Command Palette
Search for a command to run...
HopChain:面向可泛化视觉 - 语言推理的多跳数据合成
HopChain:面向可泛化视觉 - 语言推理的多跳数据合成
摘要
视觉 - 语言模型(VLMs)展现出强大的多模态能力,但在细粒度的视觉 - 语言推理方面仍存在不足。我们发现,长思维链(CoT)推理会暴露多种失败模式,包括感知、推理、知识及幻觉错误,且这些错误可能在中间步骤中累积。然而,当前大多数用于可验证奖励强化学习(RLVR)的视觉 - 语言数据并未包含依赖全程视觉证据的复杂推理链,导致上述缺陷难以被充分揭示。为此,我们提出了 HopChain,这是一个可扩展的框架,旨在为 VLMs 的 RLVR 训练合成多跳视觉 - 语言推理数据。每个合成的多跳查询均构成一条逻辑依赖的、基于实例的推理链:前期步骤确立后续步骤所需的实例、集合或条件,而最终答案则为一个具体且无歧义的数字,适用于可验证奖励机制。我们在两种 RLVR 设置下对 Qwen3.5-35B-A3B 和 Qwen3.5-397B-A17B 模型进行了训练:仅使用原始数据,以及原始数据结合 HopChain 合成的多跳数据。随后,我们在涵盖 STEM 与谜题、通用视觉问答(VQA)、文本识别与文档理解、以及视频理解的 24 个基准测试上对两者进行了对比评估。尽管该多跳数据并非针对任何特定基准合成,但在两个模型上,24 个基准中有 20 个均取得了提升,表明其具有广泛且可泛化的增益效果。一致地,将完整链式查询替换为半多跳或单跳变体后,在五个代表性基准上的平均得分分别从 70.4 降至 66.7 和 64.3。值得注意的是,多跳增益在长 CoT 视觉 - 语言推理中达到峰值,在超长 CoT 模式下提升幅度超过 50 分。这些实验表明,HopChain 是一个有效且可扩展的框架,能够通过合成多跳数据显著提升视觉 - 语言推理的泛化能力。
一句话总结
Qwen 团队与清华大学联合推出了 HopChain,这是一个可扩展的框架,旨在合成多跳视觉 - 语言推理数据,以解决视觉语言模型(VLMs)中的细粒度错误。通过生成具有逻辑依赖性、基于实例的链条,并附带可验证的数值答案,HopChain 显著提升了模型在多样化基准测试中的泛化性能,尤其在长思维链(CoT)推理场景中表现卓越。
主要贡献
- 本文介绍了 HopChain,这是一个可扩展的框架,通过构建逻辑依赖链条来合成多跳视觉 - 语言推理数据。在该链条中,前序步骤确立后续步骤所需的实例或条件,从而确保持续的视觉重定位(re-grounding)。
- 该研究表明,利用 HopChain 合成的数据训练 VLMs,可在 24 个多样化基准测试中的 20 个上提升性能,涵盖 STEM、通用 VQA 和视频理解等领域。这表明该方法具有广泛的泛化增益,无需针对特定基准进行定制。
- 实验显示,多跳推理的增益在长 CoT 设置下达到峰值,提升幅度超过 50 分;而消融实验证实,降低链条复杂度会显著拉低平均得分,验证了完整的多跳结构对于稳健推理的必要性。
引言
