Command Palette
Search for a command to run...
Omni-WorldBench:面向以交互为核心的世界模型综合评估
Omni-WorldBench:面向以交互为核心的世界模型综合评估
摘要
基于视频的世界模型主要沿着两大范式演进:视频生成与三维重建。然而,现有评估基准存在明显局限:针对生成模型的基准往往仅聚焦于视觉保真度与文本 - 视频对齐,而依赖静态三维重建指标的基准则从根本上忽视了时间动态特性。我们认为,世界模型的未来在于四维(4D)生成,即对空间结构与时间演化进行联合建模。在此范式中,核心能力是交互响应性(interactive response),即准确反映交互动作如何在时空维度上驱动状态转变的能力。然而,目前尚无基准能够系统性地评估这一关键维度。为填补这一空白,我们提出了 Omni-WorldBench,这是一个专为评估世界模型在四维环境下交互响应能力而设计的综合性基准。Omni-WorldBench 包含两个核心组件:一是 Omni-WorldSuite,一套涵盖多样化交互层级与场景类型的系统性提示(prompt)集合;二是 Omni-Metrics,一种基于智能体(Agent)的评估框架,通过量化交互动作对最终结果及中间状态演化轨迹的因果影响,来度量世界建模能力。我们利用该基准对 18 种具有代表性的世界模型进行了广泛评估,涵盖多种技术范式。分析结果揭示了当前世界模型在交互响应方面的关键局限性,并为未来研究提供了可操作的见解。Omni-WorldBench 将向公众开放,以推动交互式四维世界建模领域的进步。
一句话总结
来自中国科学院大学(UCAS)、中科院自动化所(CASIA)、北京航空航天大学、北京邮电大学以及阿里巴巴集团的研究人员推出了 Omni-WorldBench,这是一个用于评估 4D 世界模型交互响应能力的新颖基准。与以往侧重于静态或保真度的工具不同,该基准采用 Omni-Metrics 来量化动作如何驱动时空状态转换,揭示了当前生成和重建范式中的关键差距。
主要贡献
- 本文介绍了 Omni-WorldBench,这是一个综合基准,旨在通过解决缺乏对时间动态和空间结构的系统性评估问题,来评估世界模型在 4D 环境下的交互响应能力。
- 这项工作提出了 Omni-WorldSuite,这是一套涵盖不同交互层级和场景类型的系统性提示词套件;同时提出了 Omni-Metrics,这是一个基于智能体的框架,通过测量交互动作对结果和状态演化轨迹的因果影响来量化模型性能。
- 对 18 种代表性世界模型在多种范式下的广泛评估揭示了当前交互响应能力的关键局限性,为未来交互式 4D 世界建模的研究提供了可操作的见解。
引言
基于视频的世界模型对于规划、反事实模拟等任务至关重要,然而当前的评估方法未能捕捉其核心能力:4D 环境中的交互响应。现有的基准要么优先考虑视觉保真度和文本 - 视频对齐,要么依赖忽略时间动态且将交互限制为简单相机运动的静态 3D 指标。为此,作者推出了 Omni-WorldBench,这是一个综合框架,包含用于多样化交互提示的 Omni-WorldSuite,以及 Omni-Metrics——一个基于智能体的系统,用于量化动作如何在时空上因果地驱动状态演化。
数据集
-
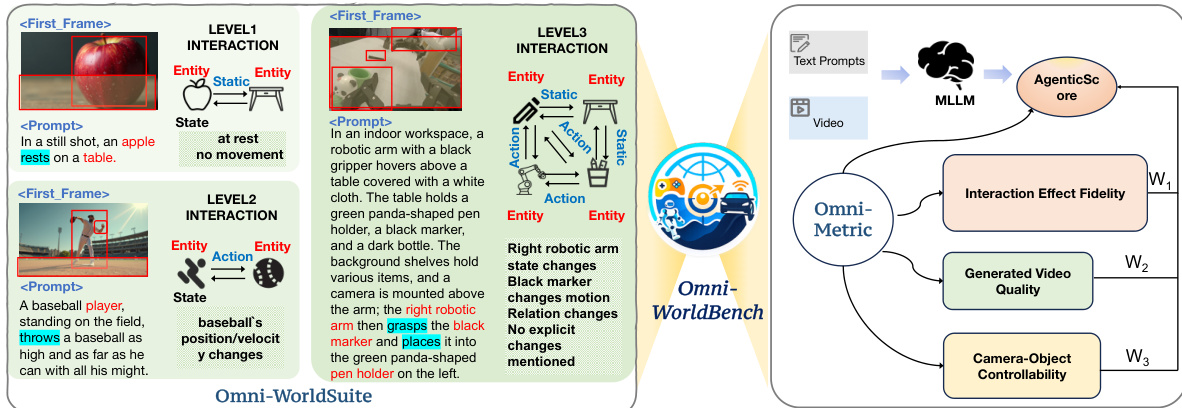
数据集构成与来源 作者推出了 Omni-WorldSuite,这是一个包含 1,068 个评估提示的基准,旨在测试交互式世界模型。该数据集涵盖了通用日常生活场景以及自动驾驶、具身机器人和游戏等任务导向型领域。其构建采用了两种主要策略:基于数据集的生成和概念驱动的合成。
-
各子集的关键细节
- 基于数据集的子集:该部分从开源数据集中提取初始帧和相机轨迹以确保真实性。它利用 DriveLM 进行自动驾驶,InternData-A1 进行具身机器人,以及 Sekai 进行游戏和模拟。
- 概念驱动的子集:该部分利用“生成 - 验证 - 优化”流水线合成文本、初始帧和相机轨迹。它依赖于涵盖室内/室外场景和特定交互类型的原型概念,初始帧由 FLUX.1-dev 生成,并通过人工筛选进行优化。
- 交互层级:提示词分为三个层级:1 级(效果局限于单个物体)、2 级(物体间的局部交互)和 3 级(影响多个物体的全局环境变化)。2 级包含的提示词数量最多。
