Command Palette
Search for a command to run...
SocialOmni:评估 Omni Models 在视听社交交互中的表现
SocialOmni:评估 Omni Models 在视听社交交互中的表现
摘要
全模态大语言模型(Omni-modal Large Language Models, OLMs)通过原生集成音频、视觉和文本,重新定义了人机交互方式。然而,现有的 OLM benchmark 仍局限于静态且以准确性为中心的任务,在评估“社交交互性”(social interactivity)方面存在关键空白——而社交交互性是指在自然对话中感知并应对动态线索的基础能力。为此,我们提出了 SocialOmni,这是一个全面的 benchmark,旨在从三个核心维度对这种对话交互性进行操作化评估:(i) 说话人分离与识别(即:谁在说话);(ii) 打断时机控制(即:何时插话);以及 (iii) 自然打断生成(即:如何措辞进行打断)。SocialOmni 包含 2,000 个感知样本,以及一个经过质量控制的、包含 209 个交互生成实例的诊断集,该集合具有严格的时间和上下文约束;此外,还辅以受控的音视频不一致场景,以测试模型的鲁棒性。我们对 12 个领先的 OLMs 进行了 benchmark 测试,结果揭示了不同模型在社交交互能力方面存在显著差异。
一句话总结
作者提出了 SocialOmni,这是一个针对全模态大语言模型的综合基准,旨在通过操作化说话人分离与识别、打断时机控制以及自然打断生成,评估超越静态任务的社会交互能力。该基准使用了 2,000 个感知样本和 209 个质量控制交互生成实例,并辅以受控的视听不一致场景,以评估 12 个领先的 OLMs,并揭示其社会交互能力的显著差异。
