Command Palette
Search for a command to run...
FlowScene:基于多模态图校正流的风格一致室内场景生成
FlowScene:基于多模态图校正流的风格一致室内场景生成
Zhifei Yang Guangyao Zhai Keyang Lu YuYang Yin Chao Zhang Zhen Xiao Jieyi Long Nassir Navab Yikai Wang
摘要
场景生成在工业领域具有广泛的应用前景,要求同时具备高真实感以及对几何结构与外观的精确控制。基于语言驱动的检索方法虽能从大规模物体数据库中组合出合理的场景,但往往忽视物体级别的精细控制,且难以保证场景层面的风格一致性。基于图结构的建模方法虽然通过显式建模物体间关系,提升了物体级的可控性并促进了整体一致性,但现有方法在生成高保真纹理结果方面仍存在不足,限制了其实际应用能力。为此,我们提出 FlowScene,一种以多模态图为条件的三分支场景生成模型,能够协同生成场景布局、物体形状及物体纹理。该模型的核心是一个紧密耦合的整流流(rectified flow)生成机制,在生成过程中实现物体间的信息交互,从而支持基于图的协同推理。这一设计不仅实现了对物体形状、纹理及关系的细粒度控制,还确保了场景在结构与外观层面的风格一致性。大量实验表明,在生成真实感、风格一致性及与人类偏好对齐度等方面,FlowScene 均优于基于语言条件和基于图条件的基线方法。
