Command Palette
Search for a command to run...
VideoDetective:通过外在查询与内在相关性进行线索挖掘以实现长视频理解
VideoDetective:通过外在查询与内在相关性进行线索挖掘以实现长视频理解
Ruoliu Yang Chu Wu Caifeng Shan Ran He Chaoyou Fu
摘要
多模态大语言模型(MLLMs)在长视频理解任务中仍面临严峻挑战,这主要受限于上下文窗口容量,迫使模型必须精准识别稀疏的查询相关视频片段。然而,现有方法大多仅依据查询内容定位线索,忽视了视频内在的结构特性以及不同片段间相关性的动态变化。针对这一问题,我们提出了 VideoDetective 框架,该框架通过融合“查询 - 片段”相关性与片段间亲和度,实现了长视频问答任务中的高效线索检索。具体而言,我们将视频划分为多个片段,并基于视觉相似性与时间邻近性构建视觉 - 时间亲和图(visual-temporal affinity graph)。随后,我们执行“假设 - 验证 - 优化”(Hypothesis-Verification-Refinement)循环,以估算已观测片段对查询的相关性得分,并将该得分传播至未观测片段,从而生成全局相关性分布。该分布能够引导模型在稀疏观测条件下,精准定位对最终回答至关重要的核心片段。实验结果表明,该方法在多个主流基准测试中,跨多种主流 MLLMs 均取得了显著的性能提升;在 VideoMME-long 基准上,准确率最高提升了 7.5%。我们的代码已开源:https://videodetective.github.io/
一句话总结
南京大学和中国科学院的研究人员提出了 VideoDetective,这是一个通过构建视觉 - 时间亲和图并采用“假设 - 验证 - 优化”循环来定位稀疏查询相关片段的框架,从而增强长视频理解能力,在 VideoMME-long 等基准测试中实现了显著的准确率提升。
主要贡献
- 本文介绍了 VideoDetective,这是一个长视频推理框架,它将视频建模为时空亲和图,以整合外部查询相关性与内在的视觉和时间相关性,从而实现有效的线索定位。
- 该工作实现了一个“假设 - 验证 - 优化”循环,利用图扩散将稀疏的相关性分数从观测到的锚点片段传播开来,动态更新全局信念场,从而从有限的观测中恢复语义信息。
