Command Palette
Search for a command to run...
OpenClaw-RL:仅需对话即可训练任意 Agent
OpenClaw-RL:仅需对话即可训练任意 Agent
Yinjie Wang Xuyang Chen Xiaolong Jin Mengdi Wang Ling Yang
摘要
每一个智能体(Agent)交互都会生成一个“下一状态”信号,即紧随每个动作之后的用户回复、工具输出、终端或图形用户界面(GUI)状态变更。然而,现有的智能体强化学习(RL)系统均未将其作为实时在线的学习源加以利用。本文提出 OpenClaw-RL,这是一个基于一个简单观察而构建的框架:下一状态信号具有普遍性,策略可以同时从所有此类信号中学习。个人对话、终端执行、GUI 交互、软件工程(SWE)任务以及工具调用轨迹并非相互独立的训练问题;它们都是可在同一训练循环中用于训练同一策略的交互形式。下一状态信号编码了两类信息:一是评估性信号,用于指示动作执行的效果,可通过过程奖励模型(PRM)评判器提取为标量奖励;二是指导性信号,用于指示动作本应如何调整,并通过“后见之明引导的在线策略蒸馏”(Hindsight-Guided On-Policy Distillation, OPD)进行恢复。我们从下一状态中提取文本提示,构建增强的教师上下文,并提供比任何标量奖励都更为丰富的令牌级方向性优势监督。得益于其异步架构设计,模型可实时处理请求,PRM 评判器可在线评估正在进行的交互,而训练器则同步更新策略,三者之间无需任何协调开销。在个人智能体场景中,OpenClaw-RL 使智能体能够仅通过被使用而持续改进,自动从用户的重新查询、修正操作及显式反馈中恢复对话信号。在通用智能体场景中,同一基础设施支持在终端、GUI、SWE 及工具调用等多种设置下进行可扩展的强化学习,并进一步展示了过程奖励(process rewards)的实际效用。代码仓库:https://github.com/Gen-Verse/OpenClaw-RL
一句话总结
OpenClaw 的作者提出了 OpenClaw-RL,这是一个统一的框架,通过二元强化学习和后见之明引导的在线策略蒸馏,将通用的下一状态信号转化为实时的在线学习源。该方法能够在不中断服务的情况下,针对终端、图形用户界面(GUI)和软件工程等多样化场景,持续优化个人代理和通用代理的策略。
主要贡献
- OpenClaw-RL 解决了 AI 代理中下一状态信号被丢弃的问题,它将用户回复、工具结果和错误追踪视为隐式的、自由形式的评估,而不仅仅是未来行动的上下文。
