Command Palette
Search for a command to run...
LumosX:将任意身份与其属性关联以实现个性化视频生成
LumosX:将任意身份与其属性关联以实现个性化视频生成
Jiazheng Xing Fei Du Hangjie Yuan Pengwei Liu Hongbin Xu Hai Ci Ruigang Niu Weihua Chen Fan Wang Yong Liu
摘要
近期,Diffusion 模型的显著进展极大推动了文本到视频生成技术的发展,使得在精细控制前景与背景元素的同时,实现个性化内容创作成为可能。然而,跨主体的面部属性对齐仍面临严峻挑战,现有方法缺乏确保组内一致性的显式机制。填补这一空白亟需显式建模策略与具备面部属性感知能力的数据资源。为此,我们提出 LumosX 框架,从数据构建与模型设计两个维度实现突破。在数据层面,我们构建了一条定制化采集流水线,从独立视频中协同提取文本描述与视觉线索,并利用多模态大语言模型(MLLM)推理并分配特定主体的依赖关系。这些提取的关系先验引入了更细粒度的结构,不仅增强了个性化视频生成的表达控制能力,还支撑了综合性基准测试(benchmark)的构建。在模型层面,关系自注意力(Relational Self-Attention)与关系交叉注意力(Relational Cross-Attention)将位置感知嵌入与精细化的注意力动态相结合,以显式刻画主体 - 属性依赖关系,从而强化组内一致性,并显著提升不同主体簇之间的可分性。