Command Palette
Search for a command to run...
FASTER:重新思考实时流式视觉语言动作模型
FASTER:重新思考实时流式视觉语言动作模型
Yuxiang Lu Zhe Liu Xianzhe Fan Zhenya Yang Jinghua Hou Junyi Li Kaixin Ding Hengshuang Zhao
摘要
实时执行对于将视觉 - 语言 - 动作(Vision-Language-Action, VLA)模型部署至物理世界至关重要。现有的异步推理方法主要侧重于优化轨迹平滑度,却忽视了在响应环境变化时至关重要的延迟问题。本文通过重新审视动作分块策略(action chunking policies)中的“反应”概念,对决定反应时间的关键因素进行了系统性分析。研究表明,反应时间服从由首动作时间(Time to First Action, TTFA)与执行视界(execution horizon)共同决定的均匀分布。此外,我们揭示出:在基于流的 VLA 中采用恒定调度(constant schedule)的标准做法效率低下,它迫使系统在完成所有采样步骤之前无法启动任何运动,从而构成了反应延迟的瓶颈。为解决这一问题,我们提出了面向即时反应的快速动作采样方法(Fast Action Sampling for ImmediaTE Reaction, FASTER)。通过引入一种视界感知调度(Horizon-Aware Schedule),FASTER 在流采样过程中自适应地优先处理近期动作,将即时反应的去噪过程压缩十倍(例如在 π_{0.5} 和 X-VLA 模型中),仅需单步即可完成,同时保持了长视界轨迹的质量。结合流式客户端 - 服务器流水线,FASTER 显著降低了真实机器人上的有效反应延迟,尤其在消费级 GPU 部署场景下效果尤为突出。包括高度动态的乒乓球任务在内的真实世界实验表明,FASTER 为通用策略解锁了前所未有的实时响应能力,使其能够迅速生成准确且平滑的轨迹。
一句话总结
香港大学与 ACE Robotics 的研究人员提出了 FASTER,这是一种基于流的视觉 - 语言 - 动作(VLA)模型的即插即用方法,它采用“地平线感知调度”(Horizon-Aware Schedule)将即时动作采样压缩为单步。这一创新克服了恒定时间步策略的延迟瓶颈,使系统能够在乒乓球等动态任务中实现实时响应,且无需改变架构。
主要贡献
- 本文对动作分块 VLA 策略中的反应属性进行了系统分析,揭示了反应时间服从均匀分布,并指出了恒定时间步调度如何造成延迟瓶颈。
- 这项工作引入了 FASTER,一种利用地平线感知调度在流匹配过程中自适应地优先处理近期动作的方法,它将首次动作时间(Time to First Action)压缩为单次采样步,同时保持了长程轨迹的质量。
- 作者设计了一种带有早期停止功能的流式客户端 - 服务器接口,能够立即分发初始动作,显著降低了有效反应延迟,并提高了真实机器人上的推理 - 执行循环频率。