一句话总结
北京大学与慕尼黑工业大学的研究人员提出了 FlowScene,这是一种三分支生成模型。该模型利用紧密耦合的整流流(rectified flow)机制,协同合成多模态图驱动的布局、形状和纹理,在风格一致性和物体级控制方面优于现有的基于语言或图的基线方法。
主要贡献
- 本文提出了 FlowScene,这是一种以多模态图为条件的三分支生成模型,能够协同生成场景布局、物体形状和物体纹理,从而确保细粒度的控制以及场景级的风格一致性。
- 提出了一种紧密耦合的整流流机制作为核心引擎,该机制在采样过程中交换节点信息,既能满足单个物体的条件,又能满足整体场景约束,同时相比基于扩散的方法加速了生成过程。
- 大量实验表明,该方法在生成真实感、风格一致性和与人类偏好的一致性方面优于基于语言条件和基于图条件的基线方法,并支持多样化的输入源工作流。
引言
场景生成对于室内设计、VR/AR 和机器人等行业至关重要,这些领域的应用既需要高真实感,又需要对几何和外观进行精确控制。以往基于语言驱动的方法往往难以保证场景级的风格一致性或提供细粒度的物体控制,而现有的基于图的方法则难以以端到端的方式生成高保真的纹理结果。作者提出了 FlowScene,这是一种利用多模态图整流流(Multimodal Graph Rectified Flow)协同生成场景布局、物体形状和纹理的三分支生成模型。通过在采样过程中紧密耦合节点信息交换,该方法实现了对单个物体的细粒度控制,同时确保了整个场景结构和外观的风格一致性。
