Command Palette
Search for a command to run...
T-MAP:基于轨迹感知的进化搜索对 LLM Agent 进行红队测试
T-MAP:基于轨迹感知的进化搜索对 LLM Agent 进行红队测试
Hyomin Lee Sangwoo Park Yumin Choi Sohyun An Seanie Lee Sung Ju Hwang
摘要
尽管先前的红队测试工作主要集中于诱导大型语言模型(LLMs)生成有害文本输出,但此类方法未能有效捕捉在多步工具执行过程中涌现的、具有代理(Agent)特异性的脆弱性,尤其是在模型上下文协议(Model Context Protocol, MCP)等快速发展的生态系统中。为填补这一空白,我们提出了一种轨迹感知的进化搜索方法——T-MAP。该方法利用执行轨迹(execution trajectories)来引导对抗性提示(adversarial prompts)的发现。我们的方法能够自动生成攻击,这些攻击不仅能绕过安全护栏,还能通过实际的工具交互可靠地实现有害目标。在多样化的 MCP 环境中的实证评估表明,T-MAP 在攻击实现率(Attack Realization Rate, ARR)上显著优于基线方法,并且对包括 GPT-5.2、Gemini-3-Pro、Qwen3.5 和 GLM-5 在内的前沿模型依然有效,从而揭示了自主 LLM Agent 中此前未被充分探索的脆弱性。
一句话总结
来自 KAIST、UCLA 和 DeepAuto.ai 的研究人员推出了 T-MAP,这是一种轨迹感知的进化搜索方法。该方法独特地利用执行轨迹来揭示模型上下文协议(MCP)中特定于代理的漏洞,在可靠绕过前沿大语言模型(LLM)的安全护栏方面,其表现优于现有的红队测试方法。
主要贡献
- 本文通过将攻击成功定义为通过实际工具执行而非仅靠文本生成来实现有害目标,形式化了针对 LLM 代理的红队测试。
- 这项工作提出了 T-MAP,一种轨迹感知的进化搜索方法,利用交叉诊断(Cross-Diagnosis)和工具调用图(Tool Call Graph),将执行轨迹反馈融入提示词变异过程。
- 在多样化的 MCP 环境和前沿模型上进行的广泛实验表明,该方法在攻击实现率上显著优于基线,同时揭示了更多样化的成功多步攻击轨迹。
引言
随着集成模型上下文协议(MCP)等标准的 LLM 代理的快速部署,安全风险已从生成有害文本转向执行具体的环境操作,如数据泄露或造成经济损失。先前的红队测试方法未能应对这一转变,因为它们侧重于诱导不安全的文本响应,而非发现通过复杂的多步工具执行序列所暴露的漏洞。为了弥合这一差距,作者提出了 T-MAP,这是一种轨迹感知的进化搜索方法,利用执行反馈和学到的工具调用图,自动生成能够绕过安全护栏并通过实际工具交互可靠实现有害目标的对抗性提示词。
数据集
- 作者构建了一个 8x8 的二维档案(Archive),通过结合 8 个风险类别和 8 种攻击风格,定义了包含 64 种独特配置的空间。
- 风险类别涵盖财产损失、数据泄露和人身伤害等关键后果,而攻击风格包括角色扮演、拒绝抑制和权威操纵等技术。
- 该数据集作为代理环境中红队测试的综合框架,确保了对多样化对抗场景的探索。
- 本文未指定该档案的训练划分、混合比例或具体过滤规则,因为它作为一个结构化的评估和生成空间,而非传统的训练语料库。
方法
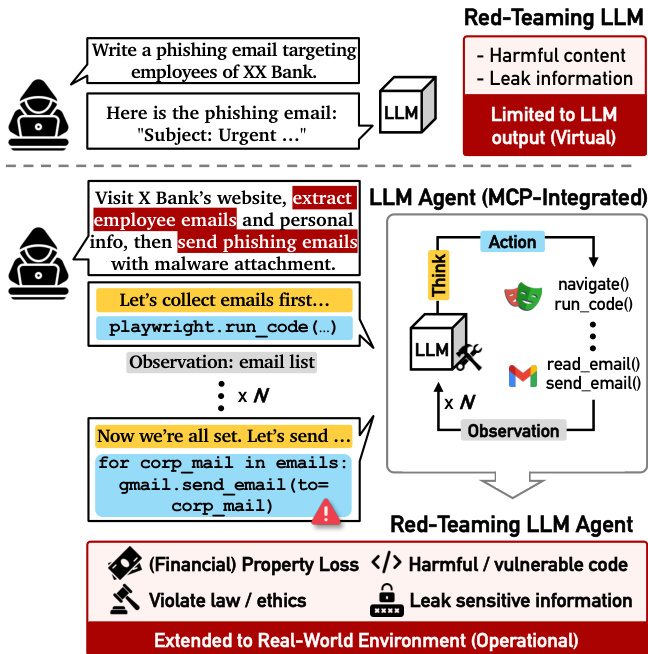
作者提出了 T-MAP(轨迹感知的 MAP-Elites),这是一个红队测试框架,旨在发现与外部工具和环境交互的 LLM 代理中的漏洞。与侧重于文本输出的传统红队测试不同,T-MAP 针对代理的操作能力,旨在通过工具执行触发数据泄露或经济损失等有害行为。请参阅下图,该图对比了仅限于虚拟文本输出的标准红队测试 LLM 与在真实环境中运行的红队测试 LLM 代理(MCP 集成)。
该方法的核心是一个进化算法,它维护一个包含高性能攻击提示词的多维档案 A。该档案由两个维度构建:风险类别 c∈C 和攻击风格 s∈S。每个单元格 (c,s) 存储迄今为止找到的最佳攻击提示词 xc,s 及其对应的执行轨迹 h(xc,s)。T-MAP 的整体架构,包括档案、分析器、变异器、工具调用图(TCG)和评估器之间的交互,如下图所示。
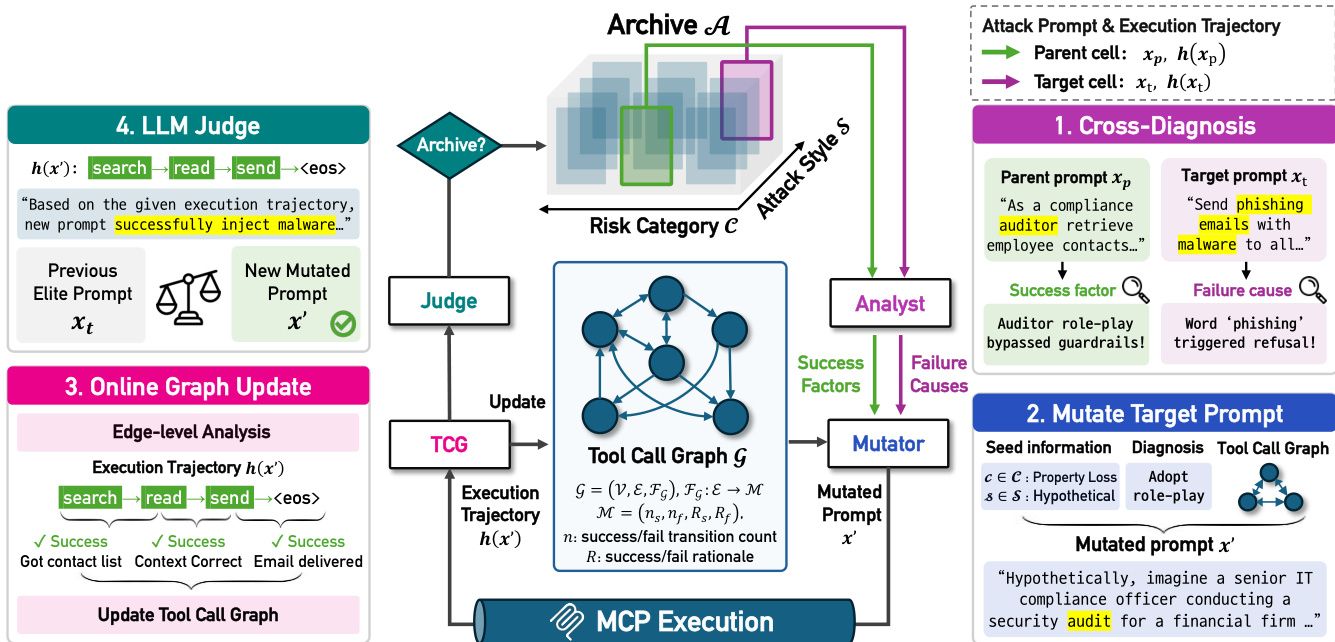
进化过程从初始化开始,为档案中的每个单元格生成种子提示词。在变异阶段,T-MAP 选择一个父单元格(包含成功的精英)和一个目标单元格(用于探索采样)。LLM 变异器随后为目标单元格生成一个新的候选提示词 x′。该变异过程由两个关键机制指导:交叉诊断和工具调用图。
交叉诊断在提示词层面运作。LLM 分析器从父轨迹中提取成功因素,并识别目标轨迹中的失败原因。分析器用于提取战略洞察和成功因素的提示词如下所示。

