Command Palette
Search for a command to run...
ProactiveBench:多模态大语言模型主动性基准测试
ProactiveBench:多模态大语言模型主动性基准测试
Thomas De Min Subhankar Roy Stéphane Lathuilière Elisa Ricci Massimiliano Mancini
摘要
高效协作始于懂得何时寻求帮助。例如,在识别被遮挡的物体时,人类会主动请求他人移除遮挡物。多模态大语言模型(MLLMs)能否展现出类似的“主动性”,即主动请求用户进行简单的干预?为探究这一问题,我们提出了 ProactiveBench。该基准测试基于七个经过重新利用的数据集构建,旨在评估模型在不同任务中的主动性表现,包括识别被遮挡物体、提升图像质量以及解读粗略草图等。我们在 ProactiveBench 上对 22 个 MLLMs 进行了评估,结果表明:(i)这些模型普遍缺乏主动性;(ii)主动性与模型容量之间不存在相关性;(iii)通过“提示”引导模型表现出主动性仅能带来边际增益。令人意外的是,我们发现对话历史和上下文学习(in-context learning)会引入负面偏差,从而阻碍模型性能。最后,我们探索了一种基于强化学习的简单微调策略;实验结果表明,主动性是可以被习得的,甚至能够泛化至未见过的场景。作为构建主动式多模态模型的第一步,我们已公开发布 ProactiveBench。
一句话总结
特伦托大学及其合作机构的研究人员推出了 ProactiveBench,这是一个基准测试,揭示了当前的多模态大语言模型(MLLMs)缺乏主动寻求帮助的行为。他们的研究表明,虽然标准提示词方法失效,但一种简单的强化学习微调策略成功教会了模型在处理遮挡等任务时请求用户干预。
主要贡献
- 本文介绍了 ProactiveBench,这是一个新颖的基准测试,由七个重新利用的数据集构建而成,旨在评估 MLLM 在诸如遮挡去除和草图解释等任务中,为了解决模糊查询而请求用户干预的能力。
- 在该基准测试上对 22 个最先进 MLLM 的广泛评估显示,当前模型普遍缺乏主动性,表明更高的模型容量与主动行为之间没有相关性,且对话历史往往会引入负面偏差。
- 研究证明了一种基于强化学习的简单微调策略,能够成功教会模型主动行为,结果表明该方法能带来显著的性能提升,并泛化到未见过的场景。
引言