引言
在动态物理环境中部署视觉 - 语言 - 动作(VLA)模型需要实时响应能力,然而当前的基于流的策略由于僵化的恒定时间步调度而遭受高反应延迟的困扰,这种调度迫使系统在完成所有采样步骤之前无法执行任何动作。虽然先前的异步方法成功消除了分块间的停顿以改善运动平滑度,但它们未能解决应对环境突变时的关键延迟问题,因为它们仍然需要完整的去噪周期来处理即时动作。作者提出了 FASTER,这是一种即插即用解决方案,采用地平线感知调度自适应地优先处理近期动作,将即时反应的采样压缩为单步,同时保持长程轨迹质量。通过将这种算法加速与流式客户端 - 服务器管道相结合,FASTER 将首次动作时间缩短了十倍,并能够在消费级 GPU 上实现鲁棒的实时控制,而无需进行架构修改或额外训练。
数据集
-
数据集构成与来源 作者使用了两个主要的仿真基准:LIBERO 和 CALVIN。LIBERO 通过四个任务套件(空间、物体、目标和长程)针对不同的具身能力,而 CALVIN 则专注于具有无约束语言指令的多样化操作技能。
-
各子集的关键细节
- LIBERO:包含四个套件,每个套件有 10 个任务,每个任务评估 50 次试验。作者使用转换为 LeRobot 格式的 OpenVLA 数据集来训练 π0.5,并使用 X-VLA 作者提供的 HDF5 格式数据集来训练 X-VLA,以对齐 EE6D 动作空间。
- CALVIN:包含 34 个任务,在 ABC→D 设置下使用 LeRobot 格式数据集进行评估。评估涉及 1,000 个独特的指令链,每个链由五个连续任务组成。
-
模型使用与训练策略 遵循先前的工作,作者在四个 LIBERO 套件上训练单一策略。CALVIN 的性能通过每个链中成功完成的任务平均数量来衡量。
-
处理与评估指标 使用来自 openpi 的数据转换脚本来标准化格式。研究中包含的乒乓球任务定义了基于反应延迟和击球力量的具体评分标准,范围从未击中得 0 分到强力回击得 1 分。
方法
作者提出了 FASTER,这是一个旨在增强视觉 - 语言 - 动作(VLA)模型动作分块策略反应能力的框架。其解决的核心挑战是生成动作块时固有的延迟,这种延迟会推迟机器人对动态事件的响应。
推理管道与反应分析 该系统运行在客户端 - 服务器架构上,其中策略服务器处理模型推理,机器人客户端管理电机控制。作者分析了两种交互范式:同步和异步推理。在同步设置中,机器人在等待生成下一个动作块时会暂停执行,如果推理延迟超过控制周期,会导致轨迹不平滑。相反,异步推理在当前动作块完全执行之前启动下一个推理周期,从而实现无缝执行。
参考展示同步和异步推理时间管道的框架图。
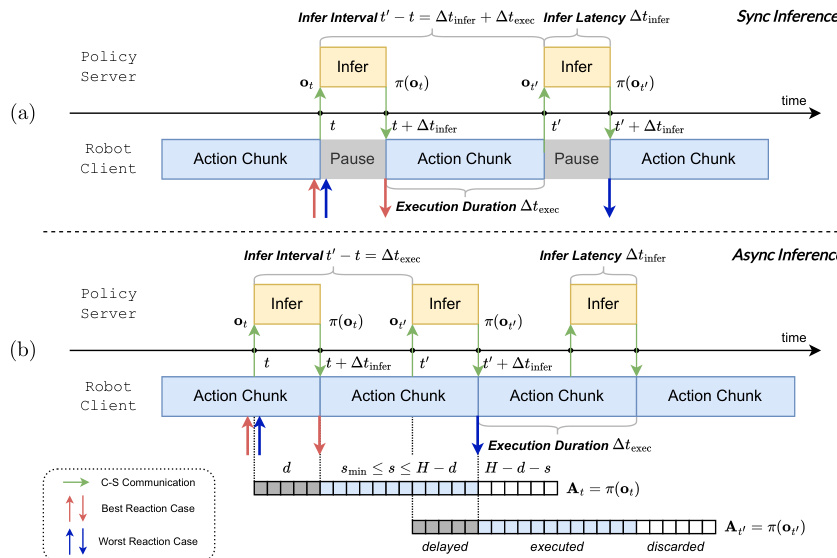
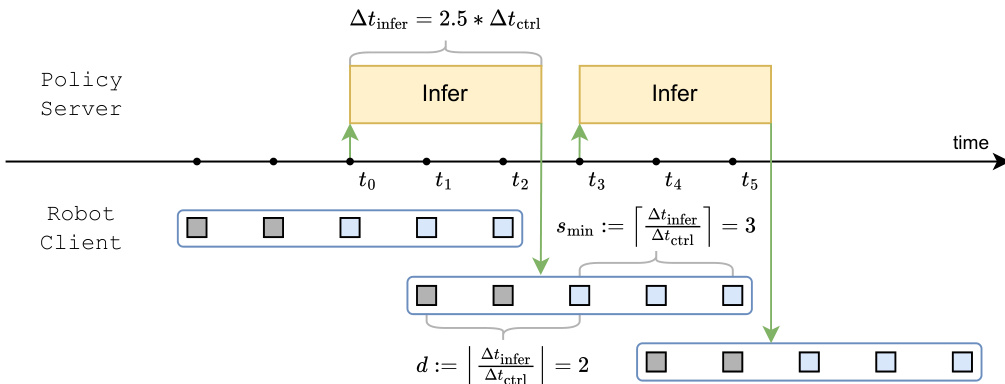