核心贡献
- 本文介绍了 SocialOmni,这是一个综合基准,通过操作化评估说话人分离、打断时机和自然打断生成来评估对话交互性。该基准评估自然对话中的动态线索,以评估社会交互能力。
- SocialOmni 包含 2,000 个感知样本,以及一个由 209 个交互生成实例组成的质量控制诊断集,具有严格的时间和上下文约束。数据集包含受控的视听不一致场景,以测试模型对多模态冲突的鲁棒性。
- 对 12 个领先的 OLMs 进行基准测试揭示了它们在不同模型间社会交互能力的显著差异。这些结果证明了该基准能够揭示回合进入决策和打断处理方面的性能差距。
引言
全模态大语言模型整合了音频、视觉和文本,以支持实时多模态对话,其成功取决于交互能力(如回合时机和社会连贯性),而不仅仅是事实准确性。现有基准侧重于静态准确性,无法评估多轮对话中的连贯理解。以往以行为为中心的工作通常孤立单一层面,而未同时评估感知和社会适当性。为了弥合这一差距,作者引入了 SocialOmni 来评估说话人识别、回合时机和打断生成方面的社会交互性。他们还提出了一种双轴协议,以将感知与生成分离,并设计探针来量化视听冲突下的鲁棒性。
数据集
-
数据集组成与来源
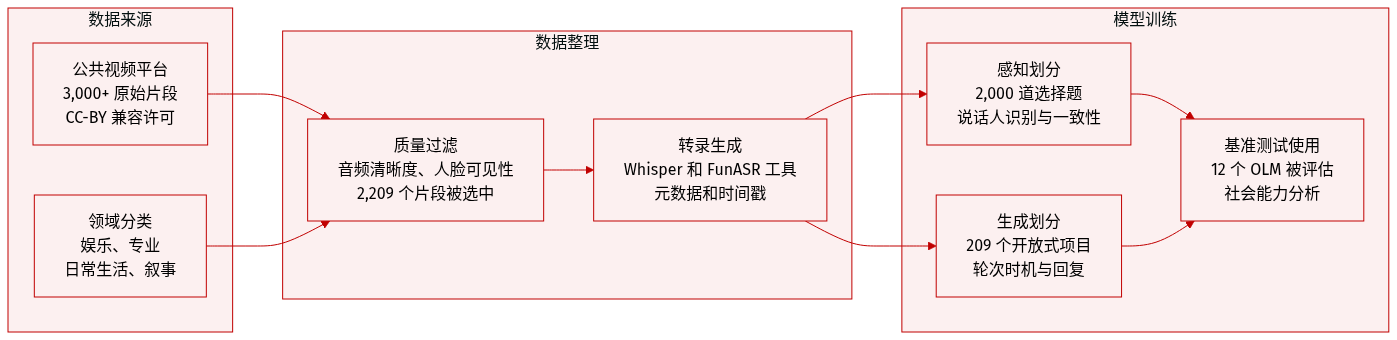
- 作者从公共平台汇编了超过 3,000 个原始视频,确保符合 CC-BY 兼容许可。
- 内容分为四个领域,包括娱乐、专业、日常生活和叙事,涵盖 15 个子类别。
-
每个子集的关键细节
- 对音频清晰度、面部可见性和回合结构的严格过滤将池减少到 2,209 个片段,平均时长为 25.0 秒。