方法
所提出的框架 FlowScene 作为一个以多模态图为条件的三分支生成器运行,用于合成室内场景。该系统接受多样化的输入,包括自然语言描述和参考图像,这些输入被解析为结构化的场景图。该图作为生成过程的中心条件机制,确保物体布局、形状和纹理之间的一致性。
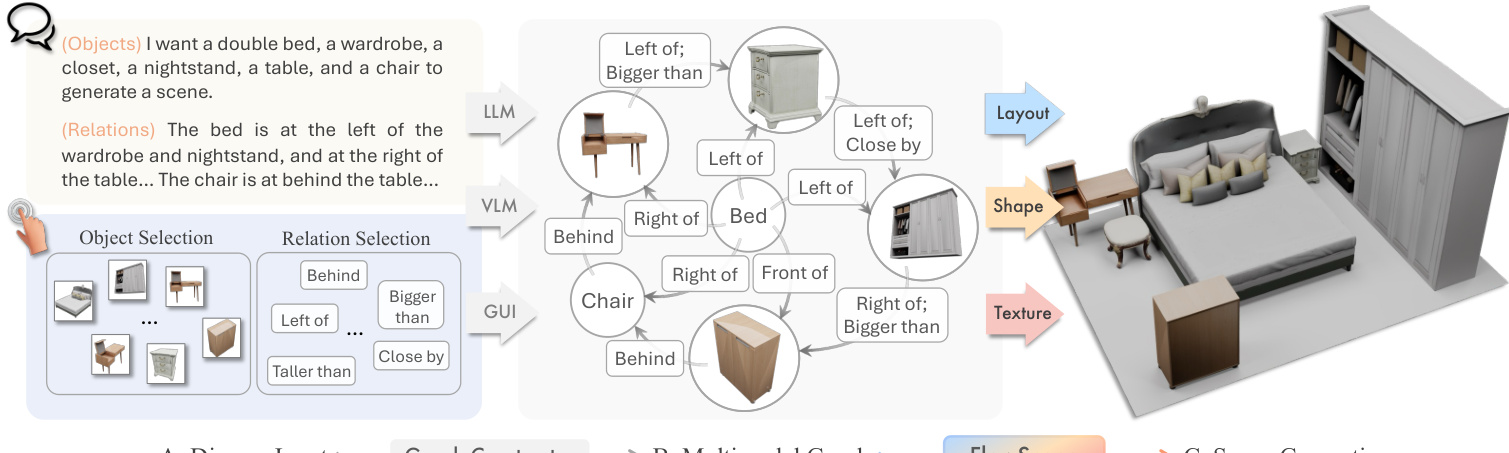
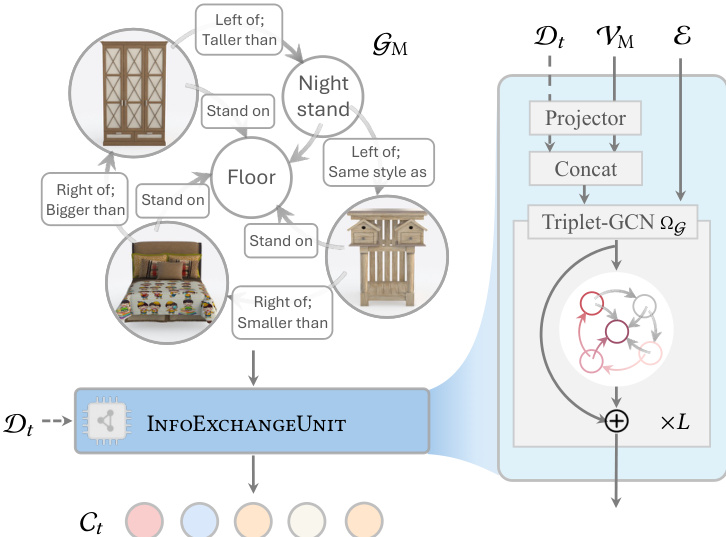
该过程始于构建多模态场景图 GM=(VM,E)。VM 中的节点代表物体,可以是纯文本、纯图像或多模态的,它们聚合了可学习的嵌入以及来自 CLIP 或 DINOv2 的基础特征。E 中的边编码了空间和语义关系,如“在...左侧”或“比...大”。LLM 或 VLM 解析用户输入以填充此图,从而实现对场景配置的细粒度控制。
为了生成场景,作者采用了多模态图整流流(Multimodal Graph Rectified Flow)骨干网络。该模块调整了整流流模型以联合处理多种内容生成。该机制的核心是 InfoExchangeUnit,它利用三元组图卷积网络(Triplet-GCN)在图边上执行消息传递和特征聚合。在去噪过程中,该单元结合时序去噪数据 Dt,并将其与节点特征一起投影,以生成时间相关的条件 Ct。这确保了每个物体的生成都尊重图结构施加的全局约束。
