Command Palette
Search for a command to run...
FIPO:通过 Future-KL 影响下的 Policy Optimization 激发深度推理能力
FIPO:通过 Future-KL 影响下的 Policy Optimization 激发深度推理能力
Qwen Pilot Team
摘要
我们提出了 Future-KL Influenced Policy Optimization (FIPO),这是一种旨在克服大语言模型(LLM)推理瓶颈的强化学习算法。虽然 GRPO 式训练能够实现有效的规模化,但它通常依赖于基于结果的奖励(ORM),这种方式会将全局优势(global advantage)均匀地分配到轨迹中的每一个 token 上。我们认为,这种粗粒度的信用分配(credit assignment)机制由于无法区分关键的逻辑转折点与无关紧要的 token,从而限制了性能的进一步提升。FIPO 通过将折扣后的未来 KL 散度(discounted future-KL divergence)纳入策略更新过程,解决了这一问题,从而构建了一种稠密优势(dense advantage)表述,能够根据 token 对后续轨迹行为的影响力对其进行重新加权。实证研究表明,FIPO 使模型能够突破标准基准模型中常见的长度停滞现象。在 Qwen2.5-32B 上的评估结果显示,FIPO 将平均思维链(chain-of-thought)长度从约 4,000 tokens 扩展到了 10,000 tokens 以上,并将 AIME 2024 的 Pass@1 准确率从 50.0% 提升至峰值 58.0%(最终收敛于约 56.0%)。这一表现优于 DeepSeek-R1-Zero-Math-32B(约 47.0%)和 o1-mini(约 56.0%)。我们的研究结果表明,建立稠密优势表述是推动基于 ORM 的算法进化的关键路径,有助于释放基座模型的全部推理潜力。我们已基于 verl 框架开源了我们的训练系统。
一句话总结
Qwen Pilot 团队提出了 Future-KL Influenced Policy Optimization (FIPO),这是一种强化学习算法,结合折扣未来-KL 散度来建立稠密优势公式,通过影响力对 token 进行重新加权,替代 GRPO 的粗粒度信用分配,使 Qwen2.5-32B 的平均思维链长度从约 4,000 扩展到超过 10,000 个 token,并将 AIME 2024 Pass@1 准确率从 50.0% 提升至 58.0%,从而优于 DeepSeek-R1-Zero-Math-32B 和 o1-mini。
核心贡献