- 感知划分包含 2,000 个多项选择题,分为 1,725 个一致和 275 个不一致的视听场景。
- 生成划分包含 209 个开放性问题,具有多参考响应,以支持对对话回合的稳健评估。
-
论文如何使用数据
- SocialOmni 作为一个基准来评估 12 个领先的全模态大语言模型,而不是用于模型训练。
- 任务 I 测试特定时间戳的说话人识别能力。
- 任务 II 基于视频和音频前缀测量轮流时机和响应生成质量。
-
处理与元数据构建
- 使用 Whisper 和 FunASR 生成自动转录,以创建答案选项和评估参考。
- 选项通过排列说话人身份和内容进行合成,以将视觉 grounding 错误与语音识别错误隔离。
- 发布的元数据包括视频 URL、时间戳、转录片段、一致性标签和裁决标志,受许可限制约束。
方法
SocialOmni 框架旨在评估大型多模态模型的社会交互能力,特别关注跨不同领域的感知和生成任务。该基准包含跨越 15 个不同领域的 2209 个视频,围绕两个主要任务构建,评估模型理解社会线索和生成适当响应的能力。
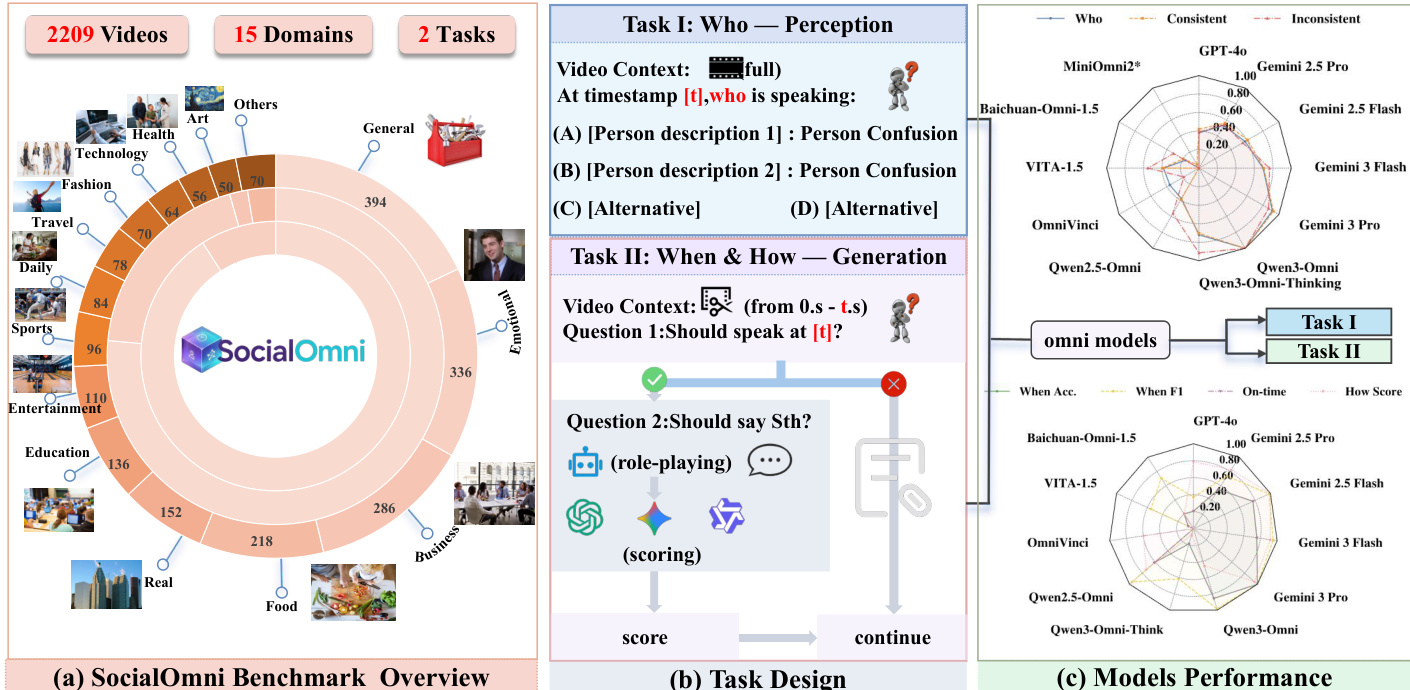
核心处理管道分为三个区域以处理上下文对齐和任务执行。区域 1 建立视频和音频上下文,识别特定时间戳和真实文本。区域 2 执行视听一致性检查。系统分析视觉说话人是否与活动音频源匹配。例如,如果视觉显示一个人嘴唇闭合,而音频指示相反一侧有活跃声音,则输入被标记为不一致。这种一致性检查对于确定说话人归因的真实值至关重要。
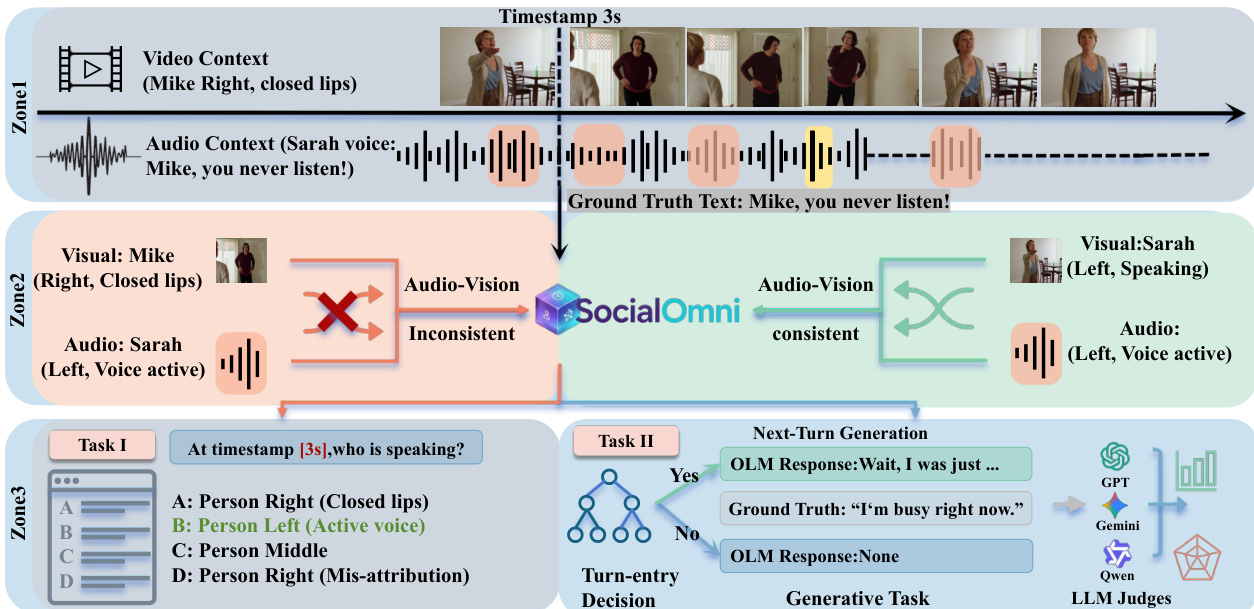
