Command Palette
Search for a command to run...
多模态 OCR:解析文档中的一切内容
多模态 OCR:解析文档中的一切内容
摘要
我们提出了 Multimodal OCR (MOCR),这是一种将文本与图形共同解析为统一文本表示的文档解析范式。传统的 OCR 系统通常侧重于文本识别,而将图形区域仅视为裁剪后的像素,与此不同,我们称之为 dots.mocr 的方法将图表(charts)、图解(diagrams)、表格(tables)和图标(icons)等视觉元素视为“一等公民”(first-class)解析目标,使系统能够在解析文档的同时,保留各元素之间的语义关系。该方法具有以下优势:(1) 它将文本和图形均重构为结构化输出,从而实现更忠实于原件的文档重构;(2) 它支持对异构文档元素进行端到端(end-to-end)训练,使模型能够充分利用文本与视觉组件之间的语义关系;(3) 它将此前被丢弃的图形转换为可复用的代码级监督信号,从而释放了现有文档中所蕴含的多模态监督信息。为了使这一范式具备大规模应用的实用性,我们构建了一个涵盖 PDF、渲染网页及原生 SVG 资产的全面数据引擎,并通过阶段式预训练(staged pre-training)和监督微调(supervised fine-tuning)训练了一个仅有 3B 参数的紧凑型模型。我们从文档解析和结构化图形解析两个维度对 dots.mocr 进行了评估。
一句话总结
所提出的多模态 OCR (MOCR) 范式利用 dots.mocr 模型,通过将图表、图解、表格和图标等元素视为一等目标,将文本和图形共同解析为统一的文本表示,从而通过结构化的代码级输出实现端到端训练和忠实的文档重建。
核心贡献
- 本文引入了多模态 OCR (MOCR),这是一种文档解析范式,将文本、图表、图解、表格和图标视为一等解析目标,并将其转换为统一的、可渲染的文本表示。
- 所提出的 dots.mocr 方法通过将视觉组件重建为结构化代码而非简单的像素裁剪,实现了对异构文档元素的端到端训练,使模型能够利用文本与图形之间的语义关系。
- 研究人员开发了一个综合数据引擎,利用 PDF、网页和 SVG 资产来训练一个 3B 参数的模型,并通过一个新的 OCR Arena 框架进行评估,该框架旨在处理结构复杂性和表示多样性。
引言
有效的文档解析对于预训练和检索系统至关重要,因为它决定了从 PDF 和扫描件等海量数据集中恢复结构化知识的质量。传统的 OCR 流水线主要以文本为中心,侧重于字符识别,而将图表、图解和图标视为简单的像素裁剪。这种方法本质上是有损的,因为它丢弃了编码在文档图形中的关键语义和结构信息。
通过采用一种称为多模态 OCR (MOCR) 的新范式,文本和视觉元素均被视为一等解析目标。通过 dots.mocr 系统,文档图形被转换为可重用的、可渲染的 SVG 代码,而非静态的栅格图像。为了克服稀疏监督和非唯一程序表示等挑战,研究人员开发了一个综合数据引擎和分阶段训练方案,利用归一化和基于渲染的验证。这种方法使紧凑的 3B 参数模型在文档解析和结构化图形重建方面均达到了最先进的性能。
数据集
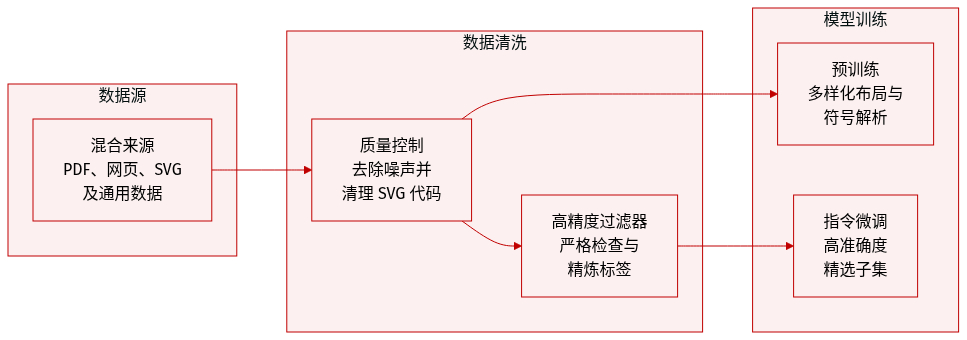
研究人员开发了一个专门的数据引擎,旨在训练用于多模态光学字符识别 (MOCR) 的模型,重点关注文本解析以及将视觉符号转换为结构化格式。
-
数据集组成与来源 训练语料库由四个主要来源组成:
- PDF 文档: 用于多语言文档解析和布局识别。
- 网页: 通过爬取并渲染为图像,提供高分辨率、复杂布局以及来自 HTML/DOM 的结构信号。
- SVG 图形: 用于教导模型将图标、图表和图解解析为可重用代码而非栅格裁剪的原生资产。
- 通用数据: 通用的视觉和 OCR 监督数据,例如 grounding 和计数,以保持广泛的模型鲁棒性。
-
子集详情与处理
- PDF 处理: 使用 dots.ocr 作为自动标注引擎来生成结构化转录,包括布局区域和阅读顺序。通过基于语言、领域和布局复杂度(例如文本密度和表格存在情况)的分层采样进行筛选。
- SVG 处理: 对 SVG 资产采用两阶段流水线。首先,通过 svgo 进行清理以移除元数据并标准化代码。其次,使用文本匹配和感知哈希 (pHash) 进行去重。采样根据领域和 SVG 程序复杂度进行平衡。
- 网页处理: 网页被转换为与 PDF 相同的解析格式,利用 HTML/DOM 信号来减少标签噪声。
-
训练与指令微调
- 预训练: 应用轻量级质量控制以在保持数据多样性的同时去除噪声。
- 指令微调: 为指令微调筛选了一个较小的、高精度的子集。该子集通过基于规则的完整性检查以及与输入页面的基于渲染的对比进行更严格的验证。
- 蒸馏: 使用蒸馏技术对样本进行重新标注或过滤,纠正常见错误,从而为模型提供更强的监督。
方法
MOCR 框架旨在将多样化的页面级解析任务(包括文档解析、网页和 UI 解析、场景文本解析以及结构化图形解析)统一到一个单一且内聚的模型中。通过不仅恢复文本,还将视觉符号恢复为可重用的、可渲染的代码(如 SVG),研究人员将文档和屏幕转化为一个丰富的数据引擎。这种方法为预训练和检索提供了可扩展的监督,其范围超出了简单的栅格裁剪。
如框架图所示:

模型架构由三个主要组件组成:高分辨率视觉编码器、轻量级多模态连接器和自回归语言模型 (LLM) 解码器。视觉编码器是一个 1.2B 参数的主干网络,从零开始训练,以开发原生为文档解析优化的特征表示。这允许对密集文本和对几何敏感的视觉符号(如图表和图解)进行联合建模。编码器经过设计,可以摄取高达约 11M 像素的原生高分辨率输入,这对于保留细粒度细节并在整个页面上维持长程空间一致性至关重要。
对于自回归解码器,使用了 Qwen2.5-1.5B。选择这一特定规模是为了平衡容量与成本,因为较小的模型通常难以处理异构页面内容并生成长且高度结构化的输出(如 SVG 程序),而较大的解码器会显著增加训练和推理成本。
训练过程遵循数据驱动的课程学习,旨在通过三个连续阶段稳定多任务联合训练。第一阶段通过通用视觉训练建立稳定的视觉语言接口。第二阶段在通用视觉数据和纯文本文档解析监督的混合数据上进行广泛预训练。在第三阶段,混合数据向 MOCR 特定目标转移,增加了对多模态文档解析和图像到 SVG 任务的侧重。
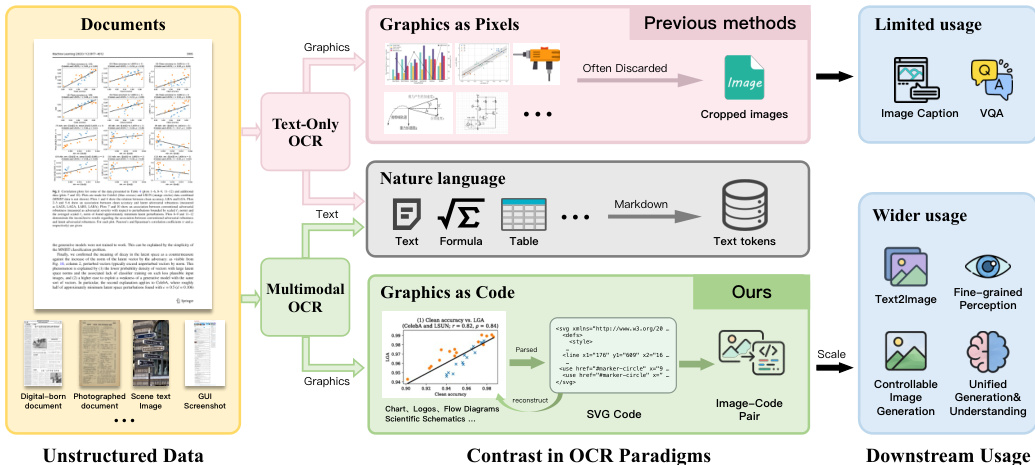
预训练之后,模型使用高质量监督集进行指令微调。此阶段侧重于提高端到端解析的忠实度并对齐输出规范。对于视觉符号解析,实施了针对 SVG 的处理,包括规范化和 viewBox 归一化,以确保目标一致性。这种从将图形视为纯像素到将其视为结构化代码的转变,代表了 OCR 范式的根本性转变。

