Command Palette
Search for a command to run...
SAMA:面向指令驱动视频编辑的因子化语义锚定与运动对齐
SAMA:面向指令驱动视频编辑的因子化语义锚定与运动对齐
摘要
当前的指令引导式视频编辑模型难以在精确的语义修改与忠实的运动保持之间实现有效平衡。现有方法通常依赖注入显式的外部先验(如 VLM 特征或结构条件)来缓解上述问题,但这种依赖严重制约了模型的鲁棒性与泛化能力。为克服这一局限,我们提出了 SAMA(解耦语义锚定与运动对齐,Semantic Anchoring and Motion Alignment),该框架将视频编辑任务解耦为语义锚定与运动建模两个独立模块。首先,我们引入语义锚定(Semantic Anchoring)机制,通过在稀疏的锚定帧上联合预测语义 tokens 和视频 latents,构建可靠的视觉锚点,从而实现仅依赖指令的结构规划。其次,运动对齐(Motion Alignment)模块通过在以运动为核心的视频修复预训练任务(包括立方体修复、速度扰动和管状序列混洗)中对同一主干网络进行预训练,使模型能够直接从原始视频中内化时间动态特性。SAMA 采用两阶段优化流程:第一阶段为解耦预训练,在无成对的“视频 - 指令”编辑数据的情况下学习固有的语义 - 运动表征;第二阶段为基于成对编辑数据的监督微调。值得注意的是,仅凭解耦预训练阶段,SAMA 已展现出强大的零样本视频编辑能力,充分验证了所提出解耦策略的有效性。在开源模型中,SAMA 取得了最先进(state-of-the-art)的性能,并与领先的商业系统(如 Kling-Omni)具有竞争力。相关代码、模型及数据集即将公开。
一句话总结
来自百度、清华大学等机构的研究人员提出了 SAMA,这是一个将视频编辑分解为语义锚定和运动对齐的框架。通过在无配对数据的情况下针对以运动为中心的恢复任务进行预训练,SAMA 在避免依赖外部先验的先前方法所面临的鲁棒性瓶颈的同时,实现了最先进的零样本性能。
主要贡献
- 本文介绍了 SAMA,这是一个将视频编辑分解为语义锚定和运动建模的框架,旨在减少对外部显式先验(如 VLM 特征或结构条件)的依赖。
- 语义锚定通过在稀疏帧上联合预测语义令牌和视频潜在变量来建立可靠的视觉锚点;而运动对齐则通过在以运动为中心的恢复任务上预训练骨干网络,从原始视频中内化时间动态。
- 实验表明,所提出的两阶段训练流程产生了强大的零样本编辑能力,在开源模型中达到了最先进的性能,可与领先的商业系统相媲美。
引言
指令引导的视频编辑旨在应用细粒度的语义变化,同时保持运动的时间连贯性,然而当前模型难以平衡这些相互竞争的需求。先前的方法通常依赖注入显式外部先验(如骨架或深度图),这限制了扩散骨干网络学习固有的语义 - 运动表示,并导致伪影或编辑效果被稀释。作者提出了 SAMA,该框架通过引入用于指令感知结构规划的语义锚定和用于通过以运动为中心的预训练内化时间动态的运动对齐,将语义规划与运动建模解耦。这种两阶段策略使模型能够在不过度依赖脆弱的外部信号的情况下,在开源系统中实现最先进的性能。
数据集
-
数据集构成与来源:作者整理了一个用于图像和视频编辑的混合数据集,图像编辑任务的数据来源于 NHR-Edit、GPT-image-edit、X2Edit 和 Pico-Banana-400K。对于视频编辑,他们利用了 Ditto-1M、OpenVE-3M 和 ReCo-Data,并专门结合 Koala-36M 和 MotionBench 用于文本到视频生成中的前置运动对齐。
-
子集过滤与选择:所有数据均经过基于 VLM 的粗过滤阶段,使用 Qwen2.5-VL-72B 在 1–10 的尺度上对样本进行评分,指标包括指令遵循、视觉质量、内容保留和运动一致性。作者应用了严格的阈值,保留前三个指标得分在 9 或以上的图像样本,以及大多数指标得分在 8 或以上且运动一致性得分高于 8 的视频样本。选择了特定的子集,包括仅从 Ditto-1M 中选择“风格”类别,以及从 OpenVE-3M 中选择“局部变化”、“背景”、“风格”和“字幕”类别。
