Command Palette
Search for a command to run...
Astrolabe:为蒸馏自回归视频模型引导前向过程强化学习
Astrolabe:为蒸馏自回归视频模型引导前向过程强化学习
Songchun Zhang Zeyue Xue Siming Fu Jie Huang Xianghao Kong Y Ma Haoyang Huang Nan Duan Anyi Rao
摘要
蒸馏自回归(AR)视频模型能够实现高效的流式生成,但往往与人类视觉偏好存在偏差。现有的强化学习(RL)框架并不天然适配此类架构,通常要么需要代价高昂的再蒸馏,要么依赖求解器耦合的逆向过程优化,从而引入巨大的内存与计算开销。为此,我们提出了 Astrolabe,一种专为蒸馏 AR 模型设计的在线 RL 框架。为突破现有瓶颈,我们提出了一种基于负向感知微调(negative-aware fine-tuning)的正向过程 RL 表述。该方法通过在推理终点直接对比正负样本,在无需逆向过程展开(reverse-process unrolling)的情况下,确立了隐式的策略改进方向。为实现长视频的对齐扩展,我们提出了一种流式训练方案:通过滚动 KV-cache 逐步生成序列,将 RL 更新严格限定于局部片段窗口,同时利用先验上下文作为条件以确保长程连贯性。此外,为缓解奖励黑客(reward hacking)问题,我们集成了多奖励目标函数,并通过不确定性感知的选择性正则化与动态参考更新加以稳定。大量实验表明,我们的方法在多种蒸馏 AR 视频模型上均能持续提升生成质量,提供了一种稳健且可扩展的对齐解决方案。
一句话总结
来自香港科技大学、京东探索研究院和香港大学的 researchers 提出了 Astrolabe,这是一个在线强化学习框架,通过前向过程公式和流式训练方案,将蒸馏的自回归视频模型与人类偏好对齐。该方法消除了昂贵的重新蒸馏过程,同时增强了长视频的一致性并缓解了奖励黑客攻击。
主要贡献
- 本文介绍了 Astrolabe,这是一个在线强化学习框架,通过在推理端点对比正负样本,在不进行反向过程展开的情况下建立策略改进,从而将蒸馏的自回归视频模型与人类偏好对齐。
- 提出了一种流式训练方案,通过滚动 KV 缓存逐步生成序列,并仅对局部剪辑窗口应用强化学习更新(同时以先前的上下文为条件),从而实现长视频的可扩展对齐。
- 该工作整合了由不确定性感知选择性正则化和动态参考更新稳定的多奖励目标,以缓解奖励黑客攻击;大量实验表明,该方法在多种蒸馏自回归视频模型上均能带来一致的质量提升。
引言
蒸馏的自回归视频模型通过逐帧生成实现了高效的实时流式生成,但它们往往存在伪影且与人类视觉偏好不一致。此前尝试利用强化学习对齐这些模型的努力面临重大障碍,因为现有方法要么依赖缺乏主动探索的奖励加权蒸馏,要么需要昂贵的反向过程优化,这不仅将训练与特定求解器耦合,还带来了高昂的内存开销。作者利用 Astrolabe——一种高效的在线强化学习框架,引入了基于负感知微调的前向过程公式,在不重新蒸馏或轨迹展开的情况下实现模型对齐。该方法还通过流式训练方案扩展到长视频,该方案在保持上下文的同时对局部片段应用更新,并辅以多奖励目标和不确定性感知正则化等稳定技术以防止奖励黑客攻击。
方法
