Command Palette
Search for a command to run...
Logics-Parsing-Omni 技术报告
Logics-Parsing-Omni 技术报告
Logics Team
摘要
针对多模态解析(multimodal parsing)中任务定义碎片化以及非结构化数据异构化带来的挑战,本文提出了 Omni Parsing 框架。该框架构建了一个涵盖文档、图像及音视频流的统一分类体系(Unified Taxonomy),并引入了一种连接感知(perception)与认知(cognition)的渐进式解析范式。具体而言,该框架整合了三个层级:1) 全域检测(Holistic Detection):实现对物体或事件精确的时空定位(spatial-temporal grounding),从而为感知建立几何基准;2) 细粒度识别(Fine-grained Recognition):对局部目标进行符号化(如 OCR/ASR)与属性提取,以完成结构化实体解析;3) 多层级释义(Multi-level Interpreting):构建从局部语义到全局逻辑的推理链。该框架的一个核心优势在于其证据锚定机制(evidence anchoring mechanism),该机制强制要求高层语义描述与底层事实之间保持严格对齐。这使得“基于证据”的逻辑归纳成为可能,从而将非结构化信号转化为可定位、可枚举且可追溯的标准知识。在此基础上,我们构建了一个标准化数据集,并发布了 Logics-Parsing-Omni 模型,该模型能够成功将复杂的音视频信号转换为机器可读的结构化知识。实验表明,细粒度感知与高层认知具有协同效应,能够有效增强模型的可靠性。此外,为了定量评估这些能力,我们还引入了 OmniParsingBench。
一句话总结
Logics 团队提出了 Omni Parsing 框架,该框架在文档、图像和视听流中利用渐进式解析范式,通过证据锚定机制整合层级化检测、识别与解读,使 Logics-Parsing-Omni 模型能够将非结构化信号转化为可追踪、机器可读的结构化知识,并通过 OmniParsingBench 进行了评估。
核心贡献
- 本文引入了 Omni Parsing 框架,通过连接感知与认知的渐进式范式,在文档、图像和视听流之间建立了统一的分类法。该框架利用证据锚定机制将高层语义描述与底层事实对齐,将非结构化信号转化为可定位、可枚举且可追踪的标准知识。
- 本研究提出了 Logics-Parsing-Omni,这是一种经过优化的先进多模态大语言模型 (MLLM),旨在实现全面的检测、细粒度识别和多层级解读。该模型采用以数据为中心的策略,包括丰富的知识密集型图像样本,以及针对镜头分析和长篇内容的优化视频标注,以确保输出具有丰富的语义且可验证。
- 研究人员开发了 OmniParsingBench,这是一个涵盖文档、图像和视听内容的标准化基准测试,用于定量评估全模态解析能力。在该基准上的实验结果表明,该模型达到了最先进的性能,并在所有模态之间保持了结构忠实度与语义解读之间的强有力平衡。
引言