视觉语言模型(VLMs)在多模态任务中表现出色,但在长思维链推理过程中,常因幻觉和视觉定位能力弱等累积性错误而失败。现有的用于可验证奖励强化学习(RLVR)的训练数据很少要求复杂的、多步骤的视觉证据,导致这些关键弱点在模型优化过程中未被解决。作者提出了 HopChain,这是一个可扩展的框架,用于合成多跳推理数据,其中每一步都逻辑依赖于之前的视觉发现,从而强制模型进行持续的重定位。该方法生成的查询具有可验证的数值答案,能够暴露多种失败模式,从而在不针对特定下游任务的情况下,在 24 个基准测试中的 20 个上实现了广泛的性能提升。
数据集
-
数据集构成与来源:作者合成了一套多跳视觉 - 语言推理数据集,旨在迫使模型在长 CoT 推理的每一步都寻求视觉证据。数据源自包含足够可检测实例的原始图像集合,并通过四阶段流水线处理,生成将多个推理步骤串联成单一任务的查询。
-
各子集的关键细节:
- 推理层级:查询被构建为三级任务,结合了 Level 1(单对象感知,如文本阅读或属性识别)和 Level 2(多对象感知,如空间或计数关系)。
- 跳跃类型:每个查询必须包含感知级跳跃(在单对象和多对象任务间切换)和实例链跳跃(基于前一个对象移动到下一个对象)。
- 答案格式:所有查询均以特定、无歧义的数值答案结束,以确保与 RLVR 验证的兼容性。
- 依赖规则:子步骤必须形成逻辑依赖链条,前序跳跃确立后续跳跃所需的实例或条件,防止浅层捷径。
-
数据使用与处理:
- 阶段 1(类别识别):VLM 识别输入图像中存在的语义类别,无需定位。
- 阶段 2(实例分割):SAM3 生成分割掩码和边界框,将类别解析为具体的、空间定位的实例。
- 阶段 3(查询生成):系统组合 3–6 个实例,并利用 VLM 生成多跳查询。模型接收原始图像以及每个实例的裁剪补丁以辅助设计,尽管这些补丁在实际推理任务中不可用。
- 阶段 4(标注与校准):四名人类标注员独立解决每个查询;仅保留四名标注员对数值答案达成一致查询。随后进行难度校准,剔除较弱模型能达到 100% 准确率的查询,确保最终数据集包含经过验证的挑战性样本。
-
裁剪与元数据策略:
- 裁剪:在设计阶段,流水线利用边界框提取每个检测到的实例的裁剪补丁。这些补丁作为参考材料供 VLM 理解外观和位置,但在最终训练提示中被排除,以模拟真实世界条件。
- 元数据构建:提示中明确提供每个实例在 0–1000 范围内的坐标,并列出了任务必须考虑的具体对象实例。
- 质量控制:流水线在人工标注阶段过滤掉指代模糊的查询,并在基于模型的校准阶段剔除过于简单的查询,以确保高质量的训练信号。
方法
作者提出了一个综合框架,将可扩展的数据合成与先进的强化学习技术相结合,以增强视觉语言模型(VLMs)的多跳推理能力。该方法分为三个核心组成部分:结构化多跳训练数据的生成、强化学习目标的构建以及用于策略更新的优化算法。
可扩展的多跳数据合成
为了解决典型训练数据中缺乏复杂推理链条的问题,作者利用了一个可扩展的数据合成流水线,旨在强制实施具有重复视觉定位的依赖链接跳跃。请参阅框架图以概览 HopChain 多跳数据合成框架。
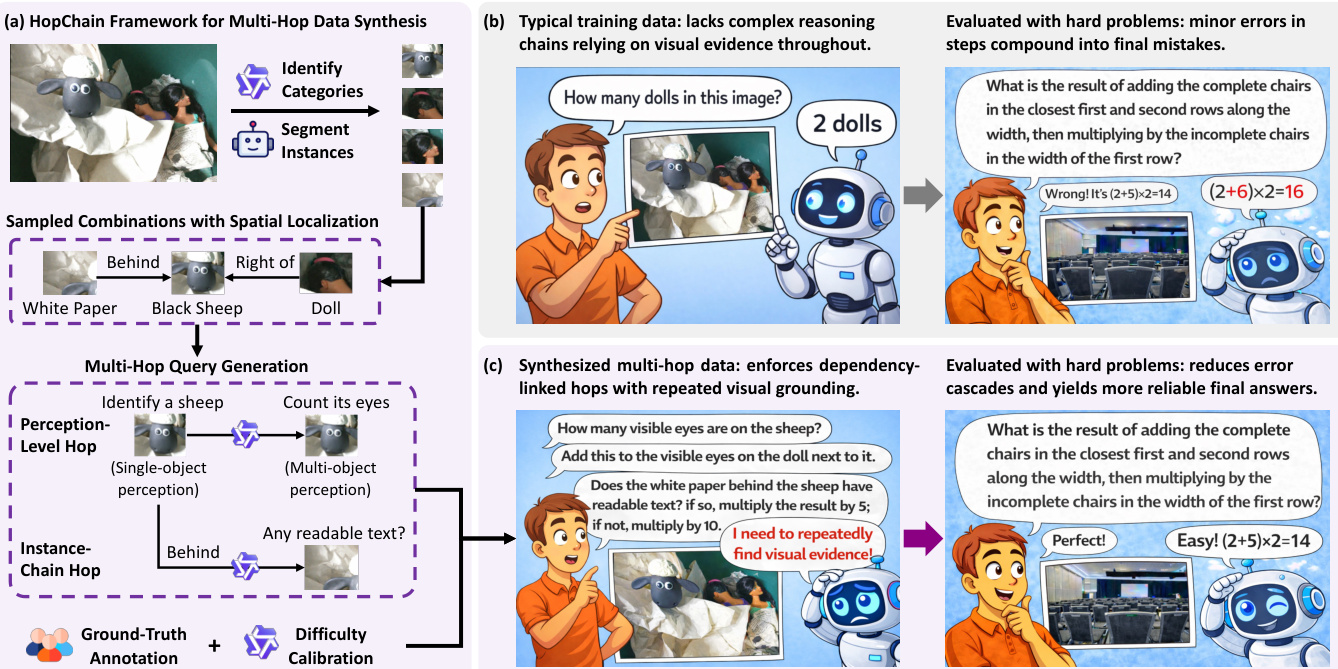 该流水线利用强大的基础模型,包括用于目标检测的 VLM 和用于实例分割的 SAM,从原始图像构建结构化查询。合成过程施加了严格的约束以确保高质量和泛化性。每个生成的查询必须涉及真正的多跳推理结构,其中当前跳跃所需的实例只能从前序跳跃中确立的实例中识别。此外,查询的设计旨在最大化实例覆盖率,确保选定组合中的每个对象在推理链中都发挥有意义的作用。作者还强制要求措辞无歧义且解法确定,禁止使用边界框颜色等低级视觉特征来定位信息。这种方法迫使模型恢复并保留中间视觉证据,而不是仅依赖语言启发式方法。该合成过程处理的视觉复杂性示例包括涉及车辆位置的空间推理任务和涉及轨迹分析的逻辑推理任务。
