Command Palette
Search for a command to run...
MA-EgoQA:基于多具身智能体的第一人称视频问答
MA-EgoQA:基于多具身智能体的第一人称视频问答
Kangsan Kim Yanlai Yang Suji Kim Woongyeong Yeo Youngwan Lee Mengye Ren Sung Ju Hwang
摘要
随着具身模型能力的不断提升,未来人类将在工作场所或家庭环境中与多个具身人工智能(Embodied AI)代理协同工作。为确保人类用户与多代理系统之间实现高效沟通,关键在于能够并行解析来自各代理的输入信息,并针对每个查询精准调用相应上下文。当前面临的主要挑战包括:如何以视频形式有效压缩并传达海量的个体感官输入,以及如何正确聚合多个以第一人称视角(egocentric)采集的视频流,从而构建系统级记忆。本文首先正式定义了一个新问题:同时理解由多个具身代理同步采集的多个长时序第一人称视频。为推动该方向的研究,我们提出了 MultiAgent-EgoQA(MA-EgoQA)基准测试,旨在系统性地评估现有模型在该场景下的性能。MA-EgoQA 包含 1,700 个专用于多第一人称视频流的问题,涵盖五大类别:社会交互、任务协调、心智理论(Theory-of-Mind)、时序推理以及环境交互。此外,我们提出了一种针对 MA-EgoQA 的简单基线模型——EgoMAS。该模型通过共享具身代理间的记忆机制,并结合基于代理的动态检索策略,实现跨代理信息的有效整合。在 MA-EgoQA 上对多种基线方法及 EgoMAS 进行的全面评估表明,现有方法尚无法有效处理多路第一人称视频流,凸显出未来亟需在代理间系统级理解能力方面取得突破。相关代码与基准测试数据集已公开,访问地址为:https://ma-egoqa.github.io。
一句话总结
来自韩国科学技术院(KAIST)、纽约大学及其合作者的研究人员推出了 MA-EgoQA,这是一个用于回答跨多个长时程第一人称视频流问题的基准测试;同时提出了 EgoMAS,这是一种利用共享内存和动态检索的基线模型,在复杂的多智能体场景中表现优于现有模型。
主要贡献
- 本文解决了从多个具身智能体解析并行感官输入的关键挑战,以实现有效的人机通信和系统级记忆聚合。
- 提出了 MultiAgent-EgoQA,这是一个新的基准测试,包含 1.7k 个问题,涵盖社交互动和时间推理等五个类别,源自长时程第一人称视频流。
- 作者提出了 EgoMAS,这是一种利用共享内存和动态检索的基线模型,其性能比现有方法高出 4.48%,并揭示了当前视频大语言模型在此任务上的局限性。
引言
随着具身智能体在家庭和工作场所等共享环境中日益普及,人类查询这些多智能体系统以进行进度监控或异常检测的能力,对于透明度和控制至关重要。先前的研究主要集中在任务分配和行动执行上,而在能够整合来自多个智能体的长时程第一人称视频流以回答复杂问题的系统方面存在显著空白。现有的视频模型难以处理数天内产生的海量数据,也无法有效地聚合不同智能体的经验以形成连贯的系统级记忆。为此,作者推出了 MA-EgoQA,这是一个新的基准测试,包含源自六个智能体在七天内操作的 1.7k 个问题,涵盖五个推理类别。他们还提出了 EgoMAS,这是一种利用共享内存和智能体级动态检索的基线模型,能够高效定位相关事件,证明了当前的最先进模型尚无法处理多智能体第一人称理解的复杂性。
数据集
MA-EgoQA 数据集概览
-
数据集构成与来源 作者利用 EgoLife 数据集构建了 MA-EgoQA,该数据集包含六名佩戴摄像眼镜的个体在共享房屋中连续七天的超长第一人称视频记录。这一基础使得该基准能够评估跨多个时间对齐视频流的推理能力,而不是依赖先前工作中常见的单智能体假设。
-
各子集的关键细节 该基准包含 1,741 个高质量的多项选择题,分布在五个独特的类别中,旨在捕捉独特的多智能体动态:
- 社交互动 (SI): 评估对话和亲和行为的 grounding,包括 15.9k 个生成的单跨度(single-span)和多跨度(multi-span)样本。
- 任务协调 (TC): 专注于角色分配和目标完成,包含 16.3k 个多跨度样本以及单跨度变体。
- 心智理论 (ToM): 评估对他人心理状态、信念和意图的推理。
- 时间推理 (TR): 分为并发和比较子类别,以测试跨智能体的时间线对齐。
- 环境交互 (EI): 追踪对象使用情况以及分布在智能体之间的环境状态变化。
-
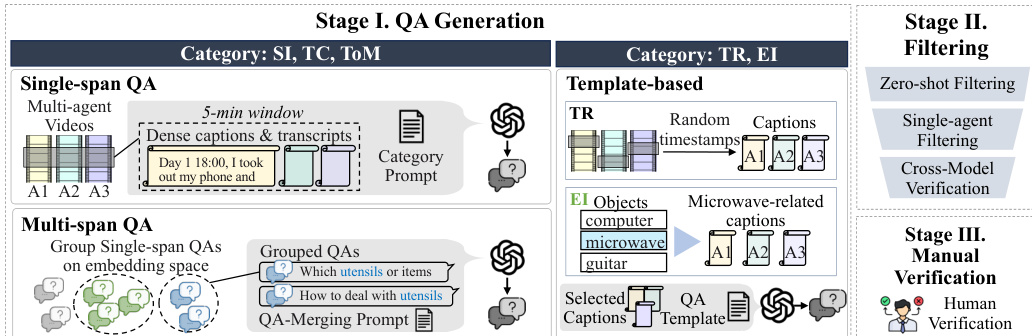
