Command Palette
Search for a command to run...
速度源于简约:一种用于快速音视频生成基础模型的单流架构
速度源于简约:一种用于快速音视频生成基础模型的单流架构
摘要
我们提出 daVinci-MagiHuman,这是一款面向以人为核心的生成任务而设计的开源音视频生成基础模型。daVinci-MagiHuman 采用单流 Transformer 架构,在统一的 token 序列中通过纯自注意力机制(self-attention)联合处理文本、视频和音频,从而实现同步的音视频生成。该单流设计避免了多流或交叉注意力(cross-attention)架构的复杂性,同时能够利用标准的训练与推理基础设施进行高效优化。该模型在面向人类的生成场景中表现尤为突出,能够生成富有表现力的面部表演、自然的语音与表情协调、逼真的肢体动作,以及精准的音视频同步。它支持多语言口语生成,涵盖中文(普通话与粤语)、英语、日语、韩语、德语和法语。为实现高效推理,我们将单流主干网络与模型蒸馏(model distillation)、潜在空间超分辨率(latent-space super-resolution)以及 Turbo VAE 解码器相结合,实现在单块 H100 GPU 上仅需 2 秒即可生成一段 5 秒时长、256p 分辨率的视频。在自动评估中,daVinci-MagiHuman 在主流开源模型中实现了最高的视觉质量与文本对齐度,同时在语音可懂度方面取得了最低的词错误率(14.60%)。在成对人工评估中,基于 2000 次对比测试,该模型对 Ovi 1.1 的胜率高达 80.0%,对 LTX 2.3 的胜率为 60.9%。我们已开源完整的模型栈,包括基础模型、蒸馏模型、超分辨率模型以及推理代码库。
一句话总结
SII-GAIR 和 Sand.ai 推出了 daVinci-MagiHuman,这是一个开源的音视频基础模型。该模型采用单流 Transformer 架构,无需复杂的交叉注意力机制即可生成同步的以人为核心的内容。这种方法实现了高效的多语言语音与动作合成,在视觉质量和语音可懂度方面均优于领先的开源模型。
主要贡献
- 本文介绍了 daVinci-MagiHuman,这是一个开源的音视频生成基础模型。它利用单流 Transformer,仅通过自注意力机制,在统一的令牌序列中处理文本、视频和音频,避免了多流或交叉注意力架构的复杂性。
- 该工作展示了强大的以人为核心的生成能力,包括富有表现力的面部表演和精确的音视频同步,同时支持六种主要语言的多语言语音生成,在自动评估中实现了 14.60% 的词错误率。
- 作者提出了一种高效的推理流程,结合了模型蒸馏、潜空间超分辨率以及 Turbo VAE 解码器,可在单张 H100 GPU 上于 2 秒内生成 5 秒长的 256p 视频,并完全开源了完整的模型栈和代码库。
引言