- 本文介绍了 Future-KL Influenced Policy Optimization (FIPO),这是一种强化学习算法,将折扣未来-KL 散度纳入策略更新以创建稠密优势公式。该方法根据 token 对后续轨迹行为的影响力进行重新加权,以解决 GRPO 风格训练中的粗粒度信用分配问题。
- 在 Qwen2.5-32B 上的评估显示,该方法将平均思维链长度从约 4,000 扩展到超过 10,000 个 token,并将 AIME 2024 Pass@1 准确率提升至峰值 58.0%。这些结果优于 DeepSeek-R1-Zero-Math-32B 和 o1-mini 等基线,同时突破了标准方法中出现的长度停滞。
- 训练系统在 verl 框架上开源,以支持基于 ORM 的算法演进。该工作表明,稠密优势公式可以在不依赖辅助价值模型或外部知识先验的情况下释放推理潜力。
引言
使用强化学习的测试时扩展策略对于解锁大型语言模型的深度推理能力至关重要。然而,标准 GRPO 训练依赖基于结果的奖励,在所有 token 上均匀分布优势,造成粗粒度信用分配问题。这种局限性阻碍模型识别关键逻辑转折点,并经常导致推理轨迹在中间长度处达到平台期。为此,作者引入了 Future KL Influenced Policy Optimization,将折扣未来 KL 散度纳入策略更新。这种方法创建稠密优势公式,根据 token 对后续行为的影响力重新加权,无需 critic 模型。实证表明,该方法使模型能够突破长度停滞,与先前基线相比,显著提高复杂数学基准上的准确率。
方法
FutureKL-Induced Policy Optimization (FIPO) 引入了一种新型强化学习框架,旨在解决标准 Group Relative Policy Optimization (GRPO) 中存在的粗粒度信用分配局限性。该方法通过将折扣 Future-KL 散度纳入策略更新,将稀疏的基于结果的奖励转化为稠密的 token 级监督。核心架构依赖三个主要组件:概率偏移分析、带有稳定性机制的 Future-KL 估计,以及重新加权的优势目标。
作者首先确立概率偏移作为信用分配的基本单位。该方法不将分布漂移视为正则化成本,而是将当前策略与旧策略之间的对数空间差异解释为行为调整的方向信号。该偏移定义为:
Δlogpt=logπθ(ot∣q,o<t)−logπθold(ot∣q,o<t).正偏移表示策略强化了特定推理步骤,而负偏移表示抑制。然而,仅依赖此瞬时信号无法捕捉长期后果。为此,框架将 Future-KL 定义为从当前步骤到序列结束的累积带符号概率偏移。该指标量化了当前策略相对于参考策略在轨迹剩余部分的累积偏差。