评估分为任务 I(感知)和任务 II(生成)。任务 I 要求模型使用 A 到 D 的多项选择题格式识别特定时间戳的说话人。任务 II 涉及两步生成过程。首先,模型必须决定是否适合说话(回合进入决策)。如果决策为肯定,模型继续执行生成任务,产生自然响应。然后由 LLM 评判器评估这些输出以评估质量和相关性。
为了量化时机准确性,作者基于响应偏移 Δτi=τ^i−τi∗ 定义了时机标签 ci。响应分为五类:如果 Δτi<−θ1 则为 INTERRUPTED,如果 −θ1≤Δτi≤θ2 则为 PERFECT,如果 θ2<Δτi≤θ3 则为 DELAYED,如果 Δτi>θ3 则为 TOOLATE,如果没有生成输出则为 NO RESPONSE。默认阈值设置为 (θ1,θ2,θ3)=(1,2,5) 秒。

最后,系统采用带有严格解析约束的固定提示卡,以最小化不同模型 API 之间的差异。对于"Who"任务,模型必须输出单个选项字母。对于"When"任务,仅接受明确的 YES 或 NO 输出。对于"How"任务,保留非空延续用于评判,空响应记录为无响应。
实验
SocialOmni 基准评估了十二个全模态大语言模型在社会交互性的三个维度:说话人识别、打断时机和自然响应生成。实验表明,没有单一模型主导所有轴,突出了显著的解耦,即强大的感知准确性并不能保证高质量的对话生成。诊断分析确定了系统故障模式,如跨模态时间不连贯和过早打断,表明当前系统难以将视觉 grounding 与对话流对齐。这些结果表明,以理解为中心的基准不足以表征社会能力,并激发了专门针对交互的评估。
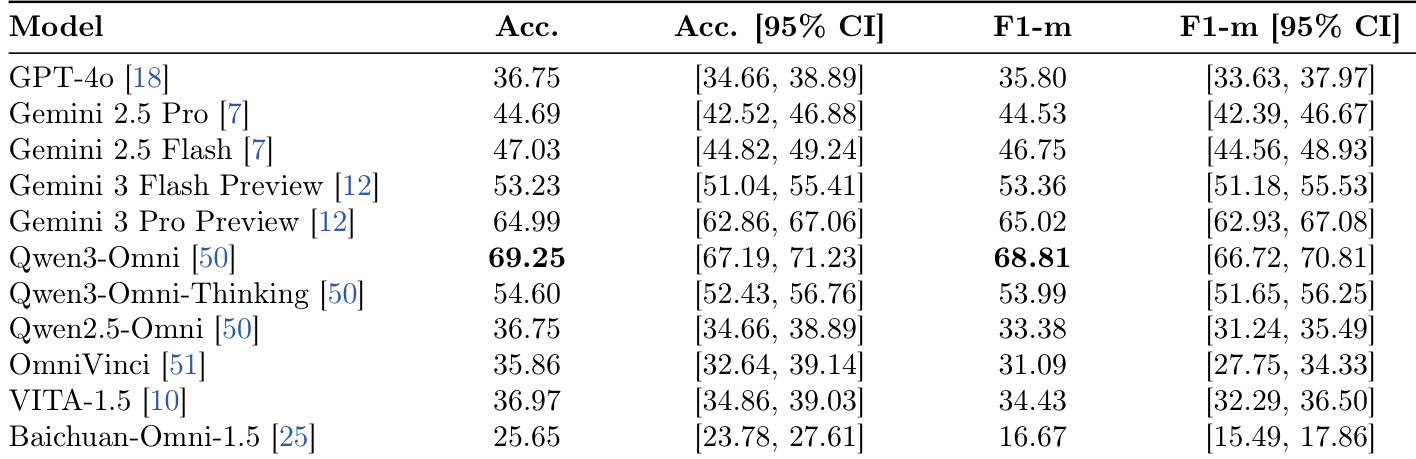
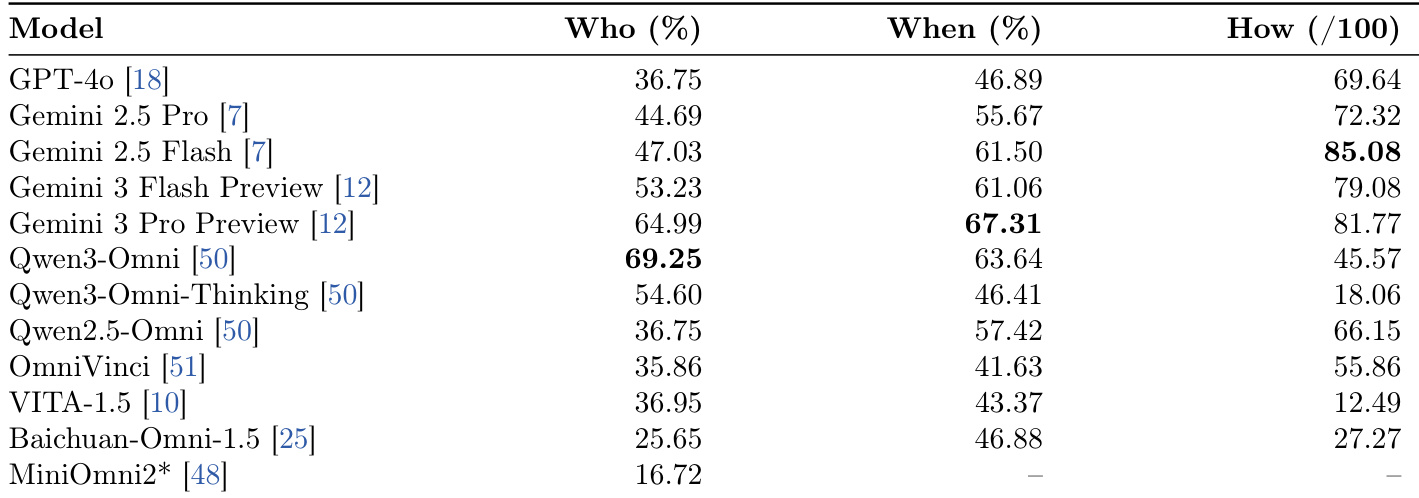