实验
评估采用了 Elo 风格的成对比较协议,使用 VLM 作为裁判来评估文档解析,使用基于渲染与对比的重建指标来评估结构化图形,并使用各种基准测试来评估通用视觉语言能力。结果表明,dots.mocr 在文本语言解析方面在开源模型中达到了最先进的性能,并在将复杂的视觉符号(如图表和科学图解)重建为 SVG 代码方面表现出色。此外,该模型保持了极具竞争力的通用推理和视觉 grounding 能力,证明了专门的多模态解析不会损害更广泛的视觉语言性能。
通过对 ArXiv 论文、旧数学扫描件、表格和多栏布局等各种专业类别进行文档解析性能评估。结果显示,dots.mocr 在对比系统中实现了最高的整体性能,特别是在数学和表格内容方面表现优异。dots.mocr 获得了最高的总分,并在 ArXiv、表格和多栏布局等多个特定类别中处于领先地位。其他模型在页眉、页脚等特定领域表现出竞争力。不同文档类型的性能差异显著,某些模型专门针对旧扫描件或特定的布局结构进行了优化。

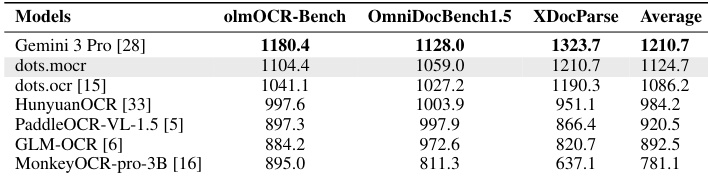
在三个文档解析基准测试中对比了各种视觉语言模型的 Elo 性能。结果显示,虽然 Gemini 3 Pro 获得了最高分,但 dots.mocr 在列出的开源模型中表现出优越的性能。dots.mocr 在评估的开源模型中获得了最高的平均 Elo 评分。模型通过 olmOCR-Bench、OmniDocBench1.5 和 XDocParse 使用 Elo 风格的成对比较协议进行对比。Gemini 3 Pro 在所有三个独立基准测试中均保持领先排名。
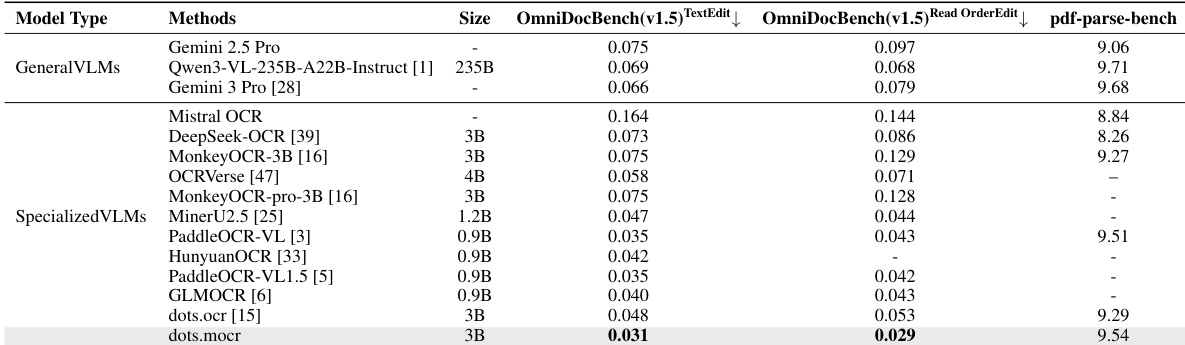
在多个文档解析基准测试中对比了各种通用和专门的视觉语言模型。结果显示,专门的 dots.mocr 模型实现了具有竞争力的性能,特别是在与其它专门模型相比的文本编辑和阅读顺序相关指标方面表现优异。在评估的专门模型中,dots.mocr 模型在文本编辑任务中表现出卓越的性能。专门的 VLM 在特定的文档解析指标上通常优于或匹配通用 VLM。结果表明,相对于其他专门的竞争对手,dots.mocr 在阅读顺序和文本编辑基准测试中获得了高分。
通过各种文档理解和多模态推理基准测试评估了 dots.mocr 的通用视觉语言能力。结果显示,与强大的通用基准模型相比,dots.mocr 保持了极具竞争力的性能。dots.mocr 在涉及描述性和推理设置的 CharXiv 任务中展现出明显优势。该模型在下游文档 VQA 和图表理解任务中取得了强劲的结果。在广泛的视觉 grounding 和推理基准测试中,性能依然稳健。

使用基于重建的指标在多个视觉领域评估了结构化图形解析性能。结果显示,dots.mocr-svg 获得了最高的整体重建分数,并在大多数下游基准测试中优于开源基准和闭源的 Gemini 3 Pro。与其他测试方法相比,dots.mocr-svg 在通用矢量图形重建方面表现出卓越的性能。该模型在图表模拟和化学图解重建等对结构敏感的任务中展现出显著优势。该模型的专门 svg 版本在大多数布局和科学插图基准测试中一致获得更高分数。

在多样化的文档解析、多模态推理和结构化图形重建基准测试中评估了 dots.mocr 及其专门变体。结果表明,dots.mocr 在开源模型中实现了最先进的性能,特别是在数学内容、表格数据和阅读顺序准确性方面表现优异。此外,专门的 dots.mocr-svg 变体在重建复杂的科学图解和矢量图形方面优于开源和闭源基准。