然而,异步执行引入了感知 - 执行差距,即用于推理的观测值在新动作准备好时可能已经过时。为了量化响应能力,作者引入了首次动作时间(TTFA),定义为机器人可以开始运动的最早时刻。他们指出,减少执行地平线 s 会增加推理频率,但受限于推理延迟 Δtinfer。最小可行执行地平线由 smin:=⌈Δtinfer/Δtctrl⌉ 决定。
参考详细说明异步推理管道和离散化推理延迟的时间线图。
模型架构与训练 底层策略利用基于流的 VLA 结构,包含一个 VLM 骨干网络和一个动作专家(AE)模块。该模型学习一个速度场,利用条件流匹配将噪声样本传输到目标动作块。训练目标是最小化预测速度场与高斯噪声和目标动作之间线性插值路径上的真实速度之间的差异:
L(θ)=Eτ∼U(0,1)vθ(ot,Atτ,τ)−(ϵ−A^t)2.在推理过程中,动作是通过将学习到的速度场从 τ=1 积分到 τ=0 生成的。
地平线感知调度(HAS) 为了最小化 TTFA,作者提出了一种地平线感知调度(HAS),优先采样近期动作。与在整个动作块上应用恒定时间调度的传统方法不同,HAS 为未来动作分配更多的去噪步骤,同时加速即时动作的生成。
参考比较恒定调度和地平线感知调度的可视化图。
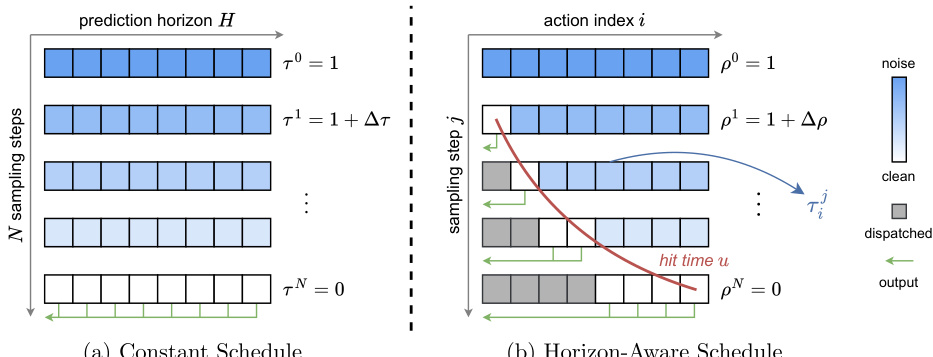
在该方案中,流匹配时间步被设计为依赖于索引。每个动作 i 都有一个由其索引决定的特定击中时间 ui,确保第一个动作在单次采样步后完全去噪。这使得系统能够立即分发第一个动作,显著降低延迟。
流式接口与早期停止 该框架实现了流式客户端 - 服务器接口,以利用动作的渐进式生成。在服务器端,最终确定的动作会立即分发,而模型继续生成剩余动作。在客户端,控制器将接收到的动作追加到缓冲区,而无需等待整个动作块。
参考动作采样速度的比较图。
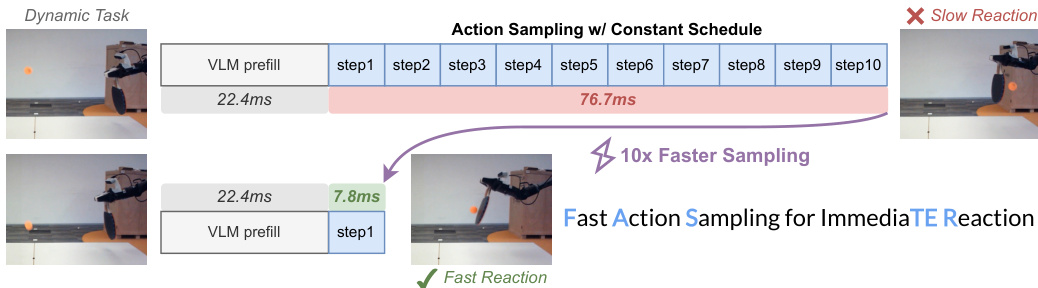
此外,作者引入了一种早期停止策略。一旦执行地平线 s 内的所有动作都已确定,就会跳过剩余的采样步骤。这减少了所需动作的整体推理延迟,允许更小的可行 smin 和更紧的反应时间界限。为了确保微调期间的鲁棒性,采用了一种混合调度策略,模型在地平线感知调度和原始恒定调度下同时学习。
实验
- 关于动作块采样的初步研究证实,序列中的早期动作比未来动作表现出更低的直线度和更快的收敛速度,这表明由于更强的因果约束,短期预测更容易且更确定。
- 反应速度实验表明,与同步和异步基线相比,所提出的地平线感知调度显著降低了推理延迟并提高了概率反应时间,在资源受限的硬件上观察到了确定性的优越性。
- 真实世界的机器人任务(包括乒乓球和操作)表明,更快的反应能力能够实现更早的运动启动和更好的接触质量,证明在响应速度与准确性之间取得平衡能带来更优的任务完成分数和效率。
- 在 LIBERO、CALVIN 和 Kinetix 上的仿真基准测试证实,自适应采样策略仅造成轻微的性能下降,同时保持了竞争力;消融研究验证了混合训练调度的鲁棒性以及调度参数中的权衡。
- 流式客户端 - 服务器接口分析显示,渐进式动作传输有效地掩盖了后续动作的网络延迟,确保了实时操作期间连续执行而不会出现管道停滞。