FutureKLt=k=t∑TΔlogpk.功能上,正的 Future-KL 值意味着更新后的策略强化了整个后续轨迹,充当稳定锚点。相反,负值信号表明源自当前 token 的轨迹变得不那么受青睐。实证分析显示,不受控制的负信号会导致严重的训练不稳定。如稳定性分析所示,这种崩溃伴随着 low-clip 比例的急剧上升和 Policy KL 的发散,表明累积的负信号可能达到破坏优化过程的极端值。
为了缓解这种方差,该方法通过显式屏蔽超过 Dual-Clip 阈值的 token 来优化 Future-KL 计算。这确保触发硬约束的 token 被排除在 Future-KL 计算之外,防止梯度爆炸。优化后的目标包含一个二进制滤波器 Mk,仅当重要性比率保持在阈值 c 内时评估为 1:
FutureKLt=k=t∑TMk⋅Δlogpk,Mk=I(πold(ok∣o<t)πθ(ok∣o<t)≤c).除了稳定性约束,该框架通过引入软衰减窗口解决长视野生成的不确定性。当前动作与未来 token 之间的因果依赖随着时间视野的增加而减弱。引入折扣因子 γ∈(0,1] 来模拟这种减弱的影响,确保信用分配集中在即时推理链上。实验中使用的最终公式为:
FutureKLt=k=t∑TMk⋅γk−t⋅Δlogpk.衰减率参数化为 γ=2−τ1,其中 τ 控制有效视野。这种指数公式创建连续滑动窗口,τ 代表未来信号影响力衰减一半的距离,允许模型优先考虑局部连贯性,同时过滤来自遥远未来的噪声。
最后,该方法通过调节标准优势估计将这些机制集成到策略优化目标中。修改后的优势 A~t 使用未来影响力权重 ft 定义:
ft=clip(exp(FutureKLt),1−ϵflow,1+ϵfhigh),A~t=A^t⋅ft.该公式将累积的标量信号从对数空间转换到乘法域,并约束系数以防止过度方差。当更新后的策略强化后续轨迹时,加权项放大梯度信号以鼓励当前 token。相反,当策略抑制未来轨迹时,项衰减更新以减少对局部有害 token 的奖励信号。
最终目标损失采用来自 DAPO 的 token 级公式,最大化 FIPO 目标:
JFIPO(θ)=E(q,a)∼D,{oi}∼πθold∑i=1G∣oi∣1i=1∑Gt=1∑∣oi∣min(ri,tfi,tA^i,t,clip(ri,t,1−ϵ,1+ϵ)fi,tA^i,t).这里,G 代表每次查询采样的输出数量,ri,t 表示重要性比率,fi,t 作为 Future-KL 重要性权重。这种方法在高效的 GRPO 框架内实现稠密监督,解决现有基线中观察到的长度 - 性能平台期。
实验
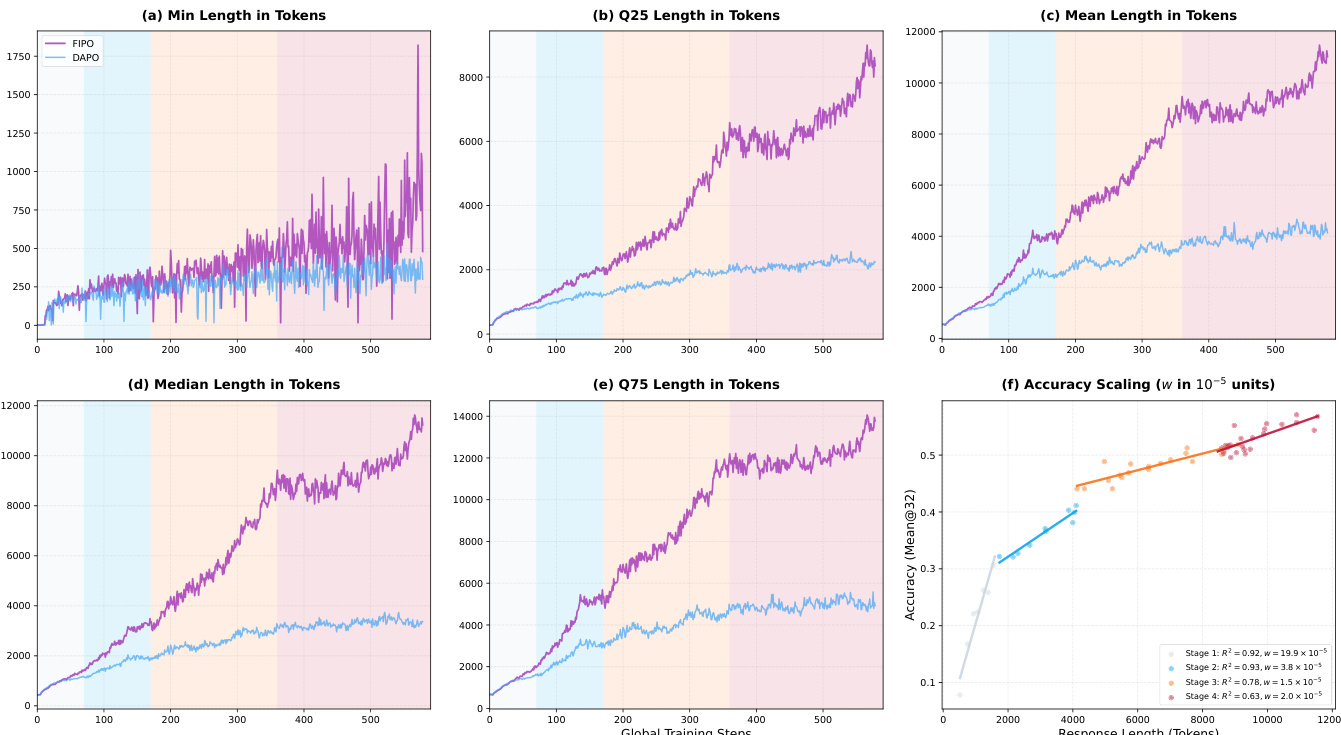
在 AIME 基准上的评估表明,FIPO 在 DAPO 基线之上提高了可靠性和推理深度。定性分析表明,响应长度的持续扩展和新兴的自我反思行为与准确率提升和更优的优化稳定性相关。不同的扩展动态显示,大型模型受益于高熵探索,而小型模型收敛到低熵状态,证实该方法在不妨碍稳定性的情况下解锁了潜在推理能力。