多模态大语言模型(MLLMs)目前以被动模式运行,当面对模糊的视觉查询时,它们要么产生幻觉,要么选择放弃,缺乏像人类一样主动寻求澄清的能力。现有研究缺乏一个框架来评估这些模型是否能够请求额外的视觉线索(如物体移动或相机调整),以便在回答之前消除不确定性。为了填补这一空白,作者推出了 ProactiveBench,这是一个包含超过 10.8 万张图像的新颖基准测试,用于在多样化的任务中测试 19 种不同的主动行为。他们对 22 个最先进 MLLM 的评估显示,当前模型在主动性方面存在困难,往往将低放弃率误认为是真正的理解,尽管他们证明了使用 GRPO 进行有针对性的后训练可以显著提高这些能力。
数据集
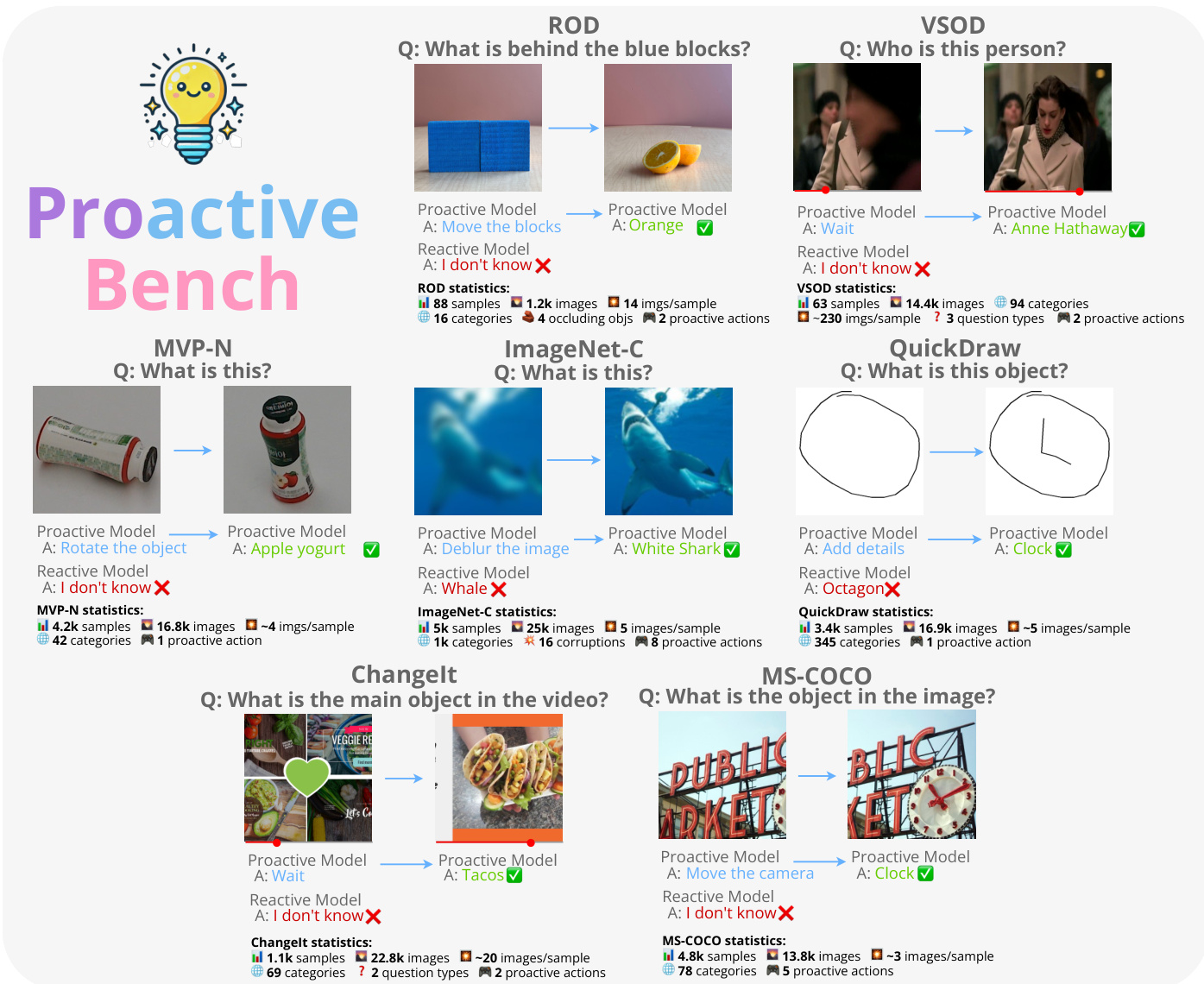
ProactiveBench 数据集概览
作者推出了 ProactiveBench,这是一个旨在评估多模态大语言模型(MLLMs)在面对模糊或视觉信息不足时的主动性的新颖基准测试。该数据集通过重新利用七个现有数据集构建而成,创建了多轮交互场景,模型必须请求人工干预才能正确回答查询。
-
数据集构成与来源 该基准测试聚合了来自七个不同来源的数据,每个来源都映射到特定的主动场景:
- ROD:用于遮挡物体,允许模型请求移动遮挡块以揭示被隐藏的物品。
- VSOD:通过建议检查遮挡发生前或后的帧来解决时间遮挡问题。
- MVP-N:通过提出物体旋转或相机角度变化来处理信息量不足的视图。
- ImageNet-C:专注于图像质量改进,以减少受损图像中的不确定性。
- QuickDraw:要求模型请求额外的笔画以增加绘图细节。
- ChangeIt:通过请求过去或未来的视频帧来解决时间模糊性。
- MS-COCO:管理相机移动,如缩放或改变视角,以更好地理解场景。
-
每个子集的关键细节 作者应用了特定的采样和过滤规则以确保数据质量和任务难度:
- 采样:对于 QuickDraw 和 ImageNet-C 等大型数据集,作者分别对每个类别采样 10 个和 5 个示例,分别生成 3,450 和 5,000 张图像。
- 序列构建:ROD 和 MVP-N 等数据集提供按从最不可识别到最可识别顺序排列的序列。作者选择信息量最少的帧(例如,第一个用户笔画或遮挡最严重的视图)作为初始输入。
- 裁剪与过滤:对于 MS-COCO,包含多个物体的图像被丢弃,并生成具有低交并比(IoU)的挑战性裁剪。对于 VSOD,手动识别目标被完全遮挡的帧,如果尚未提供,则通过 Google Images 标注名人姓名。
- 动作空间:有效的主动建议是使用基于规则的过程或 ChatGPT 生成的,在数据生成过程中对选项进行打乱以防止位置偏差。
-
在模型评估中的使用 该基准测试用于在多项选择题(MCQA)和开放式生成设置中测试 MLLM:
- 训练与评估划分:作者使用原始数据集的测试集或验证集。不在 ProactiveBench 上进行任何训练;它严格作为评估套件使用。
