Command Palette
Search for a command to run...
3DreamBooth:高保真度以主体为中心的 3D 视频生成模型
3DreamBooth:高保真度以主体为中心的 3D 视频生成模型
Hyun-kyu Ko Jihyeon Park Younghyun Kim Dongheok Park Eunbyung Park
摘要
为定制化主体生成动态且视角一致的视频,在沉浸式 VR/AR、虚拟制作及下一代电子商务等新兴应用中具有广泛需求。然而,尽管基于主体的视频生成技术已取得显著进展,现有方法仍主要将主体视为二维实体,侧重于通过单视角视觉特征或文本提示来传递身份特征。由于现实世界中的主体本质上具有三维属性,将此类以二维为中心的方法应用于三维对象定制时,暴露出一个根本性局限:它们缺乏重建三维几何结构所必需的综合空间先验。因此,在合成新视角时,这些方法不得不依赖生成看似合理但实则任意的细节来填充未见区域,而非保留真实的三维身份。受限于多视角视频数据集的匮乏,实现真正的三维感知定制仍极具挑战。虽然尝试在有限的视频序列上对模型进行微调,但往往会导致时间维度的过拟合。为解决上述问题,我们提出了一个新颖的三维感知视频定制框架,包含 3DreamBooth 和 3Dapter 两个核心组件。3DreamBooth 通过单帧优化范式,将空间几何与时间运动解耦。该方法通过限制仅对空间表示进行更新,无需繁琐的视频级训练,即可在模型中嵌入稳健的三维先验。为了增强细粒度纹理并加速收敛,我们引入了 3Dapter,这是一个视觉条件模块。在单视角预训练之后,3Dapter 通过非对称条件策略与主生成分支进行多视角联合优化。该设计使该模块能够充当动态选择路由器,从极小的参考集中查询特定视角的几何线索。项目主页:https://ko-lani.github.io/3DreamBooth/
一句话总结
延世大学和高丽大学的研究人员提出了 3DreamBooth 和 3Dapter,这是一个通过单帧优化将空间几何与时间运动解耦的框架,旨在为沉浸式 VR 和虚拟制作生成高保真、视角一致的定制化 3D 主体视频。
主要贡献
- 本文介绍了 3DreamBooth,这是一种单帧优化策略,通过将特定主体的 3D 身份整合到视频扩散模型中,并限制对空间表示的更新,从而避免了多视角视频数据集的需求,同时防止了时间过拟合。
- 提出了一个名为 3Dapter 的多视角条件模块,通过采用非对称条件策略从最小参考集中查询特定视角的几何提示,利用两阶段流程来增强细粒度纹理并加速收敛。
- 该工作建立了 3D-CustomBench,这是一个用于 3D 一致性视频定制的精选评估套件,实验表明,该组合框架在生成高保真、身份保持的视频方面优于现有的单参考基线。
引言
对沉浸式 VR/AR 体验和虚拟制作的需求,要求生成系统能够将定制主体置于动态环境中,同时在不同的视角下保持严格的视觉一致性。当前的主体驱动视频生成方法大多将物体视为 2D 实体,依赖单视角参考或文本提示,无法捕捉底层的 3D 几何结构。这一局限性迫使模型为未见过的角度虚构任意细节,而非保留真实的空间身份,而尝试在有限的多视角视频数据上训练往往会导致时间过拟合。为了解决这些问题,作者引入了 3DreamBooth,这是一个通过单帧优化范式将空间几何与时间运动解耦的框架,旨在无需 exhaustive 视频训练即可烘焙鲁棒的 3D 先验。他们进一步通过 3Dapter 增强了这一方法,这是一个多视角条件模块,利用非对称策略注入细粒度几何提示,从而在提高计算效率的同时实现高保真和视角一致的视频生成。
数据集
-
数据集构成与来源:作者使用了两个主要数据集:用于单视角预训练的 Subjects200K 数据集和用于评估的新引入的 3D-CustomBench。3D-CustomBench 结合了 MVIgNet 数据集中的物体和自定义捕获的 3D 物体,以确保完整的 360° 轨道覆盖。
-
每个子集的关键细节:
- Subjects200K:包含由 GPT-4o 生成的超过 30,000 个不同的主体描述,这些描述用于通过 FLUX.1 模型合成配对图像。这些配对共享相同的主体身份,但具有不同的姿势、光照和背景,以防止过拟合。
- 3D-CustomBench:由 30 个具有复杂 3D 结构、非平凡拓扑和高纹理分辨率的物体组成。每个物体包含约 30 张图像的全多视角序列。
-
数据使用与训练策略:
- 预训练:模型利用 Subjects200K 在关键图像处理模块上使用低秩自适应(LoRA)训练 3Dapter。训练运行 100,000 次迭代,全局批量大小为 4,学习率为 1×10−4,使用 AdamW 优化器。
- 评估:对于 3D-CustomBench,每个物体的完整多视角序列用于 3DreamBooth 优化。作者采样 Nc=4 个条件视角用于 3Dapter,以最大化角度覆盖同时最小化视觉重叠。
-
处理与元数据构建:
- 自动化策展:GPT-4o 生成主体描述,并在构建 Subjects200K 期间充当自动评估器以丢弃未对齐的样本。
- 提示生成:GPT-4o 自动为 3D-CustomBench 中的每个物体创建一个具有挑战性的验证提示,包含多样的背景和复杂动态(如人机交互)。
- 视角选择:条件视角经过策略性选择,以确保最佳的角度分布,而非随机采样。
方法
作者介绍了 3DreamBooth,这是一个用于视频扩散模型 3D 定制的框架。其核心策略是通过单帧训练范式将空间身份与时间动态解耦。

参考框架图以了解整体架构。该流程接受一组多视角图像,其中一张图像作为目标,子集作为参考条件。带有唯一标识符 V 的全局提示指导生成。文本和带噪声的目标潜在变量通过主分支使用 3DB LoRA 处理,而参考潜在变量通过共享的 3Dapter 传递。这些特征被连接起来进行多视角联合注意力。通过将输入限制为单帧(T=1),模型绕过了时间注意力,将更新集中在空间表示上,从而在不发生时间过拟合的情况下学习 3D 先验。
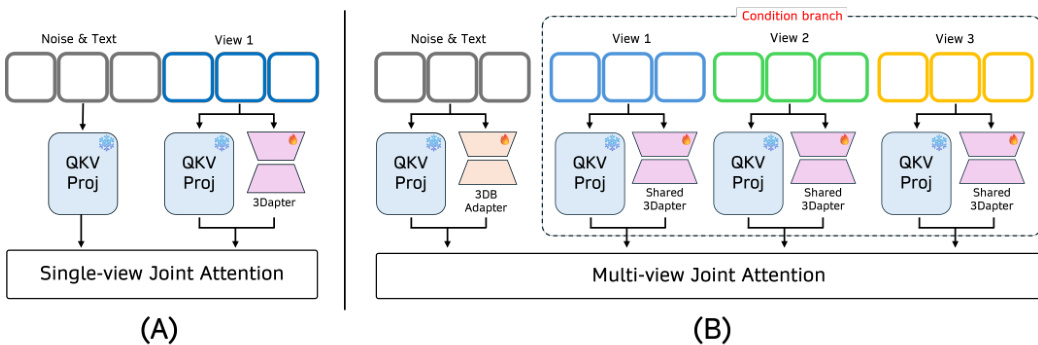
如下图所示,3Dapter 模块利用两阶段条件机制。第一阶段涉及在参考 - 目标对上进行的单视角预训练。第二阶段执行多视角联合优化,其中共享的 3Dapter 并行处理多个条件视角。多视角联合注意力充当动态选择路由器,查询相关的特定视角几何提示以重建目标视角。这种共享架构确保了跨视角一致的几何特征提取,而无需线性增加参数量。
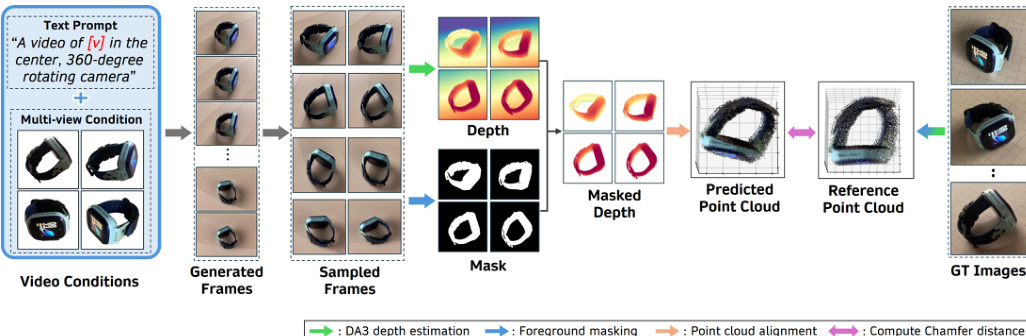
如下图所示,训练过程包含 3D 一致性检查以确保几何保真度。生成的帧经过深度估计和前景掩码处理,以生成预测的点云。该点云与参考点云对齐以计算 Chamfer 距离,该距离在优化过程中作为约束。这种方法使模型能够专注于学习几何变换,同时保留高频细节,有效地克服了文本驱动定制的信息瓶颈。
实验
- 与 VACE 和 Phantom 的对比实验验证了所提出的框架实现了更优越的多视角主体保真度,在 360 度旋转过程中保持了身份、形状、颜色和细粒度细节,而基线方法无法重建未见过的视角。
- 3D 几何保真度评估表明,与单视角方法相比,该方法显著降低了重建误差并提高了表面覆盖率,证实了其从多视角条件中恢复完整 3D 结构的能力。
- 消融研究表明,3Dapter 和 3DreamBooth 的协同组合至关重要,因为单独的 3Dapter 缺乏 3D 一致性,而单独的 3DreamBooth 在纹理细节和收敛速度方面存在困难,而它们的联合优化确保了结构准确性和高频细节保留。
- 额外的测试证实了该框架在不同物体类别和动态场景中的鲁棒性,以及其扩展到其他扩散 Transformer 架构的能力,而无需显式的空间条件模块。
- 对训练动态的分析表明,预训练 3Dapter 模块对于防止优化崩溃和实现快速收敛至关重要,而完整框架比文本驱动的基线在更少的迭代次数内实现了高保真结果。