Command Palette
Search for a command to run...
LLMs 的 Y-Combinator:基于 λ-Calculus 解决 Long-Context Rot 问题
LLMs 的 Y-Combinator:基于 λ-Calculus 解决 Long-Context Rot 问题
Amartya Roy Rasul Tutunov Xiaotong Ji Matthieu Zimmer Haitham Bou-Ammar
摘要
大型语言模型(LLMs)正日益被用作通用推理引擎,但其处理长输入的能力仍受限于固定的上下文窗口。递归语言模型(Recursive Language Models, RLMs)通过将提示(prompt)外部化并递归求解子问题来应对这一挑战。然而,现有的 RLMs 依赖于开放式的“读取 - 求值 - 打印”循环(Read-Eval-Print Loop, REPL),在此过程中模型会生成任意控制代码,导致执行过程难以验证、预测和分析。为此,我们提出了 λ-RLM,这是一种面向长上下文推理的框架。该框架摒弃了自由形式的递归代码生成,转而采用基于λ演算(λ-calculus)的强类型函数式运行时。λ-RLM 执行一个经过预验证的组合子(combinators)紧凑库,并仅在边界叶节点子问题上使用神经推理(neural inference),从而将递归推理转化为具有显式控制流的结构化函数式程序。我们证明,λ-RLM 提供了标准 RLMs 所缺乏的形式化保证,包括:程序终止性、闭式成本上界、随递归深度可控的精度扩展,以及在简单成本模型下的最优划分规则。在实证评估中,涵盖四项长上下文推理任务及九种基础模型,λ-RLM 在 36 项模型 - 任务对比中有 29 项优于标准 RLM;在不同模型层级间,平均准确率最高提升 21.9 分,延迟最高降低 4.1 倍。这些结果表明,相较于开放式的递归代码生成,基于强类型的符号控制为长上下文推理提供了更可靠且高效的基石。λ-RLM 的完整实现已开源,供社区使用,地址为:https://github.com/lambda-calculus-LLM/lambda-RLM。
一句话总结
来自印度理工学院德里分校、华为诺亚方舟实验室和伦敦大学学院的研究人员提出了 λ-RLM,这是一个用基于 λ-演算的类型化函数式运行时替代开放式递归代码的框架。与标准的递归语言模型(RLM)相比,该方法提供了终止性等形式化保证,并显著提高了长上下文推理的准确性和延迟表现。
主要贡献
- 本文介绍了 λ-RLM,这是一个用基于 λ-演算的类型化函数式运行时替代自由形式递归代码生成的框架,用于执行经过预验证的组合子库。该方法将递归推理转化为具有显式控制流的结构化函数式程序,仅在有界的叶节点子问题上使用神经推理。
- 建立了标准递归语言模型所缺乏的形式化保证,包括终止性、闭式成本界限、随递归深度受控的精度扩展,以及在简单成本模型下的最优划分规则。这些特性通过将递归编码为确定性算子库上的不动点,并通过符号规划器强制执行可预测的执行来实现。
- 在四个长上下文推理任务和九个基础模型上的实证评估表明,该方法在 36 次比较中有 29 次优于标准 RLM,平均准确率最高提升了 21.9 分。结果还显示延迟降低了高达 4.1 倍,验证了类型化符号控制为长上下文推理提供了更可靠和高效的基础。
引言
当处理超出其固定上下文窗口的输入时,大型语言模型面临关键瓶颈,往往被迫依赖截断或滑动窗口,从而丢弃关键信息。虽然递归语言模型(RLM)试图通过将提示视为递归分解的外部环境来解决这一问题,但由于它们要求模型在开放式循环中生成任意控制代码,因此存在严重的可靠性问题。这种方法导致执行不可预测、可能无法终止,并产生难以审计的故障模式,这些故障模式与实际的推理任务正交。