视频生成正迅速向同步的音视频合成演进,但开源解决方案难以在可扩展架构中平衡高质量输出、多语言支持和推理效率。现有的开源模型通常依赖复杂的多流设计,难以与训练和推理基础设施进行联合优化。作者推出了 daVinci-MagiHuman,这是一个开源模型,利用单流 Transformer 在共享权重的骨干网络中统一处理文本、视频和音频。这种简化的方法通过潜空间超分辨率实现了快速推理,同时提供了强大的以人为核心的生成质量,并具备涵盖英语、中文和日语等语言的广泛多语言能力。
方法
作者提出了 daVinci-MagiHuman,其核心是专为联合生成同步视频和音频而设计的单流 Transformer 架构。与分别处理不同模态的双流方法不同,该模型将文本、视频和音频令牌表示为统一的序列,仅通过自注意力进行处理。这种设计避免了交叉注意力模块的复杂性,同时易于利用标准基础设施进行优化。
如下图所示:
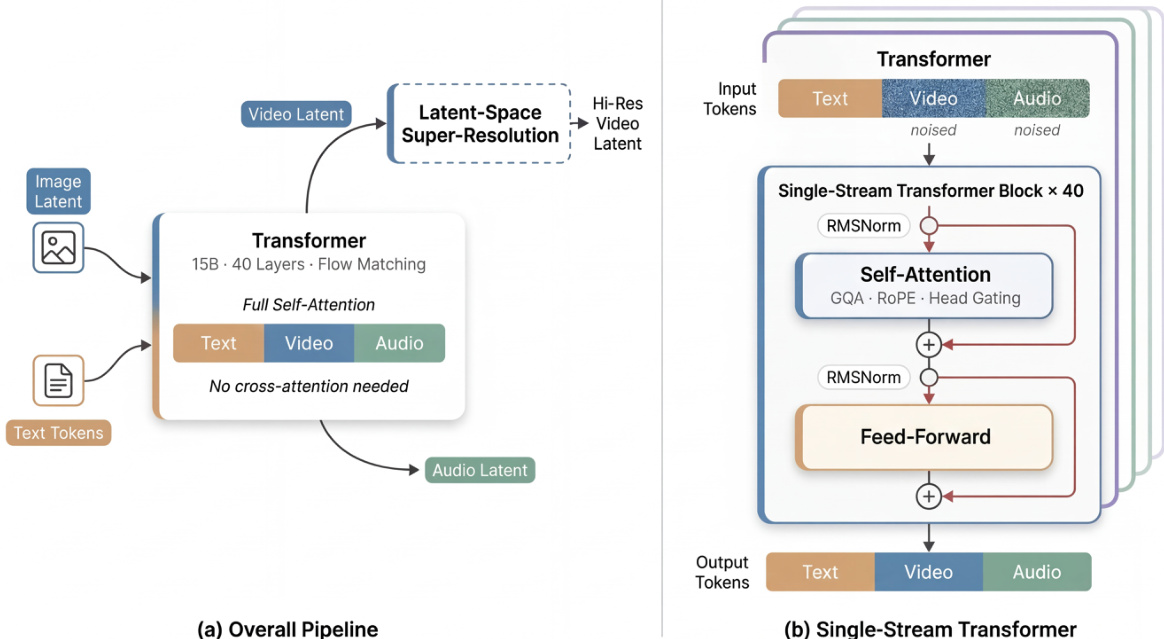
基础生成器接收文本令牌、参考图像潜变量以及带噪声的视频和音频令牌。它使用一个拥有 150 亿参数、40 层的 Transformer 联合去噪视频和音频令牌。随后,潜空间超分辨率阶段可以在更高分辨率下细化生成的视频。其内部架构采用“三明治”结构:第一层和最后 4 层利用特定模态的投影和归一化参数,而中间的 32 层在所有模态间共享参数。这种设计在边界处保留了模态敏感性,同时在共享表示空间中实现了深度的多模态融合。
几种关键机制提升了模型的性能和稳定性。系统采用无时间步去噪,直接从噪声输入推断去噪状态,而非使用显式的时间步嵌入。此外,模型在注意力块中集成了每头门控机制。对于每个注意力头 h,一个学习到的标量门控通过 Sigmoid 函数 σ 调节输出 oh,从而产生门控输出:
o~h=σ(qh)oh这以最小的开销提高了数值稳定性和可表示性。
为了确保高效的推理,作者整合了多种互补技术。潜空间超分辨率允许基础模型在较低分辨率下生成,随后在潜空间中进行细化,从而避免了昂贵的像素空间操作。Turbo VAE 解码器取代了标准解码器,以减少关键路径上的开销。此外,通过 MagiCompiler 进行的全图编译融合了跨层边界的算子,而基于 DMD-2 的模型蒸馏将所需的去噪步骤减少到 8 步,且无需无分类器引导。
实验
- 在 VerseBench 和 TalkVid-Bench 上的定量基准测试表明,与 Ovi 1.1 和 LTX 2.3 相比,daVinci-MagiHuman 在视觉质量、文本对齐和语音可懂度方面表现更优,同时保持了具有竞争力的物理一致性。
- 成对人工评估证实,评测者强烈偏好 daVinci-MagiHuman 而非两个基线模型,在大多数比较中,评测者更青睐其整体的音视频质量、同步性和自然度。
- 推理效率测试表明,该流程在单张 H100 GPU 上可在 40 秒内生成高分辨率的 1080p 视频,利用蒸馏的基础阶段和 Turbo VAE 解码器在速度与输出质量之间取得了平衡。