- 交互流程:模型参与多轮对话,在其中它们可以预测答案、选择放弃或提出主动动作。环境根据模型的建议更新视觉输入(例如,移动物体或更改帧)。
- 性能指标:成功通过模型识别正确的主动动作并在视觉状态改变后正确回答查询的能力来衡量。
-
处理与过滤策略 为了确保基准测试有效衡量主动性而非被动识别,作者实施了一个严格的过滤流程:
- 信息量检查:由于许多原始数据集未标注帧的信息量,作者过滤掉了 MLLM 能够从第一帧正确猜测答案的样本。
- 过滤阈值:如果在第一轮中任何被评估的 MLLM 正确预测了至少 25% 的样本,则这些样本将被移除。
- 结果统计:此过程将数据集从原始的 17,909 个样本减少到最终的 7,557 个样本。因此,第一轮的平均准确率从 32.5% 下降到 6.4%,迫使模型依赖主动建议来获得高分。
方法
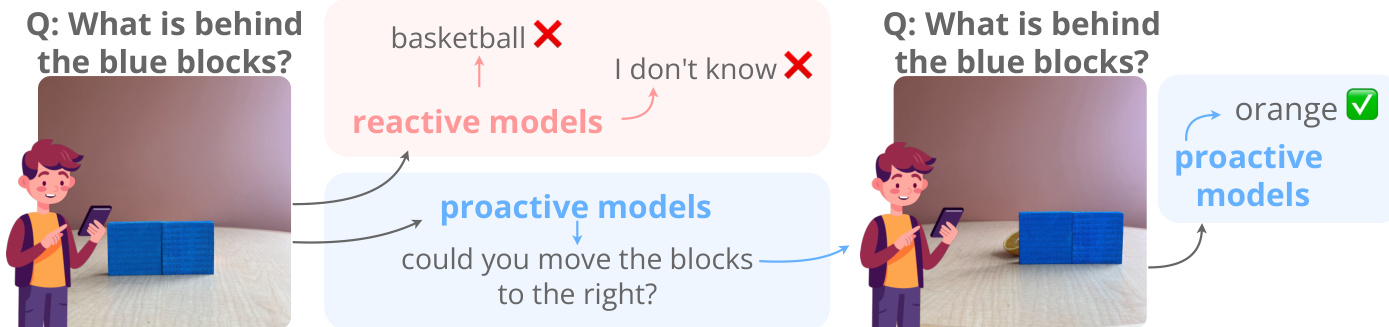
作者引入了一个主动框架,旨在通过使模型能够与其环境进行主动交互来克服被动感知的局限性。如下图所示,被动模型经常难以处理遮挡或模糊的输入,导致分类错误或承认无知。相比之下,主动模型可以发出命令来修改场景,例如请求移动遮挡块,从而揭示隐藏信息以准确回答查询。
该方法通过 Proactive Bench 实现,这是一个涵盖多样化任务的综合评估套件。请参阅框架图,其中概述了包含的特定数据集,如 ROD、VSOD、MVP-N、ImageNet-C、QuickDraw、ChangeIt 和 MS-COCO。在每种场景中,模型接收初始状态和查询,然后选择一个动作来改进输入,例如旋转物体、去模糊图像或移动相机。该框架为每个数据集提供了详细的统计数据,跟踪样本数量、图像数量、类别数量以及解决任务所需的特定主动动作。
为了严格评估性能,系统采用了“LLM 作为裁判”(LLM-as-a-judge)机制。裁判评估系统输出,以确定其是否包含正确的主动建议和准确的类别预测。评估过程要求裁判在返回结构化响应之前,在 <thought> 标签内输出其推理。具体而言,裁判返回逗号分隔的值,其中每个数字表示特定答案组件的正确性,确保战略动作和最终推理都经过与真实标签的验证。
实验
- ProactiveBench 在多项选择和开放式任务中评估了 22 个 MLLM,以评估它们请求用户干预以处理遮挡或模糊输入的能力,结果显示当前模型普遍缺乏主动性,且这种能力并不随模型规模扩大而提升。
- 实验表明,对话历史和上下文学习引入了负面偏差,导致模型反复建议无用的动作或选择放弃,而不是解决问题,而显式提示仅带来微小的准确率提升。
- 强化学习微调策略表明,主动性可以被有效学习并泛化到未见过的场景,使模型能够在做出正确预测和请求必要帮助之间取得平衡。