该表展示了说话人识别任务的评估结果,比较了各种全模态模型的准确率和宏观 F1 分数。Qwen3-Omni 实现了最高的性能指标,超过了 Gemini 3 Pro Preview 和 GPT-4o 等商业模型。能力存在明显差异,顶级模型显著优于排名较低的开源替代方案。Qwen3-Omni 以最高的准确率和宏观 F1 分数领先比较。商业模型通常表现良好,但未超越顶级开源模型。性能差异很大,一些模型的得分远低于领先者。
该研究评估了十二个全模态模型在社会交互的三个维度:说话人识别、打断时机和响应生成。结果显示,没有单一模型主导所有轴,特定模型在感知方面领先,而其他模型在生成质量方面表现出色。此外,商业系统通常优于开源对应产品,特别是在产生上下文适当的对话延续方面。每个维度都出现了独特的领导者,Qwen3-Omni 在说话人识别方面领先,Gemini 2.5 Flash 在响应质量方面领先。感知和生成之间存在解耦,因为具有高说话人识别准确率的模型不一定产生自然的打断。商业 API 在生成响应的流畅性和相关性方面显示出相对于开源模型的重大优势。
作者展示了模型在完整基准上的性能与人类在具有挑战性的选定子集上的性能之间的比较。人类在选定子集的说话人识别和时机控制方面表现出明显高于平均模型的准确性。虽然完整基准上的顶级模型在响应质量上的得分高于选定子集上的人类,但它们在感知和时机任务上仍不及人类表现。人类在选定子集的所有三个评估轴上均显著优于平均模型。完整基准上的最佳模型在选定子集上实现了比人类更高的生成质量分数,但在感知和时机方面表现不及人类。与完整基准相比,选定子集上的模型性能急剧下降,突显了处理困难场景的具体弱点。

