Command Palette
Search for a command to run...
LeWorldModel:基于像素的稳定端到端联合嵌入预测架构
LeWorldModel:基于像素的稳定端到端联合嵌入预测架构
Lucas Maes Quentin Le Lidec Damien Scieur Yann LeCun Randall Balestriero
摘要
联合嵌入预测架构(JEPAs)为在紧凑的潜在空间中学习世界模型提供了一个极具吸引力的框架,然而现有方法仍显脆弱,往往依赖复杂的多项损失函数、指数移动平均、预训练编码器或辅助监督信号,以避免表征坍塌。在本工作中,我们提出了 LeWorldModel(LeWM),这是首个仅通过两项损失函数即可从原始像素端到端稳定训练的 JEPAs:一项为下一嵌入预测损失,另一项为强制潜在嵌入服从高斯分布的正则化项。与目前唯一可行的端到端替代方案相比,LeWM 将可调节的损失超参数数量从六个减少至一个。LeWM 仅需 1500 万参数,即可在单块 GPU 上于数小时内完成训练;其规划速度比基于基础模型的世界模型快达 48 倍,同时在多种二维与三维控制任务中仍保持竞争力。除控制任务外,我们进一步表明,通过对物理量的探测分析,LeWM 的潜在空间能够编码有意义的物理结构。惊喜度评估结果证实,该模型能够可靠地检测出物理上不合理的事件。
一句话总结
来自 Mila、NYU 和 Samsung SAIL 的研究人员提出了 LeWorldModel,这是一种联合嵌入预测架构,仅使用两个损失项即可从原始像素稳定地进行端到端训练,消除了对复杂损失和预训练编码器的需求,同时在单个 GPU 上实现高达 48 倍的规划速度提升,并能在多种控制任务中可靠地检测物理上不合理的事件。
核心贡献
- 本文介绍了 LeWorldModel (LeWM),这是一种联合嵌入预测架构,仅使用两个损失项即可从原始像素稳定地进行端到端训练。与现有的唯一端到端替代方案相比,该方法将可调损失超参数从六个减少到一个。
- 该方法规划速度比基于基础模型的世界模型快 48 倍,同时在多种 2D 和 3D 控制任务中保持竞争力。这种效率是通过 1500 万参数实现的,可在单个 GPU 上在几小时内完成训练,无需依赖指数移动平均或预训练编码器。
- 潜在空间编码了有意义的物理结构,这通过对模型内物理量的探测得以证明。惊喜评估确认,该系统能够可靠地检测标准控制基准之外的物理上不合理的事件。
引言
