Command Palette
Search for a command to run...
TerraScope:面向对地观测的像素级视觉推理
TerraScope:面向对地观测的像素级视觉推理
Yan Shu Bin Ren Zhitong Xiong Xiao Xiang Zhu Begüm Demir Nicu Sebe Paolo Rota
摘要
视觉 - 语言模型(VLMs)在地球观测(EO)领域展现出巨大潜力,但在需要基于精确像素级视觉表征进行复杂空间推理的任务中仍面临挑战。为解决这一问题,我们提出了 TerraScope,这是一种统一的 VLM,具备像素级地理空间推理能力,其核心特性包括:(1)模态灵活的推理:能够处理单模态输入(光学或合成孔径雷达 SAR),并在双模态数据可用时自适应地将不同模态融合至推理过程中;(2)多时相推理:能够整合时序数据以进行多时间点的变化分析。此外,我们构建了 Terra-CoT,这是一个大规模数据集,包含 100 万条样本,其中将像素级掩码(mask)嵌入到来自多源数据的推理链中。我们还提出了 TerraScope-Bench,这是首个面向像素级地理空间推理的基准测试,包含六个子任务,同时评估答案准确率与掩码质量,以确保推理过程真正基于像素级视觉证据。实验结果表明,TerraScope 在像素级地理空间推理任务上显著优于现有的 VLMs,并能提供可解释的视觉证据。
一句话总结
特伦托大学、BIFOLD、柏林工业大学和慕尼黑工业大学的研究人员提出了 TerraScope,这是一个统一的视觉语言模型,通过将像素级定位掩码(grounding masks)整合到交错式思维链(CoT)中,提升了地球观测能力,实现了卓越的空间推理。该方法通过支持模态灵活和多时相分析,并依托新发布的 Terra-CoT 数据集和 TerraScope-Bench 基准测试,性能优于以往的视觉语言模型(VLMs)。
主要贡献
- 本文介绍了 TerraScope,这是一个统一的视觉语言模型,它将每个推理步骤建立在精确的分割掩码之上,以实现细粒度的空间分析,同时支持多时相变化推理以及光学与 SAR 模态的自适应融合。
- 构建了一个名为 Terra-CoT 的大规模数据集,包含 100 万条指令微调样本,其中像素级精确掩码直接嵌入到推理链中,以促进像素定位地理空间任务的可扩展训练。
- 提出了 TerraScope-Bench,这是首个针对像素定位地理空间推理的基准测试,包含 3,837 个专家验证样本,并采用双重评估指标,同时评估答案准确性和掩码质量,以确保真实的视觉定位效果。
引言