作者将提出的 FIPO 方法与 GRPO 和 DAPO 等基线在数学推理基准上进行评估。结果表明,FIPO 在 AIME 2024 和 AIME 2025 数据集上始终实现更高的 Pass@1 分数,优于竞争方法。这表明相对于标准基线配置,推理可靠性有系统性改进。FIPO 在 AIME 2024 基准上优于 GRPO 和 DAPO。该方法在 AIME 2025 基准上保持领先基线的位置。实验结果表明,Pass@1 分数相对于 DAPO 基线有系统性改进。
该表展示了消融研究,评估影响力权重裁剪范围和过滤机制对 FIPO 方法的影响。结果表明,将裁剪参数调整为更平衡的范围可显著提高主要基准上的性能,与标准配置相比。此外,数据证实极端值过滤机制对于实现最佳结果至关重要,移除它会导致准确率明显下降。平衡的影响力权重裁剪范围在主要基准上产生比标准配置更高的准确率。极端值过滤机制对于最大化性能至关重要,未过滤版本的表现不如过滤版本。性能提升在 AIME 2024 基准上更为明显,而更具挑战性的 AIME 2025 数据集在不同设置下显示一致的结果。

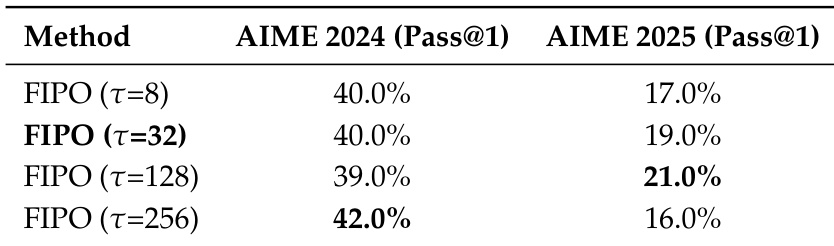
作者使用不同的衰减率视野评估 FIPO 方法,以评估其对数学推理性能的影响。结果表明,最佳视野设置因基准而异,最大视野在 AIME 2024 上表现最佳,中等长度视野在 AIME 2025 上表现最佳。伴随分析指出,虽然极端值可以提高分数,但中间视野通常提供更好的优化稳定性。最大衰减率视野在 AIME 2024 基准上产生最高的 Pass@1 分数。中等长度衰减率视野在 AIME 2025 基准上实现最佳性能。数据表明,性能对衰减率的敏感性在两个评估数据集之间有所不同。
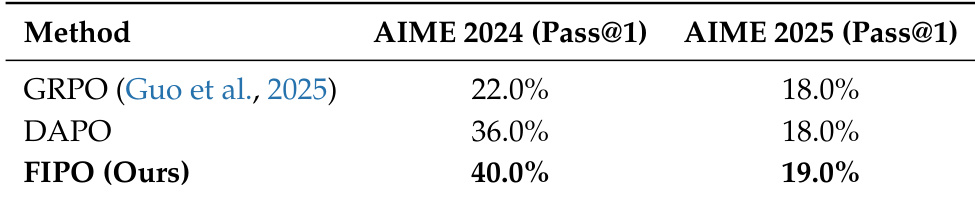
作者将提出的 FIPO 方法与 DAPO 基线在 AIME 2024 和 AIME 2025 数学推理基准上进行评估。结果表明,FIPO 在所有报告的指标上系统地优于基线,包括平均通过率、一致性和总体覆盖率。最显著的增益出现在平均准确率和一致性上,而找到至少一个正确解的概率改进较为温和。FIPO 在两个数据集上始终实现比 DAPO 基线更高的平均准确率和一致性分数。所提出的方法显示出相对于基线配置的可靠性指标的系统性改进。问题覆盖率的增益为正,但似乎不如一致性和平均性能的改进显著。

作者将 FIPO 方法与 GRPO 和 DAPO 等基线在 AIME 2024 和 AIME 2025 基准上进行评估,展示了推理可靠性和准确性的系统性改进。消融研究验证了平衡的影响力权重裁剪和极端值过滤对于最大化性能至关重要。此外,关于衰减率视野的实验表明最佳设置因基准而异,以确保优化稳定性。