世界模型使代理能够利用直接从原始感官输入(如相机像素)学习到的内部模拟进行规划。尽管联合嵌入预测架构(JEPAs)为此任务提供了紧凑的框架,但先前的方法通常遭受表示崩溃,并需要复杂的稳定启发式或预训练编码器。作者介绍了 LeWorldModel,这是第一个仅使用预测损失和高斯正则化器就能从像素端到端稳定训练的 JEPA。这种方法消除了启发式训练技巧,减少了超参数调整,并能够在单个 GPU 上实现高效规划,同时捕捉有意义的物理结构。
数据集
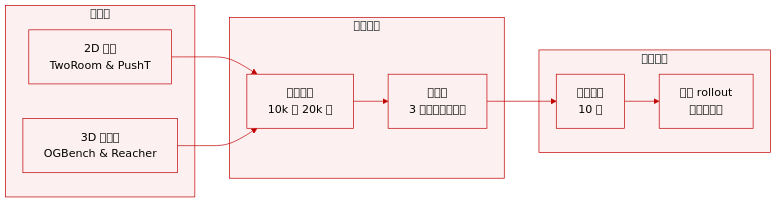
作者使用以下数据集在四个连续控制环境中评估了他们世界模型:
-
TwoRoom: 来自 Sobal 等人的 2D 导航任务,代理在两个房间之间移动。数据集包含 10,000 个回合,平均 92 步,由启发式策略生成,引导代理通过门到达目标。
-
PushT: 来自 Zhou 等人的 2D 操作任务,要求代理将 T 形块推至目标配置。此子集包含 20,000 个专家回合,平均长度为 196 步。
-
OGBench-Cube: 来自 Park 等人的 3D 机器人操作任务,限于用于抓取放置操作的单立方体变体。作者收集了 10,000 个 200 步的回合,使用基准库启发式。
-
Reacher: 来自 DeepMind Control Suite 的连续控制环境,涉及双关节臂在 2D 平面中到达目标。数据集由通过 Soft Actor-Critic 策略收集的 10,000 个 200 步回合组成。
-
训练与处理: 每个世界模型都在这些数据集上训练 10 个 epoch。对于预测器展开,三个上下文帧被编码为潜在表示,以自回归方式生成以动作为条件的未来状态,预测由训练期间未使用的单独解码器解码。
方法
LeWorldModel (LeWM) 作为一种联合嵌入预测架构运行,旨在从离线、无奖励数据中学习任务无关的世界模型。该框架包含两个主要组件:将原始像素观察映射到紧凑潜在空间的编码器,以及通过预测以动作为条件的未来潜在嵌入来建模环境动态的预测器。
训练过程涉及处理观察和动作序列以端到端地更新模型参数。编码器实现为 Vision Transformer (ViT),处理输入帧 ot 以产生潜在嵌入 zt。该嵌入源自最后一层的 [CLS] 标记,通过带有批归一化的投影 MLP 以优化。预测器是 Transformer 架构,利用自适应层归一化 (AdaLN) 进行动作条件化,接受当前潜在状态 zt 和动作 at 以预测下一个状态嵌入 z^t+1。
为了确保学习到的表示具有信息量且稳定,训练目标将预测损失与正则化项相结合。预测损失 Lpred 最小化预测嵌入与下一个时间步真实嵌入之间的均方误差:
Lpred≜∥z^t+1−zt+1∥22
然而,仅依赖预测可能导致表示崩溃。为了防止这种情况,作者引入了草图各向同性高斯正则化器(SIGReg)。如下所示:
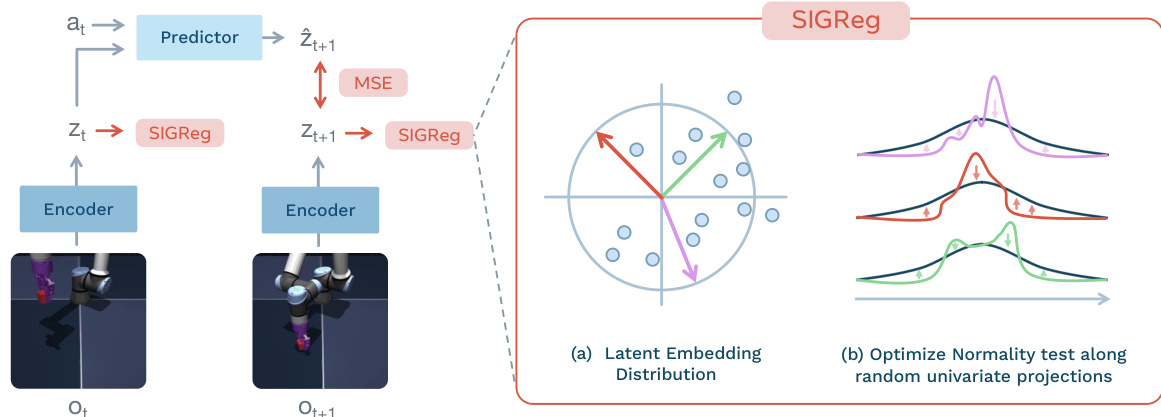 该模块鼓励潜在嵌入匹配各向同性高斯目标分布。直接在高维中测试正态性是困难的,因此 SIGReg 将嵌入投影到随机单位范数方向上,并优化这些投影上的单变量 Epps-Pulley 检验统计量。根据 Cramér–Wold 定理,匹配这些一维边缘分布确保完整联合分布匹配目标。总损失定义为:
LLeWM≜Lpred+λSIGReg(Z)
其中 λ 是正则化权重,Z 代表潜在嵌入张量。
该模块鼓励潜在嵌入匹配各向同性高斯目标分布。直接在高维中测试正态性是困难的,因此 SIGReg 将嵌入投影到随机单位范数方向上,并优化这些投影上的单变量 Epps-Pulley 检验统计量。根据 Cramér–Wold 定理,匹配这些一维边缘分布确保完整联合分布匹配目标。总损失定义为:
LLeWM≜Lpred+λSIGReg(Z)
其中 λ 是正则化权重,Z 代表潜在嵌入张量。
在推理时,LeWM 利用学习到的动态通过潜在规划进行决策,使用模型预测控制 (MPC)。规划过程如下图所示:
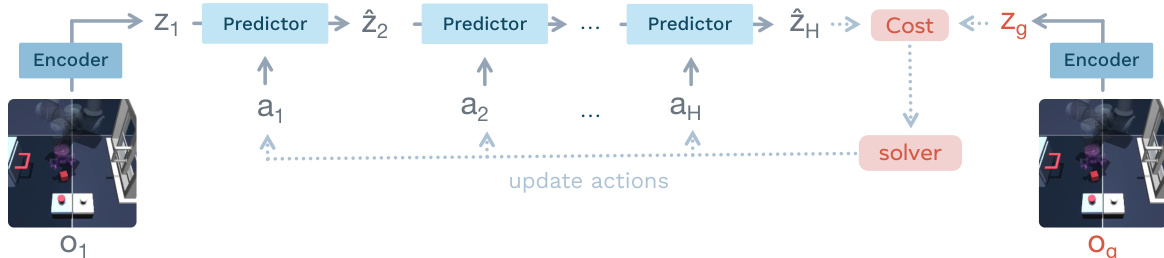 给定初始观察,系统将其编码为潜在状态,并使用预测器在时域 H 上迭代展开预测的潜在状态。基于最终预测潜在状态 z^H 与目标观察的潜在嵌入 zg 之间的距离计算代价函数。优化求解器,特别是交叉熵方法 (CEM),用于找到最小化该终端代价的动作序列。为了减轻长时域上的误差累积,采用滚动时域策略,在执行前几个规划动作之前,从更新后的观察重新规划。
给定初始观察,系统将其编码为潜在状态,并使用预测器在时域 H 上迭代展开预测的潜在状态。基于最终预测潜在状态 z^H 与目标观察的潜在嵌入 zg 之间的距离计算代价函数。优化求解器,特别是交叉熵方法 (CEM),用于找到最小化该终端代价的动作序列。为了减轻长时域上的误差累积,采用滚动时域策略,在执行前几个规划动作之前,从更新后的观察重新规划。
实验
LeWM 在多样化和三维环境中的导航和操纵任务中与 PLDM 和 DINO-WM 等基线进行了评估。结果表明,与复杂的多项目标相比,该方法实现了显著的规划加速和更稳定的训练收敛,同时通过潜在表示有效地捕捉潜在物理量。尽管由于正则化不匹配,在低复杂度设置中性能有所下降,但该模型通过检测预期动态的违反而无需显式时间正则化,展示了稳健的物理理解。