-
训练策略与混合比例:模型在混合图像和视频数据上进行两阶段训练,分辨率为 480p,支持多种宽高比。对于文本到视频数据,作者采用 1:2:3:4 的采样比例,分别对应无前置任务、立方体修复、速度扰动和管状洗牌。立方体修复使用 30% 的掩码比例,速度扰动应用 2 倍时间加速,管状洗牌将视频划分为 2x2x2 的时空管进行随机洗牌。
-
处理与配置细节:在训练期间,作者均匀采样 N 个稀疏锚帧用于语义锚定,为效率起见将 N 设为 1,并将每个锚帧的局部语义令牌数量固定为 64。他们保持模型参数的指数移动平均,衰减率为 0.9998,并将损失权重 lambda 设为 0.1。评估在 VIE-Bench、OpenVE-Bench 和 ReCo-Bench 上进行,使用不同的 VLM 评判器(如 GPT-4o 和 Gemini-2.5-Pro)进行评分。
方法
作者提出了 SAMA,这是一个基于 Wan2.1-T2V-14B 视频扩散 Transformer 构建的框架。其核心理念是将视频编辑分解为语义锚定和运动建模,以平衡精确的语义修改与忠实的运动保持。整体架构和训练流程如下图所示。
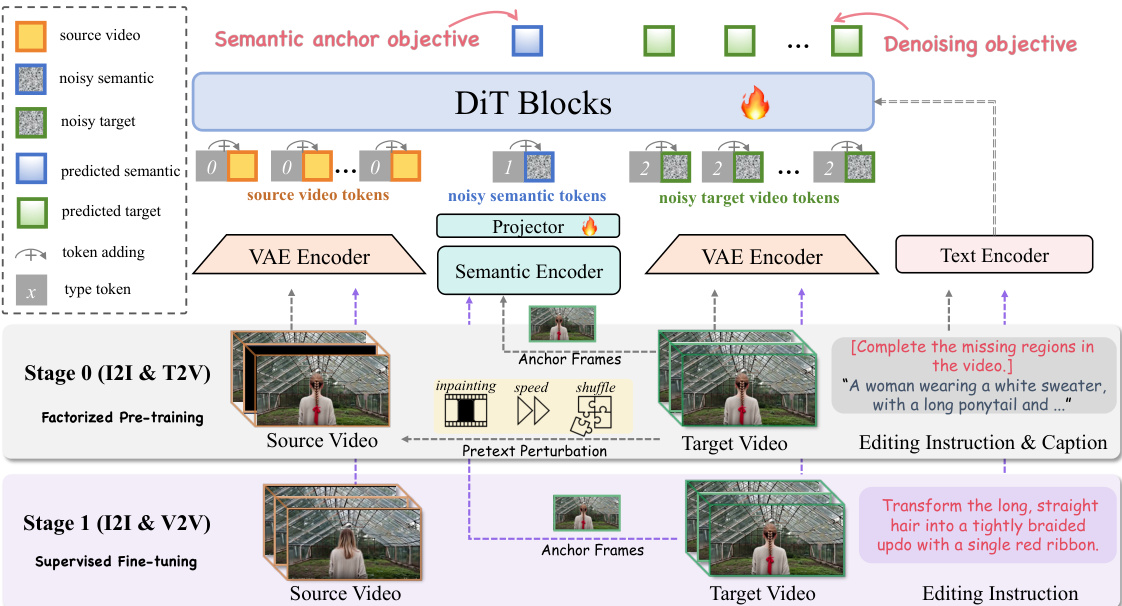
该方法将源视频和目标视频编码为 VAE 潜在变量,分别记为 zs 和 zt。将它们拼接形成上下文 V2V 输入 z=[zs;zt]。为了区分令牌角色,添加了学习到的类型嵌入:源视频潜在变量使用类型 ID 0,目标视频潜在变量使用类型 ID 2,语义令牌使用类型 ID 1。与移位 RoPE 方案相比,这种方法被观察到能带来更快的收敛速度。
语义锚定(SA)建立可靠的视觉锚点。对于视频样本,均匀采样 N 帧作为锚帧。SigLIP 图像编码器提取块级语义特征,并将其池化为局部和全局令牌。这些特征通过轻量级 MLP 投影到 VAE 潜在空间。投影后的语义令牌 s^ 被添加到目标潜在序列的开头。语义令牌和目标潜在变量均经历前向加噪过程。模型通过附加在最终 DiT 层上的头来预测语义令牌 s。目标是最小化 ℓ1 损失: Lsem=∥s^−s∥1 总损失结合了流匹配和语义锚定:L=LFM+λ⋅Lsem。
运动对齐(MA)使编辑后的视频与源运动动态保持一致。它仅对源视频 Vs 应用以运动为中心的变换 T 以创建扰动版本 V~s,同时保持目标视频不变。这迫使模型学习运动恢复。具体的前置扰动细节如下图所示。

这三种变换包括立方体修复(掩码时间块)、速度扰动(加速播放)和管状洗牌(置换时空管)。任务令牌被添加到指令前以统一公式(例如,“[完成视频中缺失的区域。]")。
SAMA 采用两阶段流程。阶段 0 是解耦预训练,模型在此阶段学习固有的语义 - 运动表示,无需配对编辑数据。SA 应用于图像和视频样本,而 MA 应用于视频流。阶段 1 是在配对视频编辑数据集上的监督微调(SFT)。在此阶段,模型在保持 SA 启用以维持稳定语义锚定的同时,使生成与配对监督保持一致。
实验
- 与最先进方法的比较验证了 SAMA 在交换、更改和移除任务上实现了卓越的总体性能,展示了比现有模型更强的指令遵循能力、对细粒度空间和属性约束的更好处理能力,以及改进的时间一致性。
- 零样本评估证实,该模型可以在没有特定训练数据的情况下执行多样化的编辑任务,但也表现出一些局限性,如时间颜色不一致、添加物体模糊以及移除编辑中的残留重影。
- 消融研究表明,语义锚定加速了模型收敛并稳定了训练,而运动对齐显著增强了时间连贯性并减少了快速相机运动期间的运动模糊,这两个组件被证明是互补的。
- 以运动为中心的前置任务的可视化表明,模型成功内化了运动线索和时间推理,这直接支持了高质量的指令引导视频编辑。