Command Palette
Search for a command to run...
ReMix:LLM 微调中 LoRA 混合模型的强化路由机制
ReMix:LLM 微调中 LoRA 混合模型的强化路由机制
摘要
低秩适配器(LoRA)是一种参数高效的微调技术,它通过在预训练模型中注入可训练的低秩矩阵,使其适应新任务。混合低秩适配器(Mixture-of-LoRAs, MoLoRA)模型通过将每一层的输入路由至该层中一小部分专用 LoRA,从而高效地扩展神经网络。现有的 MoLoRA 路由器为每个 LoRA 分配一个可学习的路由权重,以实现路由器的端到端训练。尽管这些方法在实证上展现出潜力,但我们观察到,在实际应用中,各 LoRA 的路由权重通常极度不平衡:往往仅有一两个 LoRA 主导了路由权重分配。这一现象实质上限制了有效 LoRA 的数量,从而严重削弱了现有 MoLoRA 模型的表达能力。本文将这一缺陷归因于可学习路由权重本身的特性,并重新审视路由器的基础设计。为解决这一关键问题,我们提出了一种新型路由器,命名为“混合低秩适配器的强化路由”(Reinforcement Routing for Mixture-of-LoRAs, ReMix)。我们的核心思想是:采用不可学习的路由权重,确保所有被激活的 LoRA 均具有同等有效性,避免任一 LoRA 主导权重分配。然而,由于路由权重不可学习,路由器无法直接通过梯度下降进行训练。为此,我们进一步提出了一种无偏梯度估计器,该估计器基于强化学习中的“留一法强化”(Reinforce Leave-One-Out, RLOO)技术:将监督损失视为奖励信号,将路由器视为策略网络。该梯度估计器还支持扩展训练计算规模,从而进一步提升 ReMix 的预测性能。大量实验表明,在激活参数量相当的情况下,我们提出的 ReMix 显著优于现有的最先进参数高效微调方法。
一句话总结
伊利诺伊大学厄巴纳 - 香槟分校与 Meta AI 的研究人员提出了 ReMix,这是一种新颖的 LoRA 混合(Mixture-of-LoRAs)框架,它用不可学习的路由权重替代可学习权重,以防止路由器坍塌。通过采用无偏梯度估计器和 RLOO 技术,ReMix 确保所有激活的适配器贡献均等,在严格参数预算下显著优于现有的参数高效微调方法。
主要贡献
- 现有的 LoRA 混合模型存在路由权重坍塌问题,即学习到的权重往往集中在单个适配器上,这实际上浪费了其他激活 LoRA 的计算资源,并限制了模型的表达能力。
- 作者提出了 ReMix,这是一种新颖的路由器设计,强制所有激活的 LoRA 使用恒定的不可学习权重,以确保贡献均等,防止任何单个适配器主导路由过程。
- 为了在使用这些不可微分权重时进行训练,论文引入了一种基于强化学习留一法(Reinforce Leave-One-Out)技术的无偏梯度估计器,使得 ReMix 在严格参数预算下,于多种基准测试中显著优于最先进的方法。
引言