数据使用与生成策略 作者采用混合生成管道来创建数据集,利用 GPT-4o 和 GPT-5 生成候选项,随后进行严格的过滤。
- 开放式类别 (SI, TC, ToM): 团队通过向模型提供带有密集字幕和转录的 5 分钟视频片段,并指示其生成至少由两个智能体支撑的问题,从而生成大量样本池。
- 结构化类别 (TR, EI): 作者使用预定义模板和特定时间窗口(30 秒至 1 小时)来生成关于事件顺序和对象交互频率的查询。
- 多跨度构建: 对于 SI 和 TC,作者利用文本嵌入的余弦相似度将语义相似的单跨度问题分组,以合成需要跨非连续时间窗口进行推理的复杂问题。
-
处理与质量控制 为确保基准具有挑战性且严格针对多智能体,作者实施了多阶段过滤和验证流程:
- LLM 过滤: 候选项经过零样本测试以移除琐碎问题,并进行单智能体过滤以消除可由单人记忆回答的样本。
- 跨模型验证: 外部模型(Gemini-2.5-Flash 和 Claude-Sonnet-4)验证正确性和选项有效性,以防止模型特定偏差。
- 人工验证: 四名人工审查员对照完整视频和转录上下文手动检查 3,436 个候选项,最终选出 1,741 个样本作为基准。
方法
作者提出了 EgoMAS(第一人称多智能体系统),这是一种集中式、无需训练的基线模型,旨在解决多智能体第一人称推理的挑战。该系统通过包含基于事件的共享内存和智能体级动态检索机制的两阶段架构运行。
基于事件的共享内存 为了实现系统级的全局理解,系统聚合来自多个智能体的碎片化事件。每隔 10 分钟,每个具身智能体提供一段总结其观察结果的字幕。集中式管理器随后将这些个人字幕整合为系统级摘要。管理器并非生成扁平的文本浓缩,而是识别跨智能体的关键事件,并明确记录相应的 4W1H 字段:何时(When)、何事(What)、何地(Where)、何人(Who)以及如何(How)。这产生了一个连贯的全局记忆,在保留推理关键细节的同时对齐了智能体的视角。
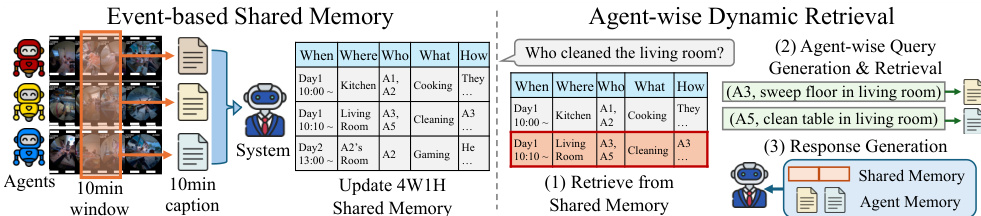
智能体级动态检索 给定查询 q,EgoMAS 采用分层检索策略以确保跨多个视角的细粒度推理。首先,系统使用 BM25 排序从共享内存 Mshared 中检索前 n 个系统级记忆:
Rsvs(q)=Top⋅n{(m,s(m,q))∣m∈Mshared},其中 s(m,q) 表示记忆 m 与查询 q 之间的 BM25 分数。从检索到的系统级上下文中,EgoMAS 生成一组智能体特定的检索请求 Qagent={(aj,qj)}j=1J,其中每个请求由智能体标识符 aj 和子查询 qj 组成。对于每个 (aj,qj),系统从特定智能体的内存 Mai 执行智能体级检索:
Rai(qj)=Top\textsl−k{(m,s(m,qj))∣m∈Mai}.为确保相关性,分数低于阈值 τ 的记忆将被过滤掉:
Rai(qj)={(m,s(m,qj))∈Rai(qj)∣s(m,qj)≥τ}.最后,系统通过基于检索到的系统级上下文 Rsys(q) 和聚合的智能体级结果 R=⋃i=1JRai(qj) 来生成最终响应:
y^=F(q,Rsys(q),R),其中 y^ 和 F 分别表示响应和响应生成函数。
基准生成流程 为了支持这项研究,作者还建立了一个严格的数据生成管道。该过程包括三个阶段:问答生成、过滤和人工验证。在第一阶段,根据单跨度问答、多跨度问答和基于模板的查询(TR, EI)等类别生成问题。第二阶段应用零样本过滤、单智能体过滤和跨模型验证以确保质量。最后,第三阶段涉及人工验证以确认数据集的有效性。
实验
- 在 MA-EgoQA 基准上的评估表明,当前模型难以处理多智能体第一人称视频理解,即使是顶级的专有模型也仅达到较低的准确率,凸显了该任务的难度。
- 比较输入策略的实验显示,直接拼接所有字幕或帧而不进行检索会引入噪声并带来高昂的计算成本,而基于检索的方法显著提高了效率和性能。
- EgoMAS 框架通过有效聚合来自多个智能体的记忆,优于所有基线模型,证明了多智能体记忆访问对于准确推理至关重要。
- 对子类别的分析表明,随着所需智能体数量或时间跨度的增加,性能会下降,而心智理论任务由于需要推断潜在的心理状态,仍然是最具挑战性的。
- 消融研究证实,EgoMAS 受益于将共享内存构建与智能体级动态检索相结合,且基于事件的内存结构优于其他方法。
- 敏感性分析表明,准确率随可用智能体数量的增加而提高,而模态实验表明,视觉帧对于特定查询至关重要,但如果未进行自适应选择,可能会干扰模型。