地球观测依赖于分析庞大的卫星档案以执行灾害响应和环境监测等关键任务,然而当前的视觉语言模型难以执行这些应用所需的精确像素级空间推理。现有方法往往因为依赖边界框等粗粒度视觉线索(无法捕捉地物覆盖的连续空间分布)或依赖增加复杂性并降低可控性的外部工具而失败。为了解决这些差距,作者提出了 TerraScope,这是一个统一的框架,它将像素级分割掩码与文本推理链交错结合,以实现细粒度的地理空间分析。该模型独特地支持光学和 SAR 模态的自适应融合以及多时相变化检测,同时团队还发布了 Terra-CoT(一个包含嵌入掩码的大规模数据集)和 TerraScope-Bench(首个旨在同时衡量答案准确性和掩码质量的评估套件)。
数据集
-
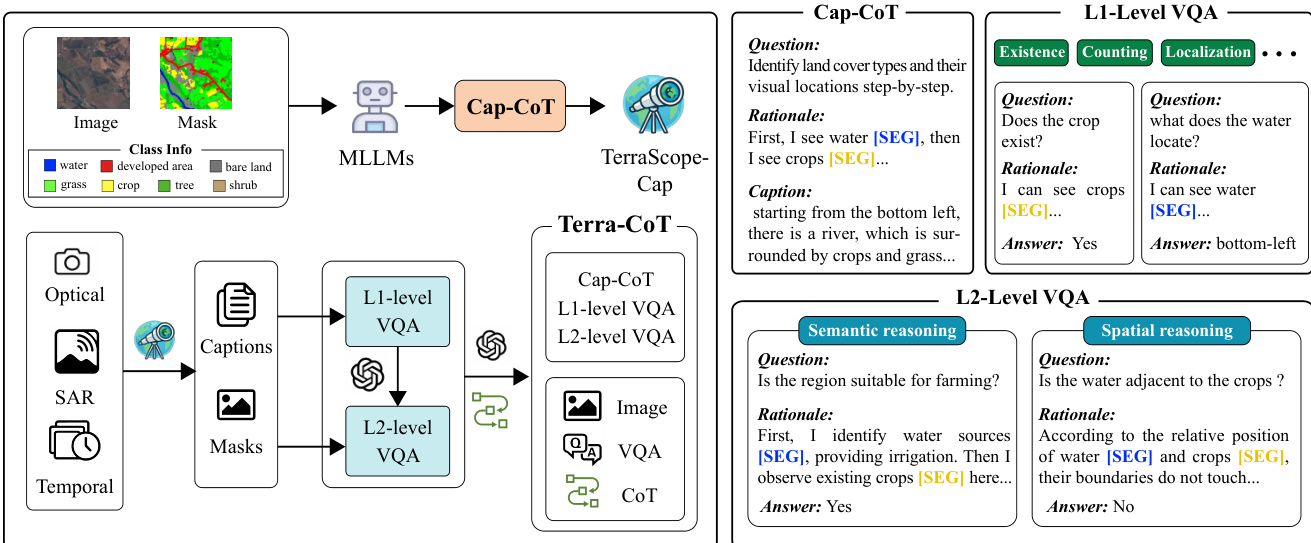
数据集构成与来源 作者通过两阶段自动化流程构建 Terra-CoT 数据集,以创建像素定位的视觉思维链(CoT)数据。该过程始于 Cap-CoT,这是一个包含 25 万样本的子集,源自 ChatEarthNet、BigEarthNet、xBD 和 TEOChat 等现有数据集的语义标注。该初始子集用于训练一个名为 TerraScope-Cap 的中间标注器,随后利用该标注器从涵盖全球区域的光学、SAR 及时相影像等多样化来源合成完整的 Terra-CoT 数据集。
-
各子集的关键细节
- Cap-CoT:包含 25 万样本,通过提示大型多模态模型处理叠加掩码的图像和分割标签,生成带有显式推理痕迹的详细描述。
- L1 级 VQA:包含基本的空间定位任务,如物体存在性、计数、定位、面积量化和边界检测,这些任务使用基于模板的问题和确定性掩码分析合成。
- L2 级 VQA:包含 100 万样本,涉及复杂的多步推理,分为 L2-空间(跨实体分析,如邻接或距离)和 L2-语义(领域知识任务,如土地适宜性),由大型语言模型(LLM)结合视觉证据与空间或语义逻辑生成。
-
模型使用与训练策略 作者利用 25 万 Cap-CoT 样本来训练 TerraScope 模型并构建 TerraScope-Cap 标注器。完整的 Terra-CoT 数据集(包含 100 万个合成样本)作为指令微调的主要训练混合数据。数据处理确保了简单空间查询与复杂推理任务之间的平衡,其中 L2 子集专门设计用于增强多步空间分析能力。
-
处理、裁剪与元数据构建
- 定位描述生成(Grounded Captioning):流程将带有彩色掩码叠加和分割标签的卫星图像输入模型,强制在描述生成过程中显式引用掩码区域。
- 分层合成:L1 问题通过模板生成,答案根据分割掩码确定性计算;L2 问题则由 LLM 合成,将多个 L1 任务组合成复杂场景。
- 优化:对于 VQA-CoT,作者通过计算 TerraScope-Cap 预测掩码与可用标注之间的交集来优化真实掩码,以确保更高质量。
- 元数据:输入数据包括卫星图像、分割标签以及分辨率、传感器类型和位置等元数据,以支持多样化的推理上下文。
方法