- 该框架引入了一种统一的异步架构,通过 PRM 评判器恢复标量过程奖励,并通过来自实时交互数据的后见之明引导的在线策略蒸馏(OPD)恢复令牌级方向性监督。
- 实验表明,结合这些方法显著提升了个人代理在对话场景中的表现,以及通用代理在终端、GUI、软件工程(SWE)和工具调用环境中的表现,为长视野任务提供了密集的信用分配。
引言
已部署的 AI 代理会持续生成有价值的下一状态信号,例如用户回复或测试结果,但当前系统仅将这些数据视为未来行动的上下文,而非实时学习的来源,从而将其丢弃。现有的强化学习方法通常依赖离线批量数据、缺乏步骤级粒度的标量结果奖励,或预先策划的反馈对,这阻碍了真实世界部署期间的持续优化。作者介绍了 OpenClaw-RL,这是一个统一的异步基础设施,能够恢复这些隐式信号,从而为个人代理和通用代理启用在线训练。该框架利用过程奖励模型(PRM)从实时交互中提取密集的步骤级奖励,并采用后见之明引导的在线策略蒸馏,将文本错误追踪转化为方向性的令牌级监督,而无需外部标注者。
数据集
-
数据集构成与来源:作者整理了一个多场景数据集,以支持终端、GUI、软件工程(SWE)和工具调用代理,该数据集结合了四个不同的来源:SETA RL 数据、OSWorld-Verified、SWE-Bench-Verified 和 DAPO RL 数据。
-
每个子集的关键细节:
- 终端代理:基于 SETA RL 数据进行训练,以利用高效的基于文本的接口。
- GUI 代理:基于 OSWorld-Verified 数据进行训练,以处理视觉界面和指针交互,评估仅限于排除 Chrome 和多应用任务后的训练集。
- SWE 代理:基于 SWE-Bench-Verified 数据进行训练,以利用丰富的可执行反馈(如测试和差异)。
- 工具调用代理:基于 DAPO RL 数据进行训练,以增强推理能力和事实准确性,评估在 AIME 2024 数学竞赛数据集上进行。
-
模型使用与训练策略:作者对每个子集应用特定的模型配置,终端任务使用 Qwen3-8B,GUI 任务使用 Qwen3VL-8B-Thinking,SWE 任务使用 Qwen3-32B,工具调用任务使用 Qwen3-4B-SFT。终端和 SWE 代理的性能通过计算强化学习步骤窗口内的 rollout 任务准确率平均值来衡量。
-