在自建基准上的全面评估表明,LumosX 在细粒度、身份一致且语义对齐的个性化多主体视频生成任务中实现了最先进(state-of-the-art)的性能。代码与模型已开源,访问地址:https://jiazheng-xing.github.io/lumosx-home/。
一句话总结
来自浙江大学、达摩院和新加坡国立大学的研究人员提出了 LumosX,这是一个利用关系自注意力(Relational Self-Attention)和交叉注意力(Cross-Attention)将人脸与属性显式绑定的框架,克服了以往个性化多主体视频生成中的对齐问题。
主要贡献
- 本文提出了一种数据收集流程,利用多模态大语言模型推断并分配特定主体的依赖关系,构建了一个包含显式人脸 - 属性对应关系的综合基准,用于个性化视频生成。
- 提出了名为 LumosX 的新框架,该框架集成了关系自注意力和关系交叉注意力模块,通过位置感知嵌入和优化的注意力动态,将身份与其属性显式绑定。
- 在构建的基准上的广泛评估表明,该方法在细粒度、身份一致且语义对齐的多主体视频生成方面实现了最先进的性能。
引言
扩散模型彻底改变了文本到视频的生成,使得虚拟制作和电子商务等需要精细控制多个交互主体的应用成为可能。然而,现有方法难以在不同角色之间保持特定人脸与其属性的精确对齐,在处理复杂的多主体提示时,往往导致属性纠缠或身份混淆。为了解决这一问题,作者引入了 LumosX,这是一个结合了新数据流程(利用多模态大语言模型推断显式的主体 - 属性依赖关系)和新架构(包含关系自注意力和关系交叉注意力模块)的框架。这些组件将身份与其属性显式绑定,在强制组内一致性的同时抑制不同主体间的干扰,从而实现最先进的个性化视频生成。