该表展示了将模型性能与 SocialOmni 基准具有挑战性的子集上的人类判断进行比较的相关性统计。在" When"轴的项目级别观察到显著的负相关,表明模型经常基于声学线索过早打断,而人类评级者优先考虑语义完成。相比之下,"When"轴的模型级别比较显示出宽置信区间,反映了由于评估模型数量有限而产生的不确定性。项目级别分析显示"When"轴存在负相关,表明模型时机策略与人类期望之间存在分歧。"Who"轴在项目级别显示出负相关但统计上不显著,表明在困难情况下说话人识别的弱对齐。"When"轴的模型级别比较产生了宽置信区间,表明由于评估模型的样本量小而导致的不确定性。

该表展示了各种全模态模型的说话人识别准确性,区分了一致视听线索片段与不一致线索片段的性能。它突出了不一致性差距,以测量模型在视觉和音频信号冲突时的鲁棒性。Qwen3-Omni 实现了最高的整体准确率和一致性率,优于商业 API 和开源替代方案。MiniOmni2 表现出最大的一致性差距,表明与其他模型相比,它对跨模态不对齐高度敏感。Qwen3-Omni-Thinking 显示出负一致性差距,在一致片段上的表现不如在不一致片段上,表明推理开销可能会阻碍简单的感知任务。
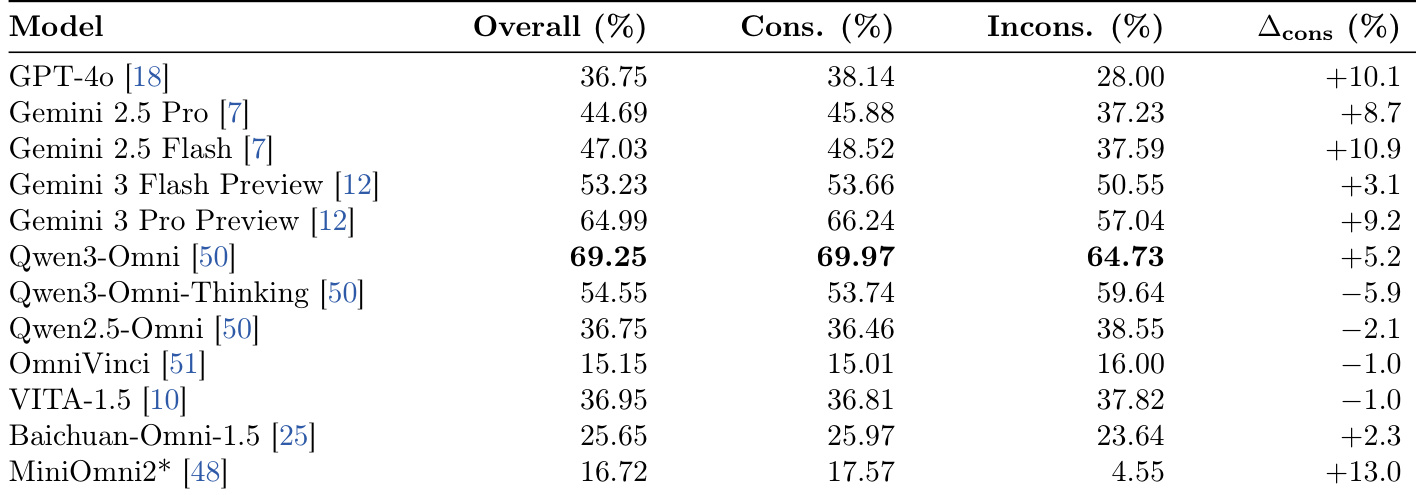
该研究评估了十二个全模态模型在社会交互维度,包括说话人识别、打断时机和响应生成,结果显示没有单一系统主导所有轴。虽然商业系统通常在生成质量方面表现出色,但 Qwen3-Omni 在感知任务方面领先,然而人类在具有挑战性的子集上在时机和识别准确性方面显著优于模型。此外,分析表明模型和人类时机策略之间存在分歧,以及对冲突视听线索的鲁棒性各不相同,其中推理开销可能会阻碍简单的感知。