处理与元数据构建:对于 GUI 代理评估,作者构建了一个严格的步骤级反馈提示,该提示结合了文本指令、历史操作以及操作前后环境状态的 base64 编码图像。该提示指示评估器根据操作是否相关、可执行以及是否导致向目标取得具体进展,分配 +1 或 -1 的二元分数。
方法
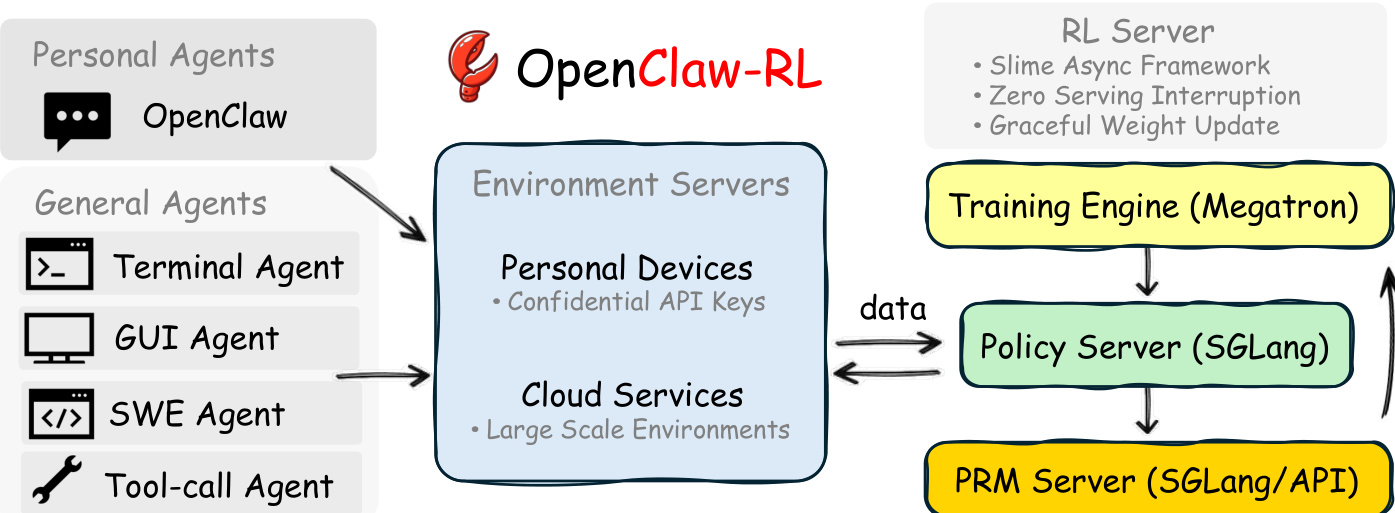
OpenClaw-RL 框架基于以下观察:下一状态信号(如用户回复或工具输出)编码了关于代理行动的评估性和指令性信息。该系统通过一个完全异步的流水线统一了个人代理和通用代理的训练,该流水线解耦了策略服务、环境托管、奖励评判和策略训练。请参阅框架图以了解整体架构。该基础设施将个人代理和通用代理连接到环境服务器,分别处理机密 API 密钥和大规模环境。这些服务器将数据输入到包含训练引擎(Megatron)、策略服务器(SGLang)和 PRM 服务器的 RL 服务器中。这种解耦设计确保了模型可以在服务实时请求的同时,由 PRM 评判交互,且训练器更新权重而不会阻塞依赖。
学习过程通过两种互补的方法利用下一状态信号。如下图所示,该框架支持用于评估信号的二元强化学习(Binary RL)和用于指令信号的在线策略蒸馏。在二元强化学习方法中,PRM 评判器根据下一状态 st+1 评估行动 at 的质量,产生标量奖励 r∈{+1,−1,0}。该奖励作为标准 PPO 风格截断代理目标中的优势 At。
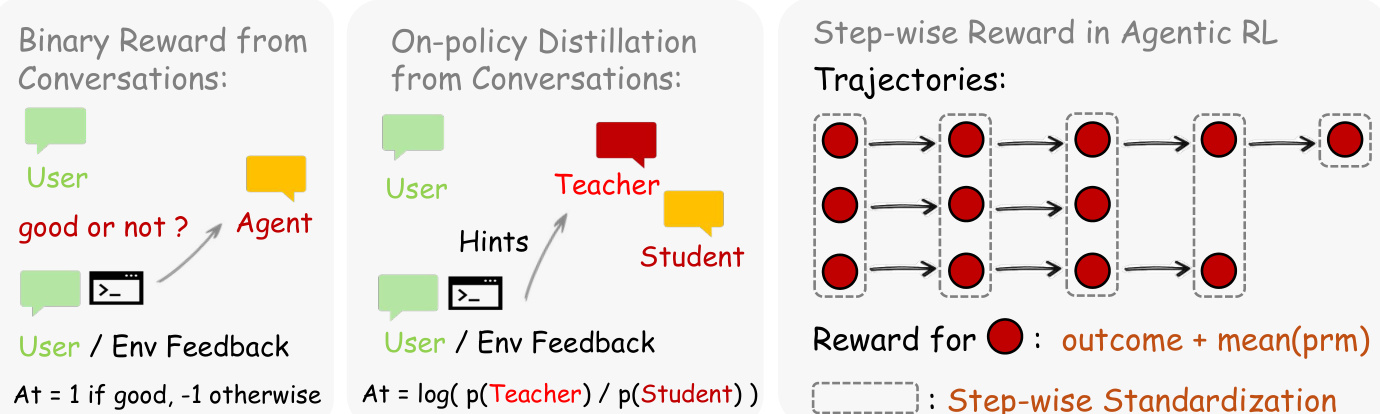
为了更细粒度的改进,后见之明引导的在线策略蒸馏(OPD)从下一状态中提取文本提示,以构建增强的教师上下文。优势计算为教师模型(基于提示进行条件化)与学生模型之间的每令牌对数概率差距: At=logπteacher(at∣senhanced)−logπθ(at∣st) 这提供了令牌级的方向性指导,指示哪些令牌应该被加权或减权。对于通用代理,系统进一步将步骤级奖励与结果奖励集成,利用步骤级标准化来处理长视野轨迹。作者通过加权各自的优势来结合这两种方法,使策略既能通过标量奖励获得广泛覆盖,又能通过蒸馏获得高分辨率的修正。
实验
- 个人代理赛道验证了对话式下一状态信号能够实现持续个性化,组合优化方法的表现优于二元强化学习和在线策略蒸馏,帮助代理在最少交互后采用自然的写作风格并提供更友好的反馈。
- 通用代理赛道表明,该统一基础设施通过大规模环境并行化,支持终端、GUI、软件和工具调用场景的可扩展强化学习。
- 实验证实,尽管需要额外的资源,但将过程奖励模型与结果奖励集成相比仅使用结果的方法,能为长视野任务带来更强的优化效果。