数据集
-
数据集构成与来源:作者从 Panda70M 仓库构建训练数据集和推理基准,经过严格的清洗和处理,生成了 157 万高质量视频样本。最终集合包括 131 万个单主体、23 万个双主体和 3 万个三主体视频,而基准测试由 500 个精选的 YouTube 视频组成,按类似的主体数量划分。
-
关键过滤与清洗规则:为了确保视觉和语义质量,该流程移除了带有字幕、黑白边框或灰度内容的视频。作者仅保留 QAlign 质量评分高于 3.5、美学评分超过 2.0 且运动流强度在 0.05 到 2.0 之间的样本。包含超过三个检测到的人的视频被排除,并通过 VideoCLIP 嵌入聚类去除重复项。
-
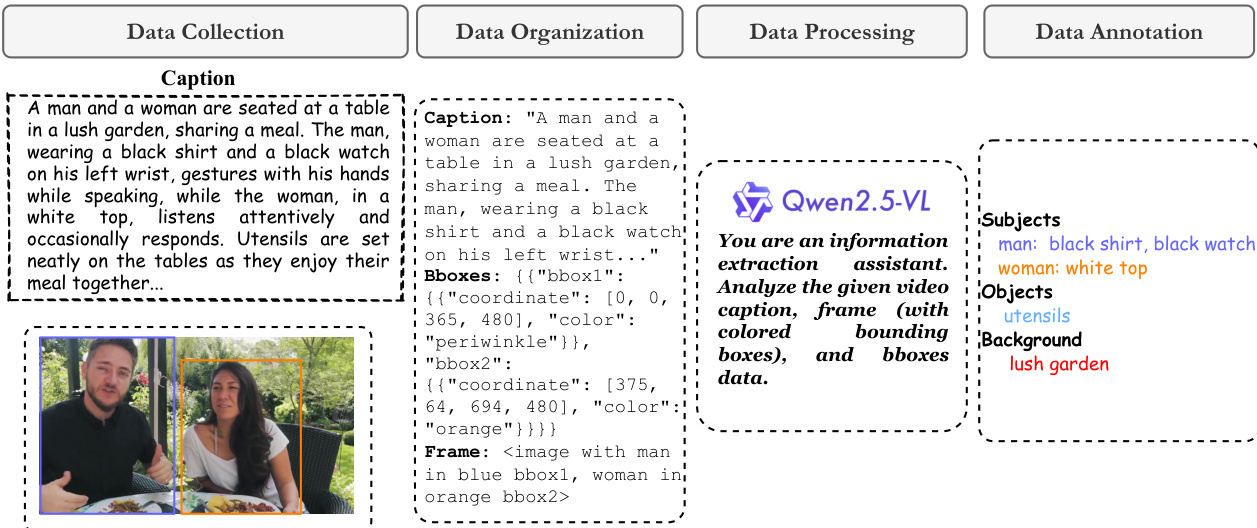
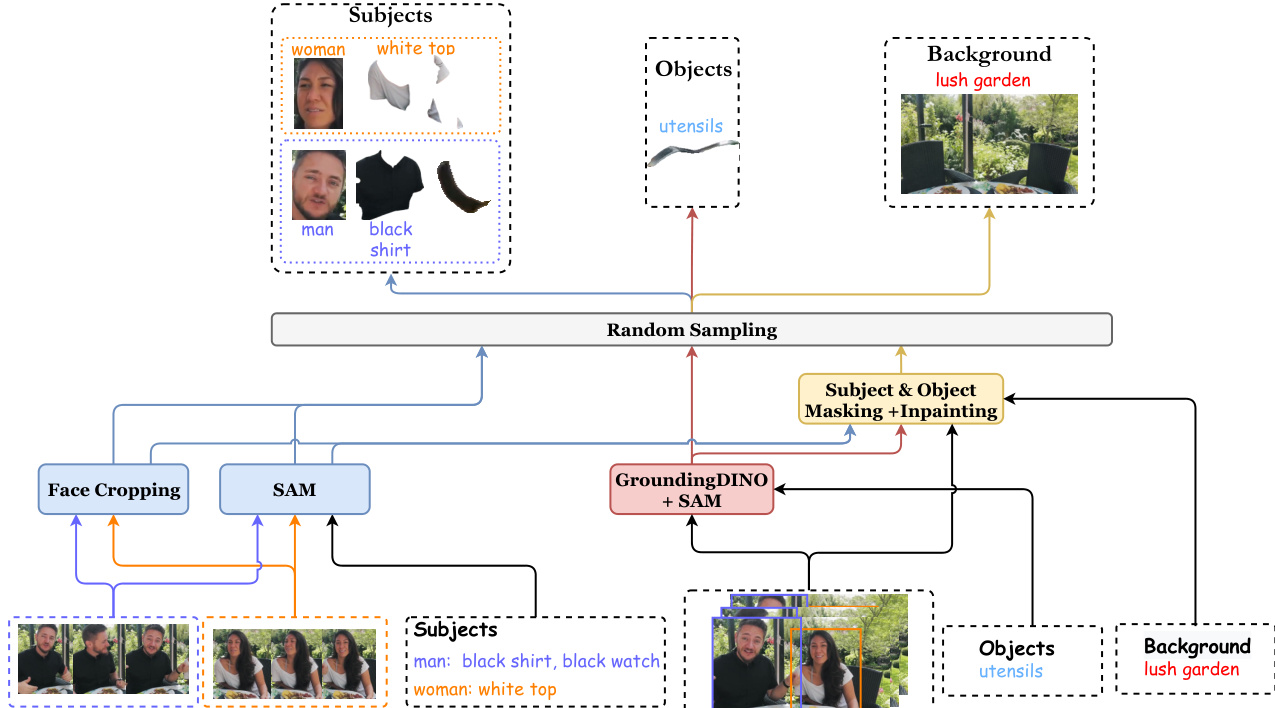
数据处理与条件图像构建:作者使用 VILA 模型生成的更丰富描述替换原始标题,并在 5%、50% 和 95% 的位置采样三个关键帧。他们利用 Qwen2.5-VL 检索实体词并匹配人脸属性,使用人体检测来区分多个主体。条件图像是通过裁剪人脸、使用 SAM 分割属性、通过 GroundingDINO 和 SAM 隔离对象,以及使用 FLUX 修复生成干净背景而得出的。从三个关键帧中随机为每个实体选择一个有效的条件图像,以确保多样性并符合单参考推理设置。
-
