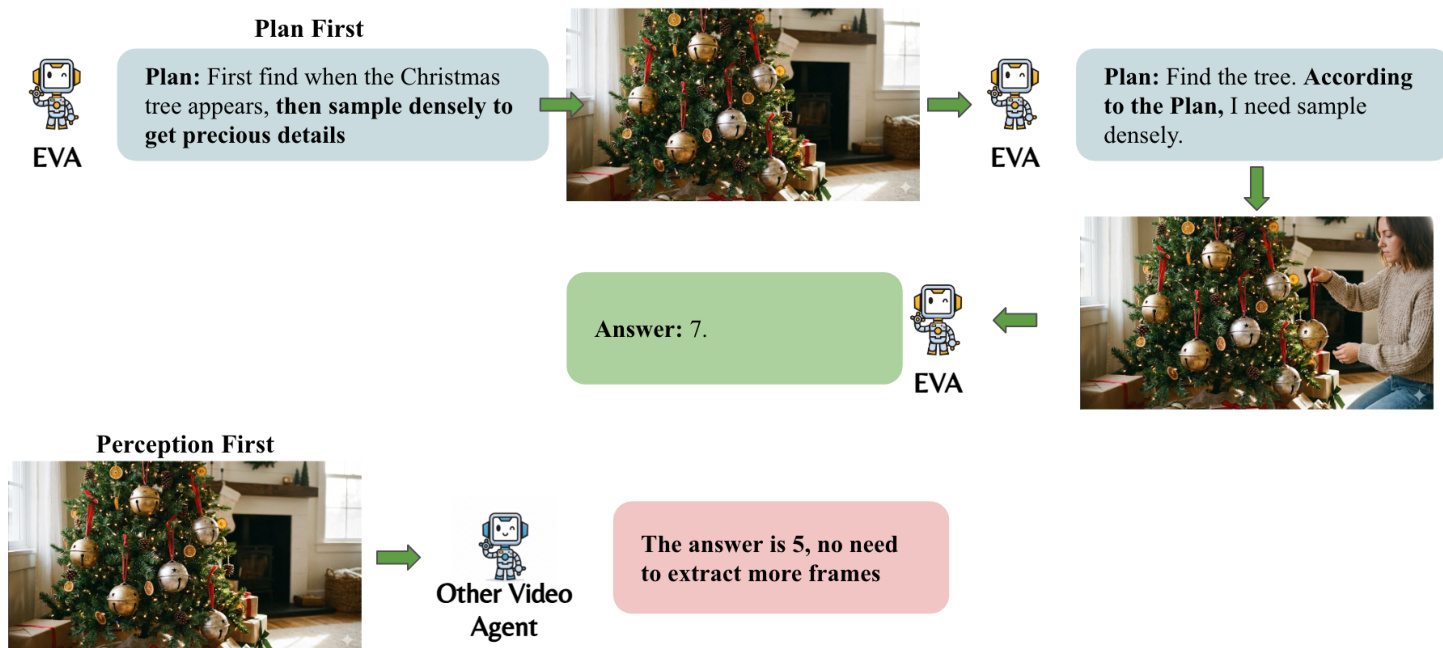 通过在观察视频之前制定计划,智能体避免了无关帧造成的视觉误导,并通过仅识别必要内容来节省视觉 token。
通过在观察视频之前制定计划,智能体避免了无关帧造成的视觉误导,并通过仅识别必要内容来节省视觉 token。
为了实现视觉 token 的自主规划,作者设计了一个灵活的帧选择工具,允许进行时间和空间控制。该工具模式包含 start_time、end_time、nframes 和 resize 等参数。参考框架图:
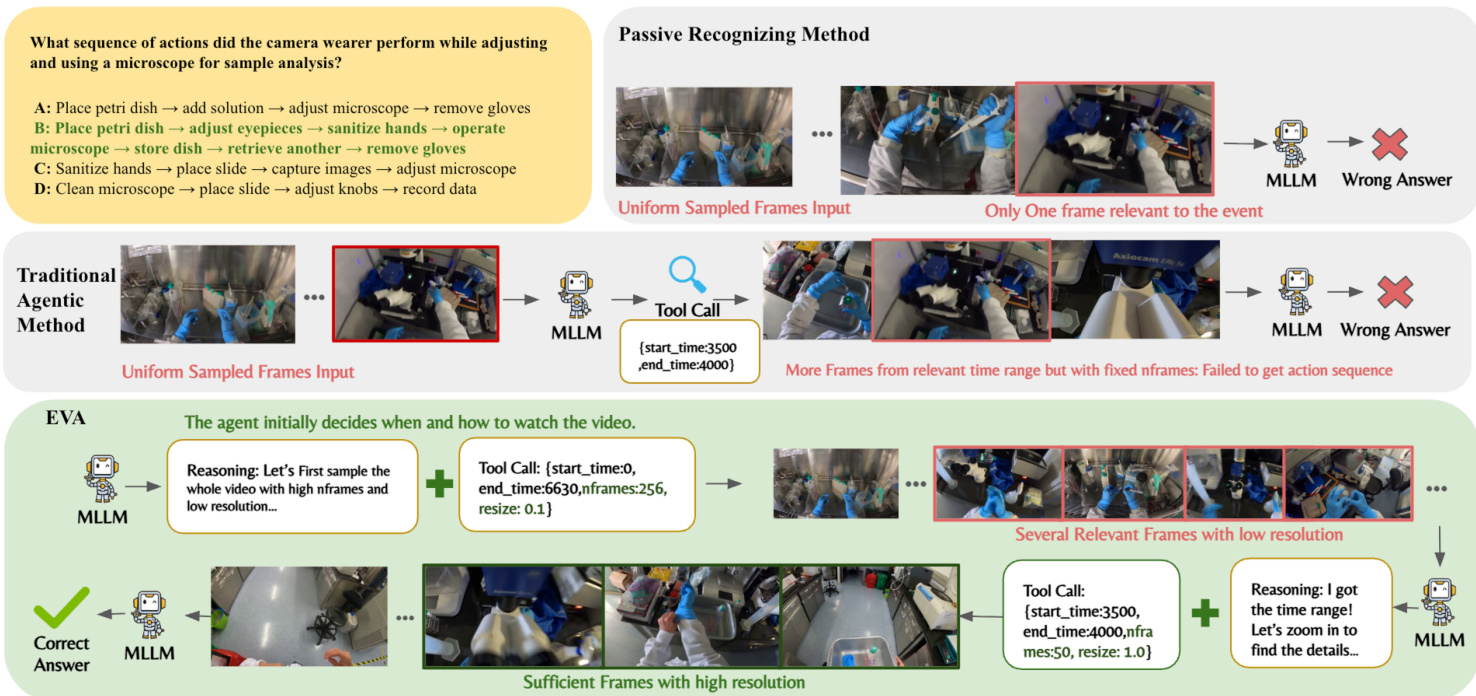 该工具提供了广阔的探索空间,鼓励智能体学习如何在多轮中分配时间和空间信息。智能体迭代推理并调用工具以检索特定帧,该过程涉及执行器(Executor)和反思思考者(Reflective Thinker)。此过程的数据生成流程如下图所示:
该工具提供了广阔的探索空间,鼓励智能体学习如何在多轮中分配时间和空间信息。智能体迭代推理并调用工具以检索特定帧,该过程涉及执行器(Executor)和反思思考者(Reflective Thinker)。此过程的数据生成流程如下图所示:
 成功的轨迹被归档到经验库(Experience Bank)中,以指导执行器在后续迭代中的操作。