训练目标是最小化预测速度场 vθ 与通过数据和噪声之间的线性插值得到的目标速度之间的最小二乘误差。损失函数定义为:
LGRF=ED,C,t[∥ΘD(Dt,Ct,t)−v∥22]其中 ΘD 是去噪网络。在推理过程中,模型从高斯噪声开始积分反向时间 ODE,以恢复目标数据分布。
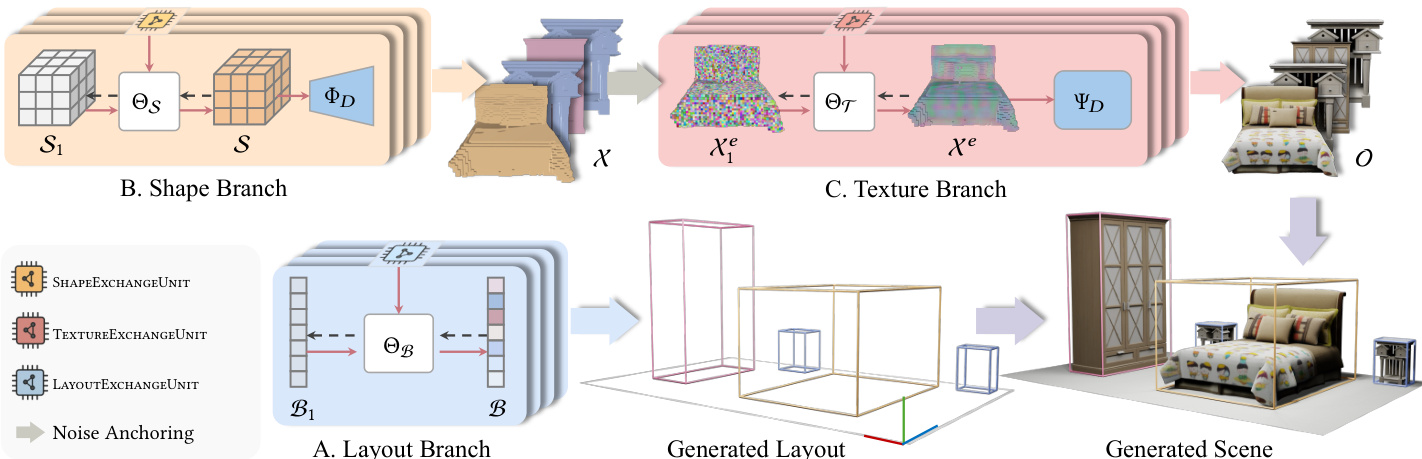
FlowScene 将生成任务分解为三个协调的分支,每个分支都由图整流流模块支持。布局分支(Layout Branch)生成由位置、大小和旋转定义的 3D 边界框,利用专门的 LayoutExchangeUnit 来强制执行空间约束。形状分支(Shape Branch)并行运行以生成体素化的物体形状。它采用 Shape VQ-VAE 将稀疏体素结构编码为紧凑的潜在代码,然后进行去噪和解码。纹理分支(Texture Branch)从属于形状分支,将高斯噪声锚定到几何结构上以生成纹理。它使用 Texture VQ-VAE 和 TextureExchangeUnit 来确保物体间的风格一致性,这对于仅包含文本的节点尤为重要,因为此类节点的外观是从关系上下文中推断出来的。
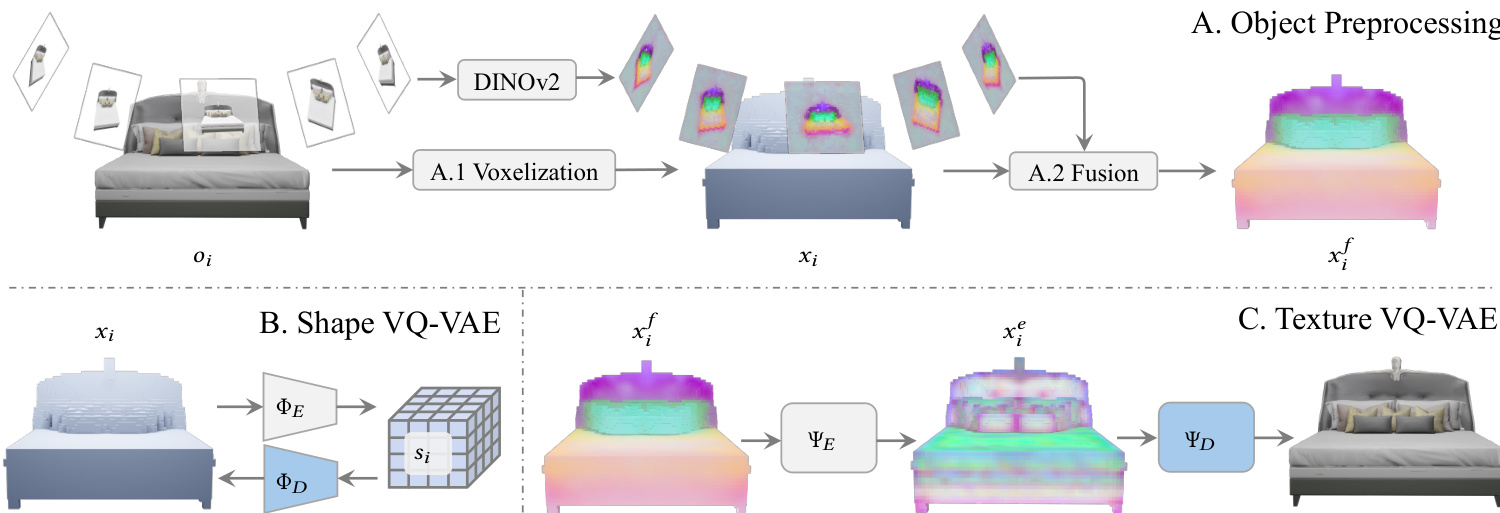
在训练生成分支之前,物体需经过预处理以准备 VQ-VAE 所需的数据。物体被体素化为稀疏结构,并渲染多视图图像以提取 DINOv2 特征。这些特征被重投影到体素网格上并取平均值以创建特征体素。Shape VQ-VAE 学习重建体素化几何结构,而 Texture VQ-VAE 学习从特征体素重建物体外观。这种预处理确保了生成模型在高效的潜在表示上运行,而不是在原始高维数据上运行。