训练策略与混合:该模型基于 Wan2.1 T2V 架构进行微调,分为两个阶段:先在单主体数据上训练 15k 次迭代,然后在混合多主体数据上训练 16k 次迭代。每个训练片段包含 81 帧,分辨率为 480p。作者对主体和对象参考图像应用数值和几何增强,而背景图像仅接受数值变换。在推理期间,系统支持每个主体最多三个属性,以保持与训练分布的一致性。
方法
作者提出了 LumosX,这是一个专为个性化多主体视频生成设计的新框架,能够显式建模人脸 - 属性依赖关系。该系统支持从文本和图像条件生成细粒度、身份一致的视频。请参阅框架图以了解生成能力的概览。

为了解决缺乏针对多主体生成的标注数据的问题,作者开发了一个支持具有特定主体依赖关系的开放集实体的数据收集流程。该流程从独立视频中提取带有显式人脸 - 属性依赖关系的标题和前景 - 背景条件图像。如下图所示,该过程涉及视频帧提取、标题生成、人体检测和实体匹配。
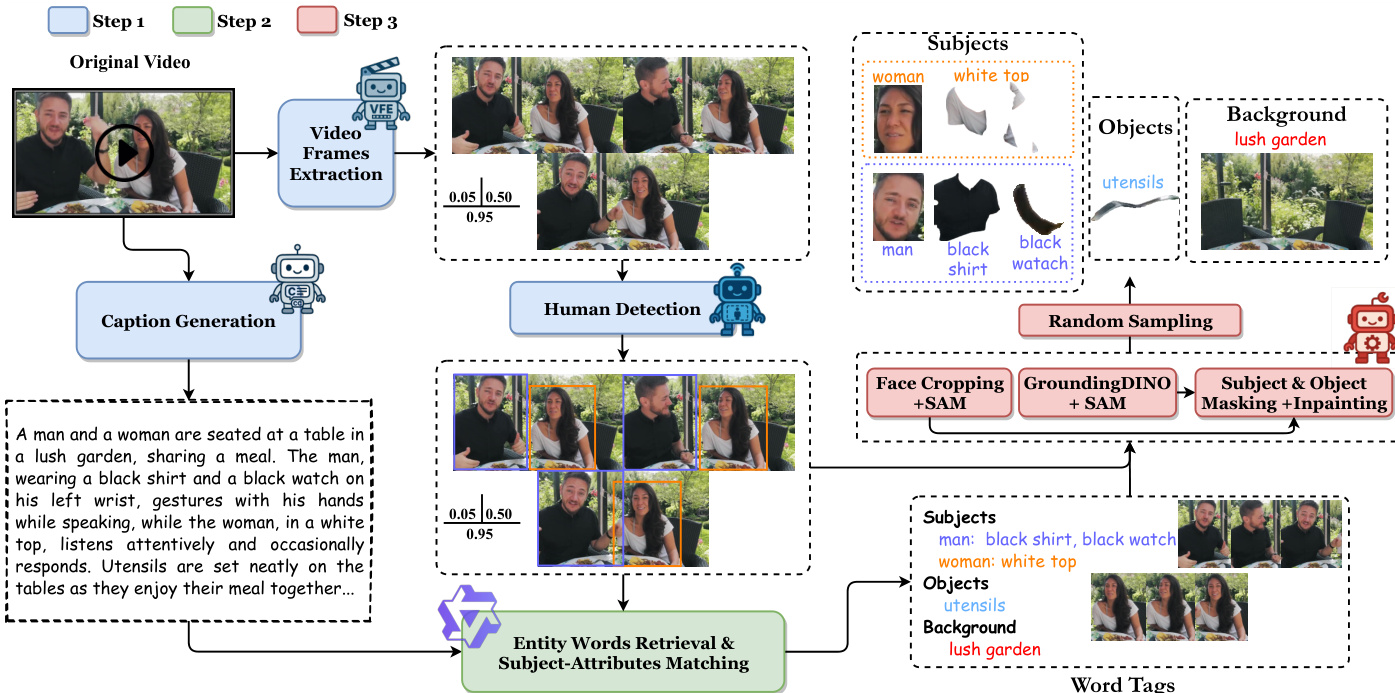
对于实体词检索和主体 - 属性匹配,系统利用 Qwen2.5-VL。该模型分析视频标题、带边界框的帧以及边界框数据,以提取关键实体词并将其分类为主体、对象和背景。
随后,系统获取主体、对象和背景的条件图像。这涉及人脸裁剪、定位和掩膜处理,以生成干净的背景图像。
该框架基于文本到视频模型 Wan2.1。所有条件图像通过 VAE 编码器编码为图像令牌,与去噪视频令牌连接后输入 DiT 块。在每个块中,作者引入了关系自注意力和关系交叉注意力。请参阅框架图以了解详细的架构。