作者提出了 Astrolabe,这是一个内存高效的框架,旨在通过在线强化学习将蒸馏的自回归视频模型与人类偏好对齐。该方法结合了使用滚动 KV 缓存进行高效组采样的组式流式展开,以及用于求解器无关优化的剪辑级前向过程强化学习。为了扩展到长视频,该框架利用带有分离历史梯度的流式长时微调(Streaming Long Tuning)。此外,采用多奖励公式配合基于不确定性的选择性正则化,以有效缓解训练过程中的奖励黑客攻击。请参阅框架图以直观了解完整流程。
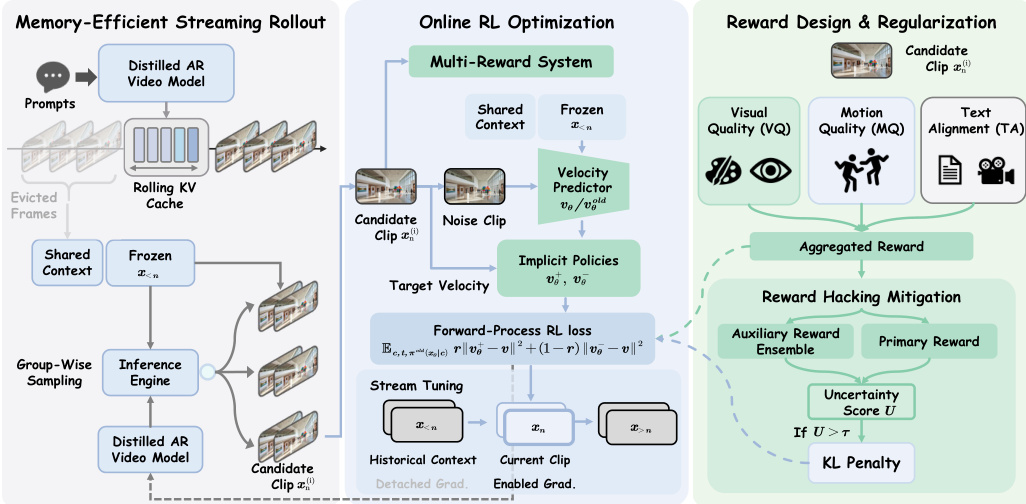
内存高效的流式展开 标准的强化学习范式依赖于具有全局奖励的序列级展开,这引入了时间信用分配问题和 prohibitive 的内存开销。为了克服这些限制,作者提出了一种组式流式展开策略。他们维护一个滚动 KV 缓存,通过构建受限的视觉上下文窗口来限制内存使用,该窗口由永久保留帧的帧汇(frame sink)和最近帧的滚动窗口组成。模型不是从头开始生成独立的长轨迹,而是自回归地采样视觉历史恰好一次,并将其 KV 缓存冻结为共享前缀。在每一步,模型利用此共享上下文并行解码多个独立的候选剪辑,这将生成开销限制在局部块内,并大幅减少展开时间。
在线强化学习优化 对于每个候选 xn(i),系统评估复合奖励 R(xn(i),c) 并通过组内均值中心化计算其优势 A(i):
A(i)=R(xn(i),c)−G1j=1∑GR(xn(j),c)随后将该优势归一化为 r~i=clip(A(i)/Amax)/2+0.5。利用当前(vθ)和旧(vθold)速度预测器,通过插值定义隐式正负策略:
v+=(1−β)vθold+βvθ,v−=(1+β)vθold−βvθ模型通过隐式策略损失 Lpolicy 直接优化,通过代入噪声样本推导 vtarget。为了进一步缓解奖励黑客攻击,该目标辅以不确定性感知的选择性 KL 惩罚。此外,该框架通过流式长时微调解决了“训练短/测试长”的不匹配问题。该范式严格模拟长序列推理的动态,同时将前向展开与梯度计算解耦。具体而言,当到达活动训练窗口时,所有先前帧的 KV 缓存会从计算图中显式分离,使得梯度仅通过活动窗口进行反向传播。
奖励设计与正则化 为了解决标量奖励函数掩盖特定质量维度的问题,作者构建了一个整合三个不同维度的复合奖励:视觉质量、运动质量和文本 - 视频对齐。视觉质量计算为前 30% 帧的平均 HPSv3 分数,以防止瞬态运动模糊对评估造成不成比例的惩罚。运动质量使用预训练的 VideoAlign 仅在灰度输入上评估时间一致性,以专注于运动动态。文本对齐采用标准的 RGB VideoAlign 来衡量语义对应关系。为了防止均匀的 KL 正则化不加区分地抑制高质量生成,引入了不确定性感知的选择性 KL 惩罚。对于每个候选,样本不确定性被量化为主要奖励模型与辅助模型之间的排名差异。高正值表明可能存在奖励黑客攻击,这些高风险样本会被掩码以严格应用 KL 惩罚,从而为干净数据保留优化灵活性。
实验
- 短视频单提示生成:验证了 Astrolabe 框架在各种基础架构上持续增强蒸馏自回归模型的能力,在保持推理速度的同时,产生了更清晰的纹理和更优越的运动一致性。
- 长视频单提示生成:表明在短视频上执行的对齐优化能有效外推到更长的时间范围,即使对于原本在短序列上训练的模型,也能提升长时域质量和时间一致性。
- 长视频多提示生成:证实了该框架在交互式设置中提升人类偏好对齐的能力,在复杂的叙事转换过程中实现了更好的视觉美学和稳定的长程运动一致性。
- 消融研究:确立了带有分离上下文的剪辑级组式采样优化了内存与质量的权衡,多奖励公式防止了单目标过拟合,而选择性 KL 正则化确保了在不限制学习自由度的情况下实现稳定收敛。