该流水线利用强大的基础模型,包括用于目标检测的 VLM 和用于实例分割的 SAM,从原始图像构建结构化查询。合成过程施加了严格的约束以确保高质量和泛化性。每个生成的查询必须涉及真正的多跳推理结构,其中当前跳跃所需的实例只能从前序跳跃中确立的实例中识别。此外,查询的设计旨在最大化实例覆盖率,确保选定组合中的每个对象在推理链中都发挥有意义的作用。作者还强制要求措辞无歧义且解法确定,禁止使用边界框颜色等低级视觉特征来定位信息。这种方法迫使模型恢复并保留中间视觉证据,而不是仅依赖语言启发式方法。该合成过程处理的视觉复杂性示例包括涉及车辆位置的空间推理任务和涉及轨迹分析的逻辑推理任务。
带可验证奖励的强化学习 训练过程采用带可验证奖励的强化学习(RLVR)用于 VLMs。该框架与大型语言模型的 RLVR 高度相似,但处理图像和文本查询作为输入,生成以可验证答案预测为终点的文本思维链。主要目标是最大化期望奖励,定义如下:
J(π)=E(I,q,a)∼D,o∼π(⋅∣I,q)[R(o,a)],whereR(o,a)={1.00.0if is_equivalent(o,a),otherwise.其中,I、q 和 a 分别表示从数据集 D 中采样的图像、文本查询和真实答案,o 表示由策略 π 在给定 I 和 q 条件下生成的响应。奖励函数根据生成输出是否与真实答案等价提供二元信号。
软自适应策略优化 为了缓解先前 RLVR 算法中硬截断(hard clipping)可能引起的不稳定性和低效性,作者引入了软自适应策略优化(SAPO)。该方法用温度控制的软门控替代硬截断。VLMs 的优化目标构建如下:
J(θ)=E(I,q,a)∼D,{oi}i=1G∼πold(⋅∣I,q)G1i=1∑G∣oi∣1t=1∑∣oi∣fi,t(ri,t(θ))A^i,t,其中概率比率 ri,t(θ) 定义为当前策略与旧 rollout 策略的比率。优势项 A^i,t 通过对一组样本的奖励 Ri 进行归一化计算得出。函数 fi,t(x) 充当由温度 τpos 和 τneg 分别控制的软门控,用于正负 token。与传统的截断方法相比,这种自适应机制允许更平滑的策略更新并提高训练稳定性。
实验
- 对长思维链推理中多种失败模式的分析表明,错误并非孤立存在,而是累积的;感知错误往往会触发下游的推理、知识和幻觉失败,跨越各种视觉场景。
- 主要基准评估表明,在标准 RLVR 训练基础上增加 HopChain 合成的多跳数据,可在 24 个基准测试中的 20 个上带来广泛且可泛化的改进,涵盖小模型和大模型规模,涉及 STEM、通用 VQA、文档理解和视频任务。
- 消融实验证实,在训练过程中保留完整的多跳结构至关重要,因为在缩短或单跳变体上训练的模型表现出显著较低的性能,这验证了维持长跨跳依赖的必要性。
- 进一步分析表明,所提出的方法有效增强了超长推理链的鲁棒性,覆盖了广泛的查询难度谱系,并纠正了多种错误类型,而不仅仅是解决狭窄的失败模式子集。