成功的轨迹被归档到经验库(Experience Bank)中,以指导执行器在后续迭代中的操作。
训练过程包括三个阶段:监督微调(SFT)、离线学习和在线学习。如下图所示:
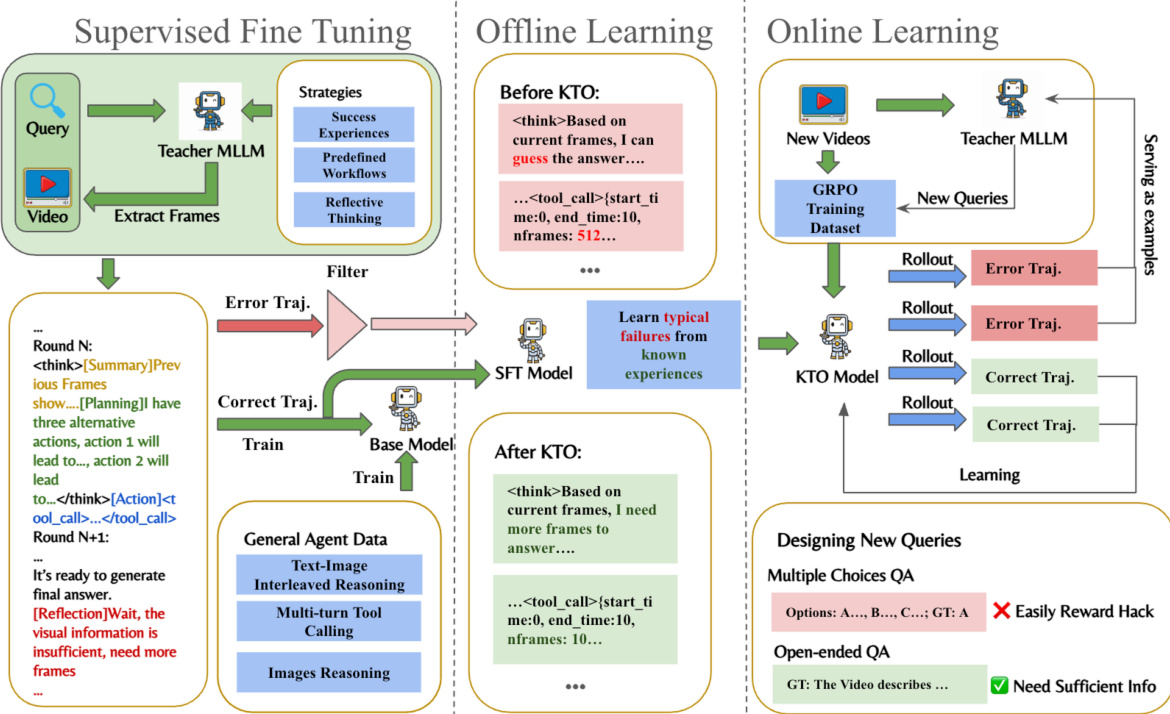 在 SFT 阶段,教师 MLLM 生成诸如成功经验和反思性思维等策略。离线学习利用 KTO 从典型失败中学习。在线学习采用带有复合奖励函数的组相对策略优化(GRPO)。该奖励函数结合了准确性奖励(多项选择题使用 CSV,开放式问题使用 ROUGE)和格式奖励,以防止模型在没有适当推理的情况下进行猜测。
在 SFT 阶段,教师 MLLM 生成诸如成功经验和反思性思维等策略。离线学习利用 KTO 从典型失败中学习。在线学习采用带有复合奖励函数的组相对策略优化(GRPO)。该奖励函数结合了准确性奖励(多项选择题使用 CSV,开放式问题使用 ROUGE)和格式奖励,以防止模型在没有适当推理的情况下进行猜测。
智能体推理和工具参数选择的示例如下所示:
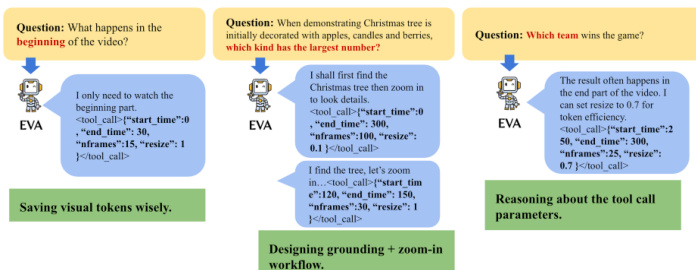 智能体展示了通过仅观看相关部分来节省视觉 token 的能力,设计了“定位 + 放大”的工作流,并能对工具调用参数进行推理。
智能体展示了通过仅观看相关部分来节省视觉 token 的能力,设计了“定位 + 放大”的工作流,并能对工具调用参数进行推理。