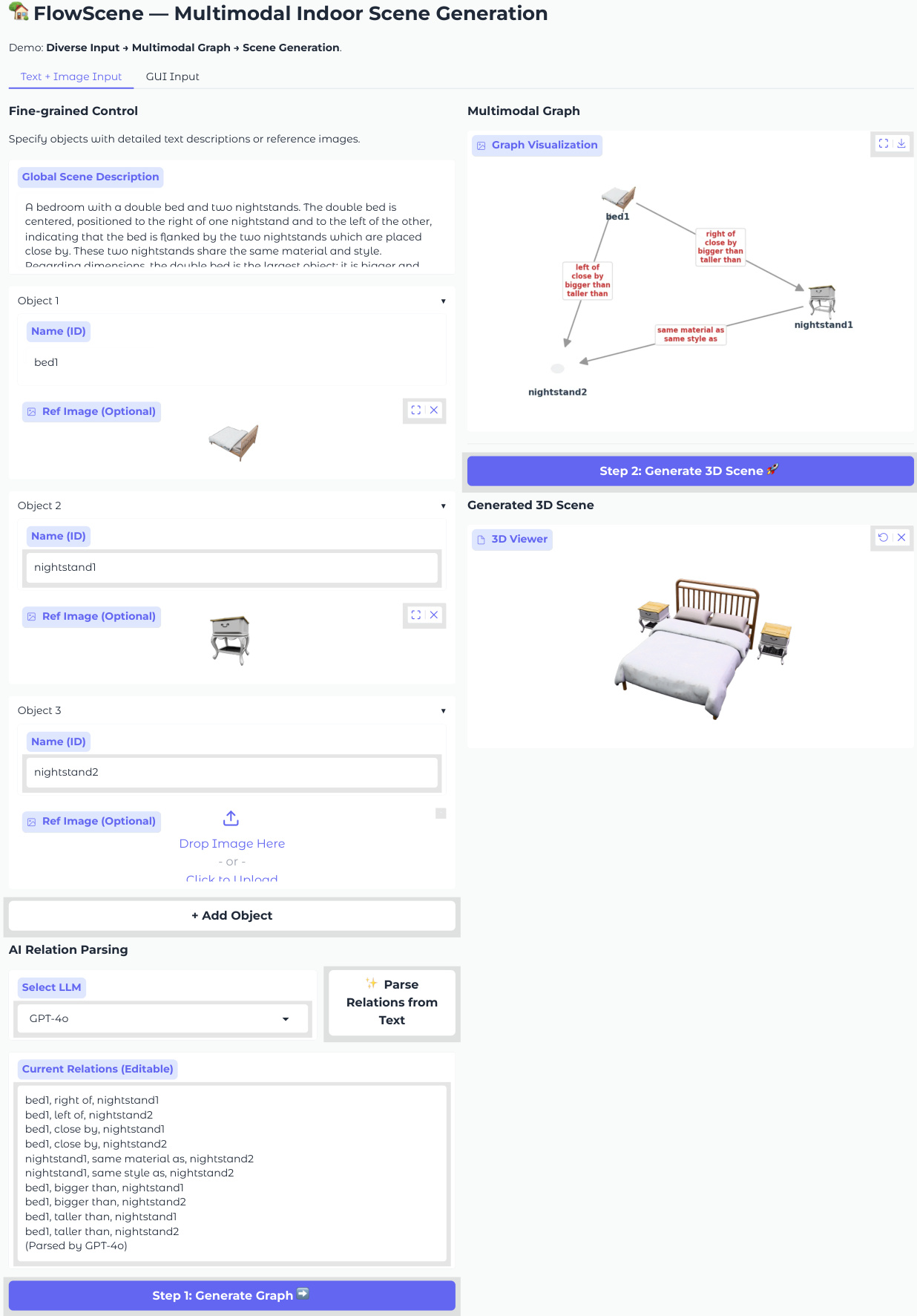
该系统支持两种主要的用户交互应用模式。在语言驱动模式下,用户提供自然语言描述,由 LLM 将其解析为场景图。在交互式 GUI 模式下,用户通过可视化界面选择物体候选项并定义关系。这两种模式都输入到多模态图中,进而驱动 FlowScene 后端生成与指定配置一致的高保真纹理 3D 场景。
实验
- 在 SG-FRONT 和 3D-FRONT 数据集上的实验验证了 FlowScene 在场景级真实感、物体级几何保真度和风格一致性方面优于免训练的语言基线方法和基于图条件的生成模型。
- 定量和定性比较表明,FlowScene 实现了与人类偏好的更好对齐,生成的场景具有更高的视觉质量,并且布局更准确地遵循文本和图约束。
- 消融实验证实,InfoExchangeUnit 对于空间一致性和外观一致性至关重要,而图流骨干网络相比扩散基线显著提升了形状生成质量。
- 鲁棒性测试表明,使用多视图输入进行训练能够灵活适应不同的视觉条件,即使输入图中的关系信息稀疏,模型仍能保持高性能。
- 额外的评估突出了 FlowScene 保持相同物体间形状一致性的能力,以及有效传播局部图更新以维持整体场景结构的能力。