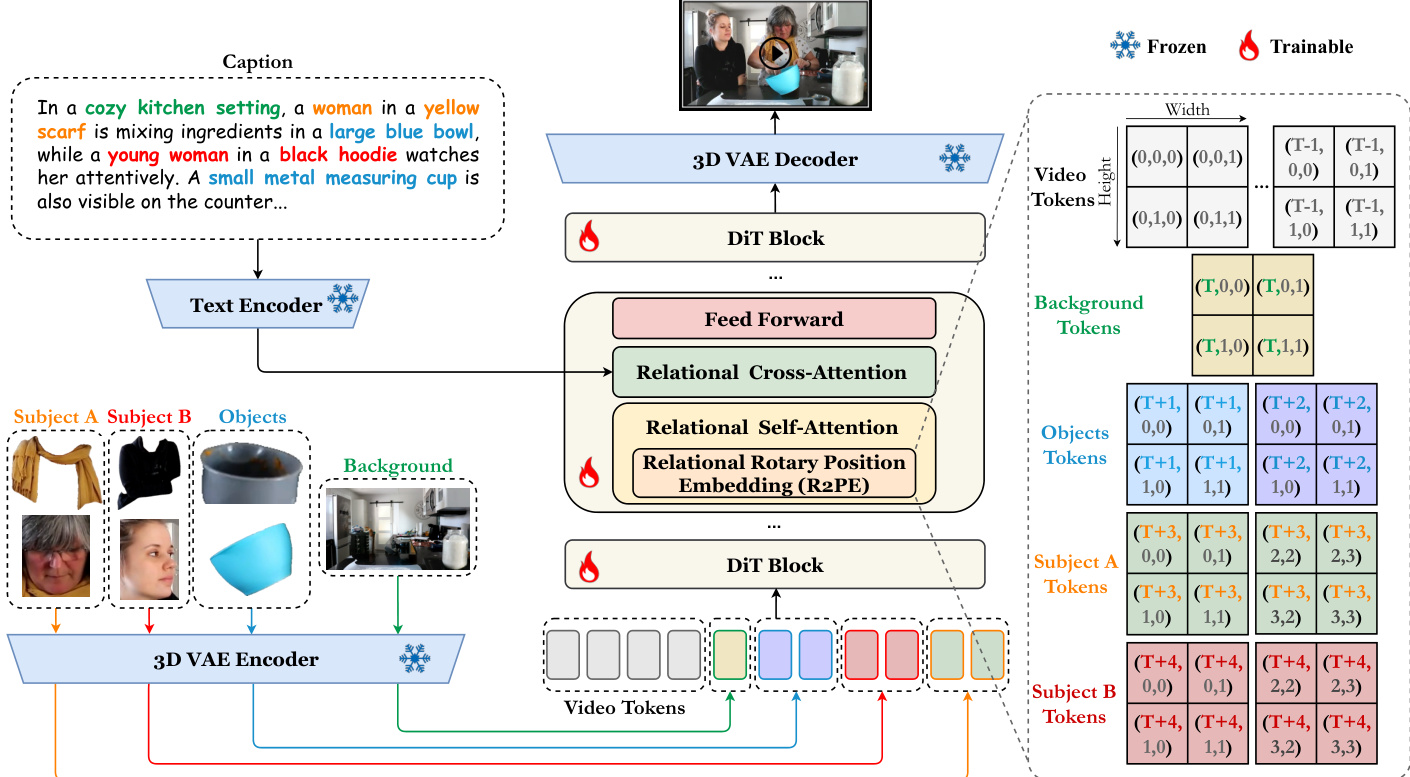
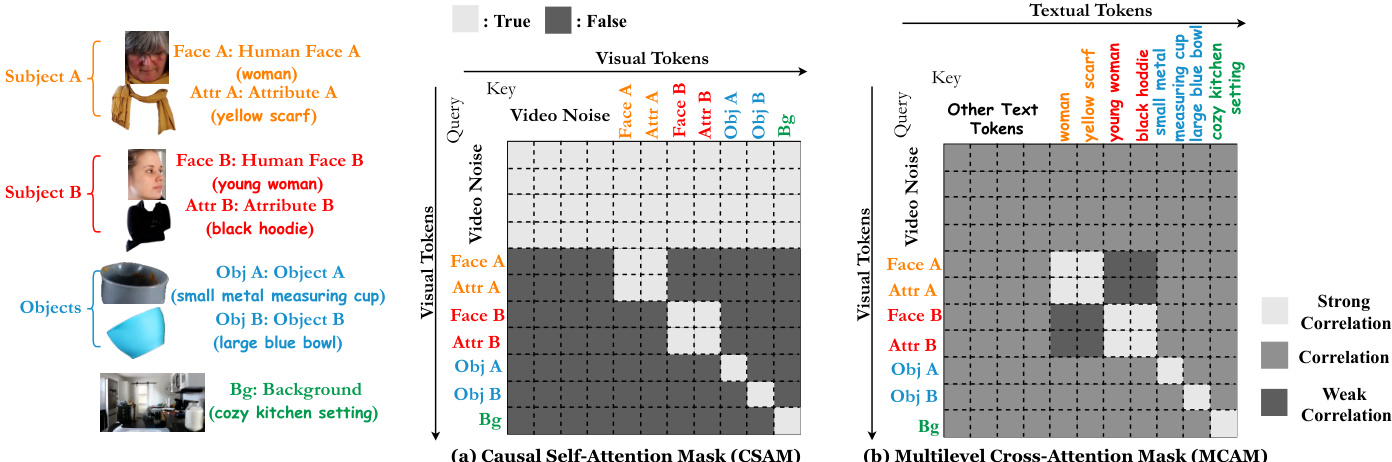
为了支持时空和因果条件建模,作者引入了具有关系旋转位置嵌入(R2PE)的关系自注意力和因果自注意力掩码(CSAM)。此外,具有多级交叉注意力掩码(MCAM)的关系交叉注意力整合了文本条件并对齐了人脸 - 属性关系。如下图所示,注意力掩码设计包括 CSAM 和 MCAM。
该模型使用流匹配(Flow Matching)进行训练。其目标是估计随机噪声与视频潜在表示之间的速度场。训练目标定义为预测速度与真实速度之间的均方误差。
实验
- 主要实验将 LumosX 与 ConsisID、SkyReels-A2 和 Phantom 等基线进行了比较,用于身份一致和主体一致的视频生成,验证了 LumosX 在保留面部身份以及在单主体和多主体场景中准确匹配人脸与特定属性方面实现了更优越的最先进性能。
- 消融研究证实,R2PE、CSAM 和 MCAM 模块对于将人脸绑定到属性以及防止角色混淆至关重要,其中 MCAM 在特定的超参数设置下显示出身份一致性和视频质量之间的最佳平衡。
- 扩展评估表明,即使在不重新训练的情况下处理四个或更多主体时,LumosX 仍能保持稳健的性能,在面部一致性方面优于基于图像个性化的流程,并依赖高质量背景修复以确保逼真的视频生成。
- 人类研究和时间连贯性评估进一步证实,与竞争方法相比,该方法生成的视频更自然,具有更好的人脸 - 属性对齐和运动平滑度,同时引入了最小的计算开销。