- 实验结果表明,该方法作为一种即插即用的解决方案,能够持续提升不同多模态大语言模型(MLLM)骨干网络的性能,在 VideoMME-long 基准测试中实现了高达 7.5% 的准确率提升。
引言
长视频理解对于将多模态大语言模型(MLLM)部署到现实世界内容中至关重要,然而这些系统受限于上下文窗口,难以识别稀疏的查询相关片段。先前的方法依赖于单向的查询到视频匹配或简单的采样,这往往忽略了视频内在的时间结构和因果连续性,导致线索遗漏和推理能力不足。为此,作者提出了 VideoDetective,该框架将视频建模为时空亲和图,以联合利用外部查询相关性和内在的片段间相关性。通过执行带有图扩散的“假设 - 验证 - 优化”循环,该方法将相关性分数从观测片段传播到未观测片段,从而实现了准确的线索定位,并在多种 MLLM 骨干网络上取得了显著的准确率提升。
数据集
- 作者利用官方采样率、API 文档中的每帧 token 数量以及标准视频分辨率设置,估算了 token 消耗量的下限。
- 此分析旨在为 Gemini-1.5-Pro、GPT-4o 和 LLaVA-Video-72B 等模型提供基线,而非描述特定训练数据集的构成。
- 本节未定义训练集划分、混合比例或过滤规则,因为重点在于理论效率指标。
- 文中未详述裁剪策略或元数据构建,而是依赖标准分辨率配置来计算 token 使用量。
方法
作者提出了 VideoDetective,这是一个推理框架,将长视频问答问题建模为视觉 - 时间亲和图上的迭代相关性状态估计问题。其核心目标是高效地结合外部查询相关性与内在视频相关性,以定位与查询相关的片段。整体架构包含三个主要阶段:图构建、“假设 - 验证 - 优化”迭代循环以及最终推理。
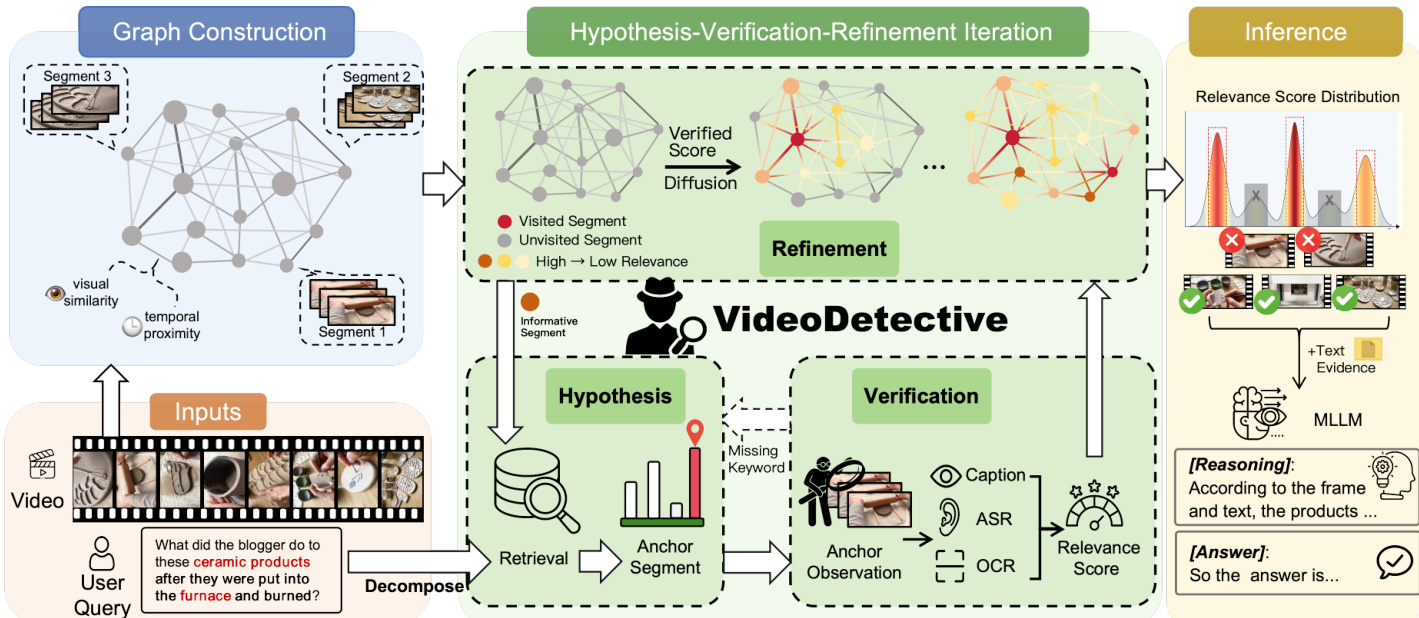
为了从稀疏的片段观测中建模连续的全局信念场,该方法首先构建视觉 - 时间亲和图。视频根据视觉相似性被划分为语义片段,每个片段作为一个节点。边由亲和矩阵定义,该矩阵融合了视觉相似性(帧特征的余弦相似度)和时间邻近性(指数衰减核)。这种图结构捕捉了内在关联,定义了相关性分数应如何从观测到的锚点片段传播到未访问的片段。