作者提出了 TerraScope,这是一个专为像素定位视觉推理设计的框架。与仅依赖文本推理的传统视觉语言模型(VLMs)不同,TerraScope 将分割掩码和掩码视觉特征直接交错嵌入到推理链中。形式上,传统 VLM 仅通过语言推理输出答案,而 TerraScope 生成的序列包含推理步骤、分割掩码和掩码视觉特征。
[r1,(m1,v1),r2,(m2,v2),…,rk,(mk,vk),a]=f(v,q)如框架图所示,该系统将语言分词器、视觉编码器和定位编码器集成到统一流程中。大型语言模型(LLM)与掩码解码器协同工作。当 LLM 生成特殊的 [SEG] 标记时,会触发掩码解码器基于该标记的隐藏状态生成分割掩码。这种设计允许 LLM 通过学习的提示嵌入来控制掩码生成,从而有效地将推理过程定位到特定的视觉区域。
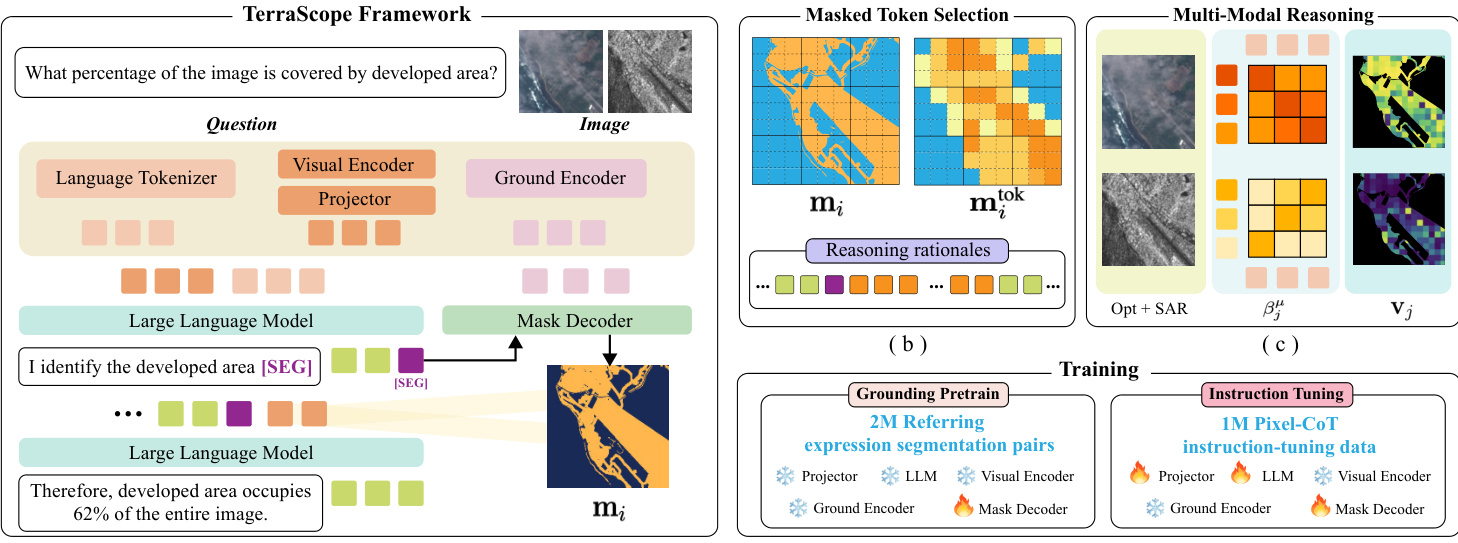
该机制使模型能够将推理定位到特定的视觉区域。例如,当被要求比较大小或测量距离时,模型会识别相关区域,生成掩码,并从这些特定区域提取视觉特征以指导后续的文本生成。以下示例展示了模型如何显式分割水体、农作物或建筑物以得出准确答案。

该框架能够处理复杂的地球观测(EO)数据场景。对于光学和 SAR 配对等多源输入,模型采用文本引导的令牌级模态选择。它计算相关性分数,以动态选择对每个视觉令牌最具信息量的模态。对于时相序列,显式指示符指定了要对哪一帧图像进行分割和特征提取。
训练分为两个阶段。首先,模型在指代表达分割对上接受定位预训练,以建立基础能力。其次,在包含交错视觉和文本痕迹的指令微调数据的 Terra-CoT 数据集上进行微调。数据构建流程涉及生成描述和掩码,以创建不同复杂度级别的多样化推理问题。
为了确保效率,系统限制了注入推理序列的视觉令牌数量。如果选定的令牌超过阈值,则应用空间均匀采样以保持代表性覆盖。与标准 VLM 相比,该方法的有效性显而易见。其他模型可能依赖基于颜色的启发式方法或粗略估计,而 TerraScope 则执行精确的像素计数和区域识别以得出正确结论。

实验
- 在 TerraScope-Bench、LandSat30-AU 和 DisasterM3 上的主要基准评估证实,像素定位推理显著优于现有的通用和地球观测专用 VLM,特别是在需要细粒度空间分析的任务(如面积估算和物体计数)上。
- 关于 CoT 策略的消融研究证实,通过分割掩码进行精确的像素级定位对于准确推理至关重要,因为随机令牌选择或粗略边界框无法捕捉复杂的空间边界。
- 多模态推理实验表明,在光学和 SAR 模态之间进行自适应选择,在云层覆盖等挑战性条件下提高了性能,同时通过减少上下文长度(与特征拼接相比)保持了效率。
- 对 Terra-CoT 数据集构成的分析显示,将 VQA 和描述生成数据与显式推理步骤相结合,对于在多样化的地理空间任务中实现强大的泛化能力是必要的。
- 定性结果和失败案例分析表明,虽然该模型实现了可解释的推理痕迹,但其性能仍依赖于分割质量,并且目前受限于仅使用 RGB 输入,这限制了光谱区分能力。