实验
- 在采样困境基准(Sampling Dilemma Bench)上的评估验证了 EVA 智能体通过迭代推理选择帧,有效平衡了视觉理解与效率,与密集采样基线相比,在显著减少视觉 token 的情况下实现了更高的准确率。
- 在长视频基准测试上的测试表明,“先规划后感知”范式使模型能够自适应地将注意力分配给相关片段,在最小化帧使用的情况下,在时间跨度较长的场景中保持高性能。
- 在 Video-Holmes 基准上的零样本评估证实了该模型在多步推理和因果理解方面具有强大的泛化能力,无需特定任务的监督。
- 消融研究表明,顺序的 SFT-KTO-GRPO 训练方案逐步将智能体从遵循格式的模仿者转变为战略探索者,而在 GRPO 期间混合开放式和多项选择题数据可防止奖励黑客行为,并确保基于视觉的推理。
- 效率分析显示,尽管进行了多轮规划,但由于推理时间主要由一组紧凑的自适应选择视觉 token 主导,而非推理步骤的数量,因此总计算量仍与均匀采样具有竞争力。
- 行为分析展示了智能体的自主决策过程,即它最初进行广泛探索,随后聚焦于特定片段以获取细粒度信息。
- 在 ELV-Halluc 基准上的性能表现突出了该模型通过精确定位时间戳并通过其智能体工具调用框架增强帧级感知,从而减少语义聚合幻觉的能力。