作者分析了用 ResNet-18 主干替换默认 Vision Transformer 编码器的影响。结果表明,虽然 ViT 架构产生了稍好的性能,但 ResNet-18 变体仍然具有竞争力,表明该方法对视觉编码器的选择是稳健的。ViT 编码器实现比 ResNet-18 更高的成功率,ResNet-18 主干保持有竞争力的规划性能,方法性能在很大程度上与编码器架构无关。

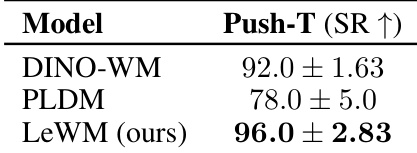
作者使用成功率作为指标评估 Push-T 任务上的规划性能。LeWM 实现了顶级性能,超过了 DINO-WM 和 PLDM。结果突出了所提出方法有效捕捉任务相关量的能力。LeWM 在所有测试模型中实现了最高的成功率,PLDM 表现出比其他人更低的性能和更大的方差,所提出方法仅使用像素观察就优于 DINO-WM。
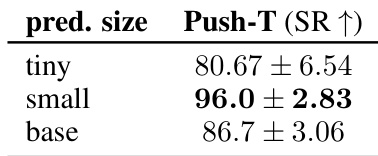
作者分析了预测器容量对 Push-T 环境中规划性能的影响。结果表明,小型预测器配置优于更小和更大的模型变体。这表明小规模提供了容量和优化稳定性之间的最佳权衡。小型预测器尺寸实现了最高的成功率,较小的模型变体导致较低的性能分数,较大的模型配置未提供额外收益。
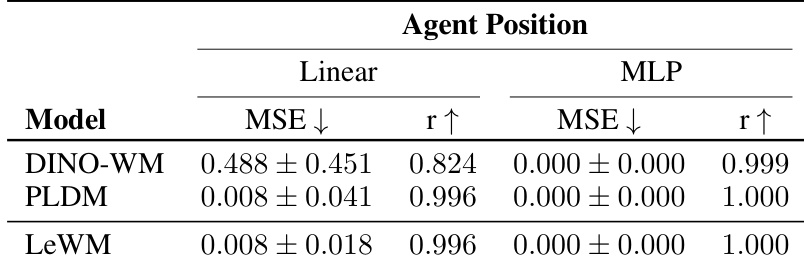
该表比较了不同模型使用线性和非线性探测编码代理位置信息的能力。LeWM 和 PLDM 表现出比 DINO-WM 显著更好的线性探测性能,而所有模型在线性探测上实现了近乎完美的结果。LeWM 和 PLDM 在线性探测上实现了相似的性能,两种方法在线性指标上显著优于 DINO-WM,非线性探测对所有模型产生近乎完美的结果。
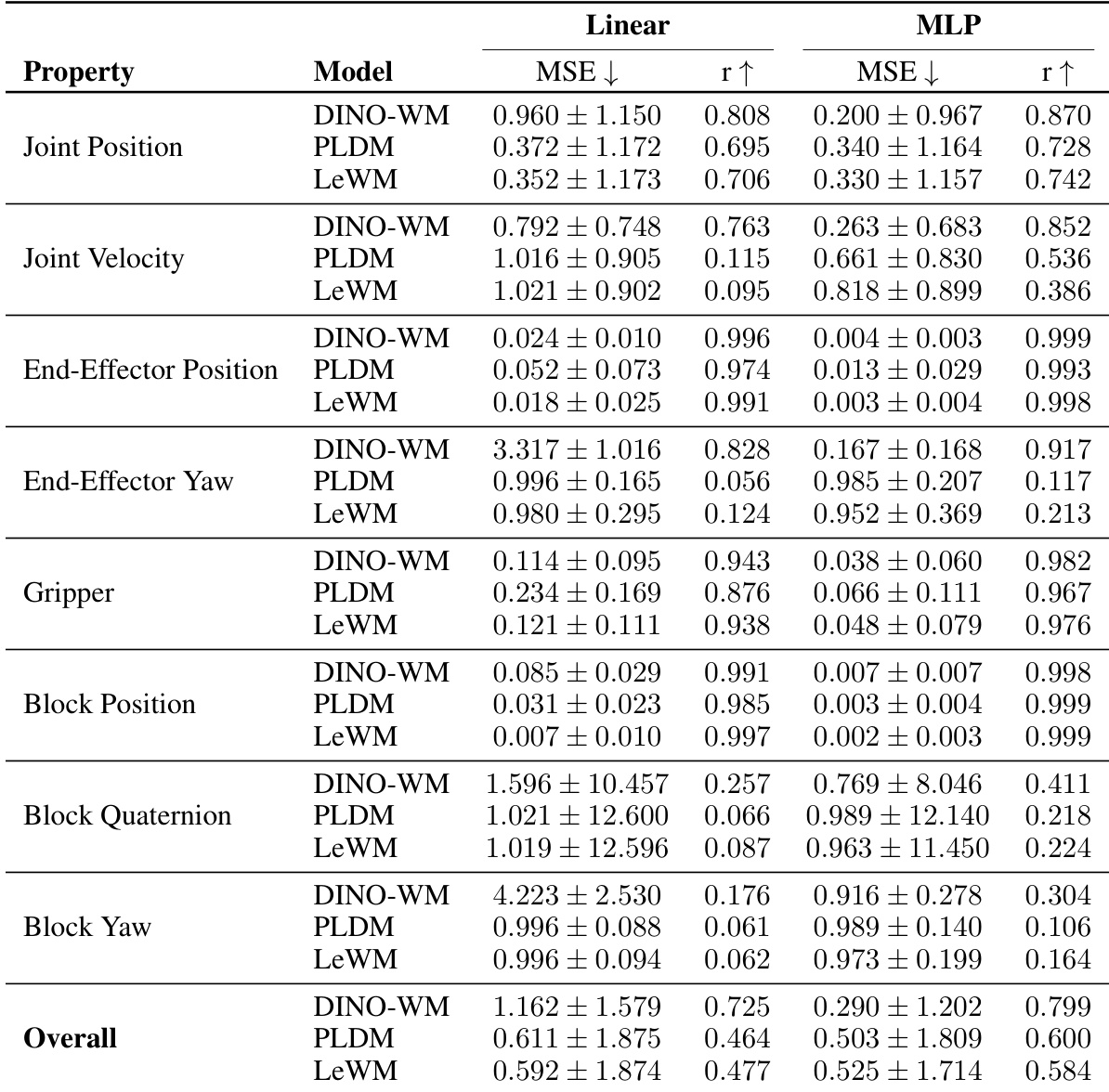
作者通过探测位置和速度等量的潜在表示来评估 LeWM 的物理理解能力。结果表明,LeWM 通常优于 PLDM 基线,并与预训练的 DINO-WM 模型保持竞争力,特别是对于位置属性。LeWM 在大多数物理属性上实现了比 PLDM 更低的预测误差,非线性 MLP 探测在恢复物理量方面始终优于线性探测,位置属性(如块位置)的恢复精度显著高于旋转属性。
实验评估了所提出方法在 Push-T 任务上的鲁棒性和规划能力,表明性能在不同视觉编码器架构之间保持竞争力。LeWM 实现了优于基线的规划成功率,而消融研究表明,小型预测器配置提供了容量和优化稳定性之间的最佳平衡。此外,探测分析证实,该模型有效地编码了代理位置和物理量,在线性探测上优于竞争对手,并以高精度恢复位置属性。