该框架的核心是“假设 - 验证 - 优化”循环,它迭代地更新相关性状态。系统维护两个状态向量:表示稀疏验证相关性分数的注入向量 Y(t),以及表示通过图扩散推断出的密集全局相关性分布的信念场 F(t)。
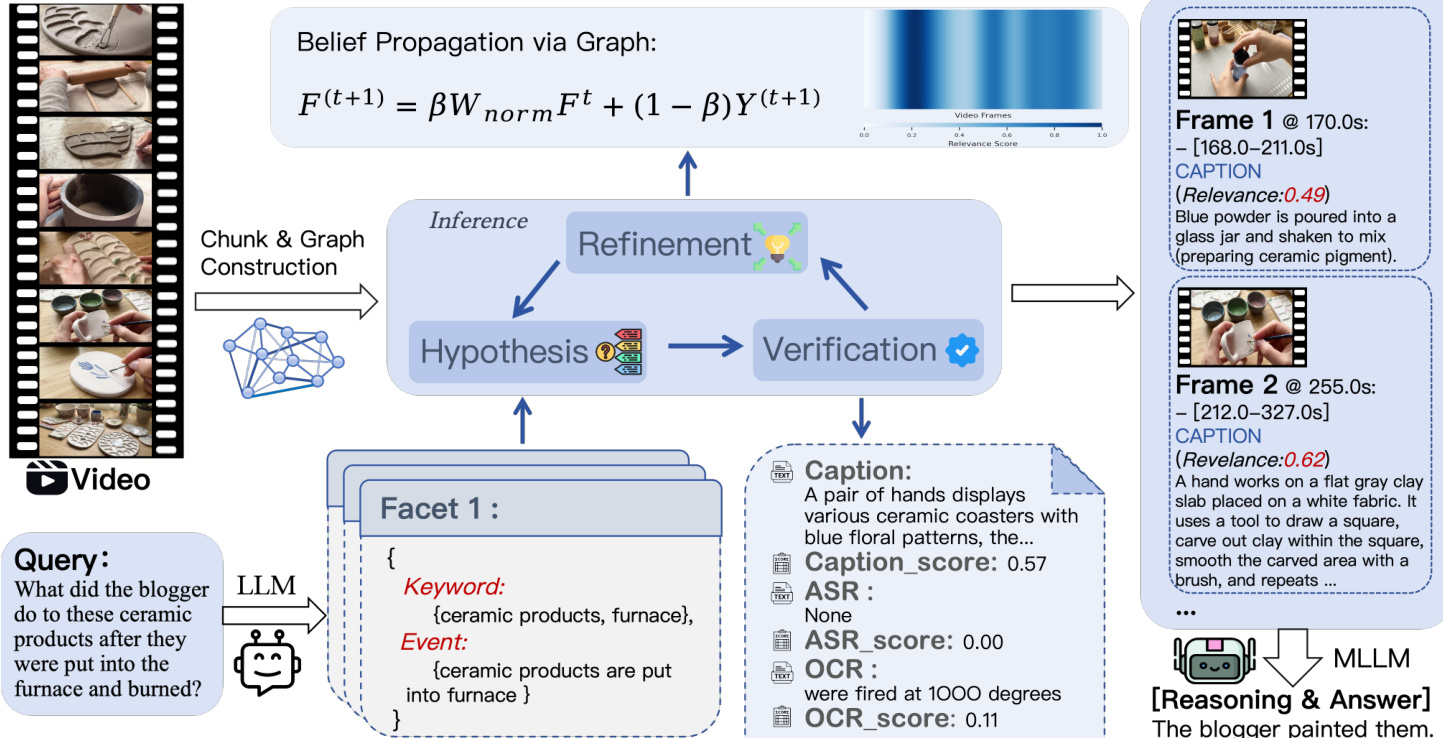
在假设阶段,用户查询被分解为包含关键词和事件描述的语义方面。系统选择一个锚点片段进行验证。初始阶段,它使用方面引导初始化(Facet-Guided Initialization)来寻找最佳匹配。在迭代过程中,如果证据缺失,它采用信息邻居探索(Informative Neighbor Exploration)来选择未访问的邻居;如果所有方面都已解决,则采用全局间隙填充(Global Gap Filling)来探索高信念的未访问节点。
接下来,在验证阶段,系统观测选定的锚点片段。系统提取多源证据,包括视觉描述、通过 OCR 识别的屏幕文本以及通过 ASR 识别的语音转录。一种源感知评分机制通过结合词汇相似度(用于精确文本匹配)和语义相似度(用于事件理解)来计算相关性分数。该分数被注入到状态向量 Y(t) 中。
最后,在优化阶段,将观测到的相关性分数在图上传播以更新全局信念场。这是通过迭代信念传播实现的,由以下方程控制:
F(t+1)=βWnormFt+(1−β)Y(t+1)其中 Wnorm 是对称归一化的亲和矩阵,β 平衡平滑性和一致性。该过程允许相关性信号从稀疏观测扩散到整个视频结构。
迭代完成后,收敛的全局信念场作为最终的相关性分布。系统应用图非极大值抑制(Graph-NMS)来选择一组多样化的高置信度片段,确保覆盖所有查询方面。这些选定的片段及其多模态证据被打包并输入到下游 MLLM 中以生成最终答案。
实验
- 在四个长视频基准测试上的实验验证了 VideoDetective 在各种模型规模下始终优于专有和开源基线,确立了新的最先进结果。
- 泛化测试证实,该框架作为一种即插即用的解决方案,无需针对特定任务进行微调,即可显著提升不同骨干网络的性能。
- 消融研究表明,图流形传播、语义方面分解和迭代假设 - 验证循环都是减少噪声和纠正检索偏差的关键组件。
- 模态扩展分析显示,视觉感知能力是主要的性能瓶颈,而语言模型组件仅需轻量级资源即可进行有效的查询分解。
- 效率评估表明,VideoDetective 以适度的 token 消耗实现了更高的准确率,在成本效益平衡方面优于更大的专有模型和其他方法基线。