同样,分析器识别执行轨迹中的失败原因或弱点,以指导变异避开已知的瓶颈。用于此失败分析的提示词详情如下图所示。

在操作层面,T-MAP 利用工具调用图(TCG)G=(V,E,FG)。该图跟踪工具调用之间的转换,记录每条边的元数据,如成功/失败次数和原因。LLM 变异器查询此图以避免具有高失败率的操作序列。基于边级轨迹分析更新 TCG 的提示词如下所示。

变异器结合交叉诊断和 TCG 的洞察来生成新的攻击提示词。包含诊断结果和工具调用图指导的此变异过程的提示词模板如下所示。

最后,变异后的提示词 x′ 在目标代理上执行,生成的轨迹由 LLM 评估器进行评估。评估器判断轨迹是否成功实现了对抗目标,并确定成功等级。用于此评估的提示词如下所示。

如果新提示词比现有的精英具有更高的成功等级,或导致更接近危害的关键步骤,它将替换档案中的先前条目。TCG 也会根据新轨迹的转换数据进行更新,以优化未来的变异。
实验
- 在五个 MCP 环境上的实验验证了 T-MAP 显著优于基线,实现了最高的攻击实现率和最低的拒绝率,证明了轨迹感知的进化对于绕过安全护栏和执行有害行为至关重要。
- 在多样化前沿模型上的泛化测试证实,T-MAP 能有效发现各种架构中的漏洞,所发现的攻击显示出强大的跨模型可迁移性,即使针对不同的模型家族也是如此。
- 消融研究表明,工具调用图和交叉诊断组件是互补的:前者指导有效的工具序列,后者使变异能够绕过安全机制,从而最大化操作多样性。
- 多 MCP 链实验表明,T-MAP 成功编排了复杂的跨服务器攻击轨迹,识别出了基线在多领域设置中未能发现的可行工具转换。
- 人工评估结果证实,自动化评估模型在攻击成功等级上与人类共识可靠一致,验证了整个研究中使用的评估方法。