-
数据使用与处理 作者严格将该数据集用于评估而非模型训练。每个提示词作为一个测试用例,包含初始帧图像、交互驱动演化的文本描述以及可选的相机轨迹。评估流水线测量生成视频的质量、相机 - 物体可控性以及交互效果保真度,从而生成统一的 AgenticScore。
-
元数据构建与优化 为了便于指标计算,作者为每个提示词标注了辅助元数据,包括受影响和未受影响的实体列表、预期的运动方向以及时序事件序列。多阶段图像生成流水线确保了高保真的初始帧,最低分辨率为 1024x1024。所有生成的描述和图像均经过人工验证,以修正空间关系、消除语言歧义并确保物理合理性。
方法
作者推出了 Omni-Metric,这是一个旨在促进对世界模型进行全方位评估的综合框架。该框架 delineates 三个关键维度,以建立评估感知质量、环境稳定性和因果推理能力的严格范式。如框架图所示,该系统评估生成视频质量、相机 - 物体可控性以及交互效果保真度,最终通过自适应加权机制聚合这些分数。
在计算具体指标之前,该框架会从基于评估提示 P 生成的视频 v 中提取结构化信息。作者利用 GroundingDINO 和 SAM 提取每个实体的时间一致分割掩码序列,记为 {{trajk}k=1N}。此外,使用 RAFT 估计光流场 F 以捕捉区域运动强度,而相对相机运动则通过连续帧之间的光流变化进行近似。
交互效果保真度维度是核心贡献之一,用于定量评估长期内容一致性、因果逻辑顺序以及对物理定律的遵循程度。为了解决这些挑战,提出了四个综合评估指标。InterStab-L 通过评估用户指定的时间重访对 R={(ta,tb)} 之间的视觉内容一致性,来量化长时程时间相干性。它通过复合相似度指标 s(i,j) 整合了低级结构保真度和高级语义一致性:
s(i,j)=I1(SSIMgray(Ii,Ij)+cos(ϕ(Ii),ϕ(Ij))),其中 ϕ(⋅) 代表预训练的视觉编码器。为了防止平凡的静态序列虚增分数,该机制引入了动态门控机制。InterStab-N 通过测量目标实体掩码外部区域的运动能量来评估非目标区域的稳定性。InterCov 通过验证受交互影响的实体是否表现出语义一致的响应,而未受影响的实体是否保持稳定,来量化物体级别的因果忠实度,并利用视觉 - 语言模型(VLM)进行语义验证。最后,InterOrder 通过使用 VLM 验证时间先后顺序,来量化传播事件的时间顺序与真实序列 E={ei}i=1K 之间的对齐程度。
参考交互示例以了解所评估场景的复杂性,范围从 1 级静态交互到涉及机器人和物理学的 3 级复杂动态交互。

对于生成视频质量维度,作者利用了 VBench 和 WorldScore 等先前基准中的成熟指标,涵盖成像质量、时间闪烁、运动平滑度和内容对齐。为了有效平衡静态和动态视频属性,该框架采用 AgenticScore 进行自适应权重分配。
AgenticScore 机制将每个评估指标视为一个独立的智能体。三个以交互为中心的智能体分别计算交互效果保真度(AI)、生成视频质量(AG)和相机 - 物体可控性(AC)的分数。随后,一个聚合智能体利用基于评估提示条件化的多模态大语言模型(MLLM)分析这些维度的相对重要性,将生成的排名映射到预定义的权重系数 w1、w2 和 w3。最终分数定义为:
AgenticScore=w1AI+w2AG+w3AC.这种方法确保了评估能够适应多样化的应用场景,根据提示词的语义内容为不同的评估维度分配不同的权重,而不是简单地平均所有指标。
实验
- 相机 - 物体可控性实验验证了一个新的评估框架,该框架评估场景连贯性、物体一致性和过渡检测,表明将物体控制重构为视觉问答任务比基于规则的匹配具有更好的鲁棒性。
- 对 18 种世界模型在文本到视频、图像到视频和相机控制范式下的综合基准测试表明,图像到视频模型通常实现了最高的整体性能,而感知相机的方法在特定的可控性指标上表现优异。
- 定量和定性分析证实,虽然大多数模型已经掌握了基本的时间平滑度和闪烁减少,但在维持因果交互一致性、处理复杂物理动态以及实现联合相机 - 物体控制方面仍存在显著局限性。
- 视觉对比显示,Wan2.2 和 HunyuanWorld 等先进模型在复杂动作中成功保持了解剖结构的完整性和场景逻辑,而其他模型则遭受结构崩溃或生成虚假元素的问题,从而验证了所提出的 Omni-Metric 框架。