低秩适配器(LoRAs)通过在冻结的权重中注入可训练矩阵,实现了大型语言模型的高效微调;而 LoRA 混合架构旨在通过将输入路由到这些适配器的专用子集,进一步提升模型容量。然而,现有的依赖可学习路由权重的方法存在一个关键缺陷:权重会坍塌到单个主导 LoRA,从而实际上浪费了其他激活适配器的计算资源,并限制了模型的表达能力。为解决这一问题,作者引入了 ReMix,这是一种强化路由框架,它通过使用不可学习的恒定权重强制所有激活 LoRA 贡献均等,并基于 REINFORCE 留一法技术利用无偏梯度估计器来训练路由器。
方法
作者提出了 ReMix,这是一种专为 LoRA 混合设计的强化路由方法,旨在缓解路由权重坍塌。该方法从根本上改变了适配器架构和训练流程,以确保 LoRA 的多样化利用。
在适配器架构中,路由器针对给定层的输入,在可用的 LoRA 上计算一个分类分布 q(l)。模型不使用这些概率作为连续权重,而是选择 k 个 LoRA 的子集。关键在于,这些激活 LoRA 的路由权重被设定为常数 ω,而未激活的 LoRA 则获得零权重。这种设计保证了有效支持集大小固定为 k,防止路由器将概率质量集中在单个 LoRA 上。随后,层输出被计算为冻结模型输出与所选 LoRA 加权贡献之和。
为了训练路由器参数,作者通过将离散选择过程框架化为强化学习问题,解决了其不可微分性。SFT 损失作为负奖励信号。在微调过程中,模型采样 M 个不同的 LoRA 子集选择。对于每个选择,计算 SFT 损失。这些损失随后用于通过 RLOO 梯度估计器估算路由器参数的梯度。该估计器利用以样本间平均损失作为基线的方差缩减技术。梯度估计器定义为: GP(l):=M−11∑m=1M(L(Jm)−L)∇P(l)logQ(Jm) 其中 L 表示 M 个选择间的平均 SFT 损失。
如下图所示,该框架可视化了 ReMix 架构,其中路由器生成选择概率,指导多个层中特定 LoRA 池的激活。该过程涉及生成多个选择,计算每个选择的 SFT 损失,并通过 RLOO 梯度估计器聚合这些信号以更新路由器。
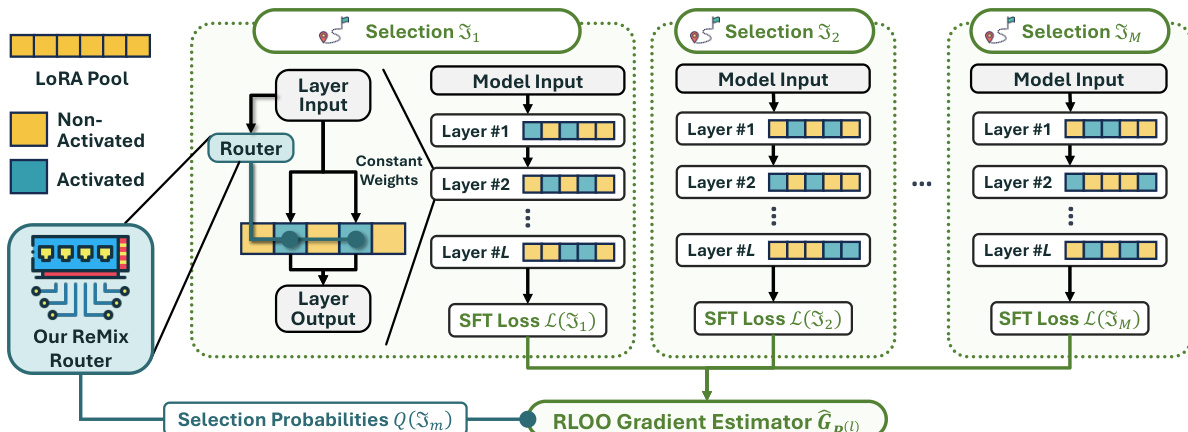
在推理阶段,作者采用 top-k 选择策略。理论分析表明,如果路由器经过充分训练,选择概率最高的 k 个 LoRA 即可保证获得最优子集。这种确定性方法优于训练期间使用的随机采样。
实验
- 对现有 LoRA 混合方法的分析揭示了一个关键的路由权重坍塌问题:每层仅有一个 LoRA 占主导地位,严重限制了模型表达能力,并使其他 LoRA 失效。
- 提出的 ReMix 方法在数学推理、代码生成和知识回忆任务中,始终优于各种基线模型,同时保持了卓越的参数效率。
- 与单秩 kr LoRA 的对比表明,ReMix 成功激活了多样化的 LoRA 子集,而非依赖固定子集,验证了其利用混合容量的能力。
- 消融实验证实,RLOO 训练算法和 top-k 选择机制都是实现峰值性能的关键组件。
- 实验表明,ReMix 受益于增加激活 LoRA 的数量以及通过采样选择增加训练计算量,而确定性基线模型无法利用额外的计算资源。
- 该方法对不同的路由权重初始化方案表现出鲁棒性,无论使用何种具体的权重配置,均能保持稳定的性能。