作者提出了 λ-RLM,这是一个用基于 λ-演算的类型化函数式运行时替代自由形式代码生成的框架,以强制执行结构化的控制流。通过执行紧凑的预验证组合子库,并将神经推理限制在有界的叶节点子问题上,该系统将语义推理与结构编排分离开来。这种设计提供了关于终止性和成本的形式化保证,同时在各种长上下文任务中在准确率上实证优于标准 RLM,并将延迟降低了高达 4.1 倍。
方法
λ-RLM 框架通过将控制流与语义推理分离,从根本上重构了长上下文推理。该系统不依赖大语言模型(LLM)生成任意代码来进行任务分解,而是采用一个类型化函数式运行时,其中递归通过预验证组合子的固定库来表达。这种设计确保了执行轨迹是确定性的、可审计的,并保证终止,而基础语言模型则专门保留用于解决有界的叶节点子问题。整体架构分为三个不同的层,如下面的框架图所示。
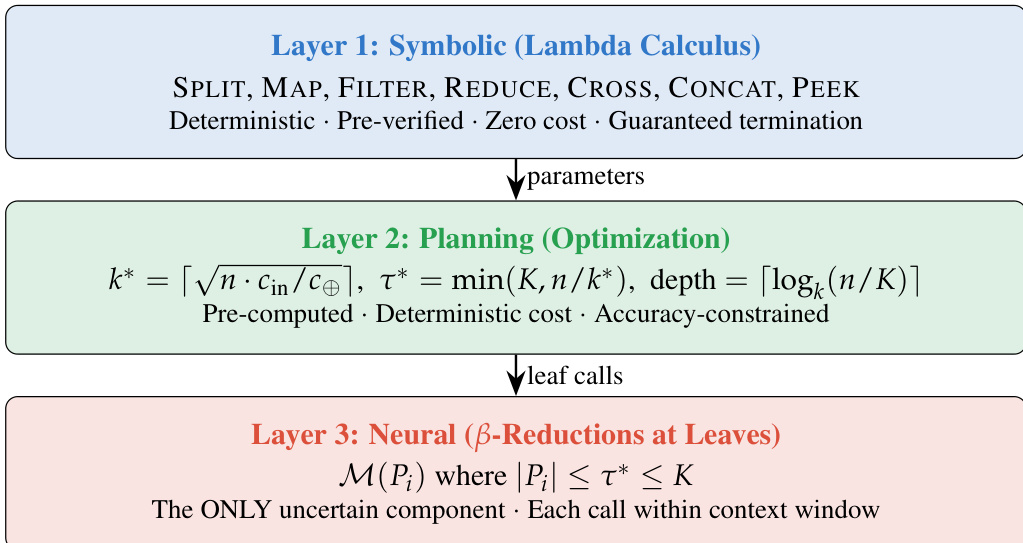
第一层基于符号 λ-演算原理运行。该层定义了一个紧凑的组合子库 L,包含确定性算子,如 SPLIT、MAP、FILTER、REDUCE、CROSS、CONCAT 和 PEEK。这些算子处理提示的结构化操作和递归调用的编排,而无需调用神经模型。通过将控制接口限制在这组受信任的组合子中,系统消除了与自由形式代码生成相关的开放式故障模式。执行逻辑被形式化为一个不动点 λ-项,其中递归求解器 f 是相对于其自身定义的,从而允许在不使用外部命名机制的情况下进行结构化分解。
第二层负责规划与优化。在执行开始之前,确定性规划器根据输入大小 n、模型的上下文窗口 K 和成本函数,计算递归策略的最优参数。具体而言,规划器确定划分大小 k∗、叶节点阈值 τ∗ 和递归深度。这些值的推导旨在最小化总计算成本,同时满足精度约束。最优划分大小 k∗ 计算为 k∗=⌈n⋅cin/c⊕⌉,以平衡叶节点调用的成本与组合的开销。深度被限制为 ⌈logk∗(n/K)⌉,确保递归步骤的数量是可预测且有限的。
第三层处理叶节点处的神经 β-归约。这是系统中唯一引入不确定性的组件。当递归分解到达长度 ∣Pi∣≤τ∗ 的子提示 Pi 时,系统调用基础语言模型 M 直接解决子问题。该模型充当有界预言机,在其原生上下文窗口内运行以确保高精度。这些叶节点调用的结果随后使用第一层中定义的符号组合算子沿递归树向上聚合。这种分离确保了神经模型仅在真正需要语义推理的地方使用,而周围的控制流保持符号化和高效。
实验
- 将 λ-RLM 与直接 LLM 推理和标准 RLM 进行比较,验证了与随机或单次通过方法相比,受限的类型化函数式运行时为长上下文推理提供了更优越的可靠性和效率。
- 实验证实了“规模替代假设”,表明形式化控制结构允许较弱的模型(例如 8B)达到或超过缺乏结构化编排的更大模型(例如 70B+)的精度。
- “效率与可预测性假设”得到了支持,研究发现用单个确定性组合子链替代多轮随机 REPL 循环,可将延迟降低 3 到 6 倍,并显著降低执行方差。
- 定性分析表明,结构化方法对于需要二次交叉引用的复杂任务最为有效,在这些任务中,它防止了直接推理中常见的被称为“上下文腐烂”的指数级精度下降。
- 消融研究表明,预构建的组合子库是性能提升的主要驱动力,而用于合并结果的符号操作通过消除递归过程中不必要的 LLM 调用进一步降低了延迟。
- 虽然固定的组合子库通常优于开放式代码生成,但后者在需要创造性、特定任务策略的特定场景中仍具有优势,例如用于仓库导航的自适应代码生成。