有效的多模态解析对于检索增强生成 (RAG) 和智能教学等知识密集型应用至关重要,在这些应用中,模型必须处理复杂的文档、图像和长视频。现有方法通常面临结构性困境:底层提取工具缺乏语义深度,而高层生成模型往往缺乏布局忠实度和细粒度定位。这种差距导致图表信息丢失、图像描述产生幻觉以及视听转录文本缺乏结构粒度。为了应对这些挑战,本文提出了 Omni Parsing 框架,引入了一种渐进式范式来桥接基于像素的感知与基于逻辑的认知。通过由全面检测、细粒度识别和多层级解读组成的三层层级化方法,将非结构化信号转化为标准化的、可追踪的知识。为了支持该框架,本文还发布了 Logics-Parsing-Omni 模型和 OmniParsingBench 评估套件。
数据集
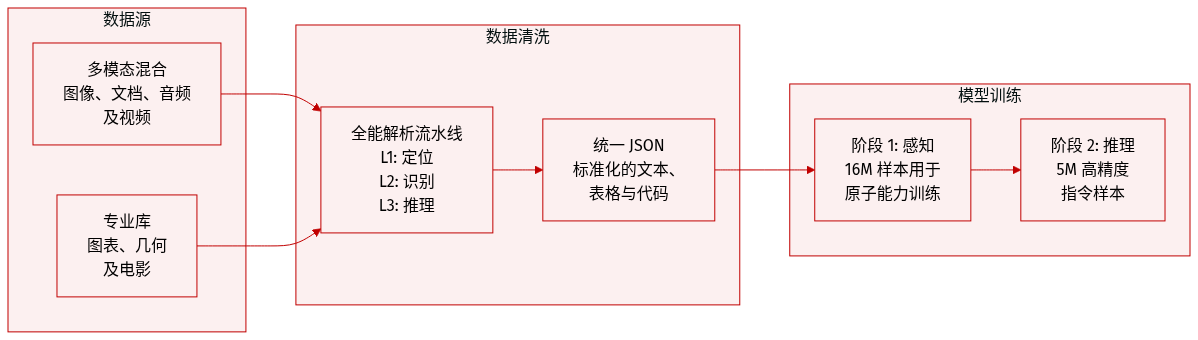
本文构建了一个大规模、多样化且高质量的语料库,旨在实现涵盖四个主要领域的统一多模态解析:图像、文档、音频和视频。
数据集组成与子集
- 图像领域:
- 自然图像:包括用于结构化解析的单图数据集和多图差异数据集。后者使用真实世界的图像对,并通过基于 VLM 的过滤来确保美学质量和语义一致性。
- 图形:一个专门的库,包含源自各种公共数据集的图表(折线图、柱状图、饼图、流程图等)。这些图表经过标注,以将绘图区域与文本解耦。
- 几何图形:包括来自 K-12 教科书的单图解读,以及代表原子几何操作(例如添加角平分线)的多图对。
- 文档领域:包含超过 300,000 张高质量的页面级图像。来源包括 olmOCR-mix-0225、FinTabNet、TNCR 和 PubTabNet 等公共数据集,以及大规模内部数据集。
- 音频领域:提供时间对齐的语义块,将带有说话人属性的转录文本与声学事件及场景描述相结合。
- 视频领域:
- 通用视频:包含 511,000 个字幕样本和 266,000 个解析样本,通过涉及语音活动检测和场景边界检测的流水线进行处理。
- 相机感知视频:一个包含 191,000 个样本的数据集,源自 MovieNet 和内部收藏,侧重于相机运动的精确时空定位。
- 文本丰富视频:一个内部收集的教育类 YouTube 视频集,包含 130,000 个结构化字幕和 79,000 个解析条目。
数据处理与元数据构建
- 三层解析框架:数据通过渐进式流水线进行处理:L1-全面检测(时空定位)、L2-细粒度识别(文本、符号和属性提取)以及 L3-多层级解读(语义综合与逻辑推理)。
- 标准化输出:所有数据都转换为统一的 JSON 格式。对于图像,这包括实体对象 (Entity Objects)、文本块 (Text Blocks) 和全局描述 (Global Descriptions)。对于图表,统计数据被转换为 HTML 表格,而流程图则被转录为 Mermaid 代码。
- 知识增强:只有在视觉证据明确的情况下,才会通过严格机制将实体链接到权威标识符(例如地标或物种)。
- 视频合成:使用多阶段流水线融合单模态流,通过计算视觉边界与音频语义块的交集来确保跨模态一致性。
模型训练使用
- 两阶段训练策略:
- 第一阶段:使用 16M 规模的语料库来建立原子能力和基础感知。
- 第二阶段:采用 5M 高精度指令样本进行深度微调和复杂推理。
- 混合构成:训练数据是 Omni Parsing 框架生成的统一结构化解析数据与多样化 Caption 及 QA 数据的混合体,以确保全模态对齐。
方法
Logics-Parsing-Omni 方法论建立在统一多模态感知与认知的三层渐进式范式之上。本文提出了 Omni Parsing 框架,该框架从全面检测 (L1) 过渡到细粒度识别 (L2),最后到语义解读 (L3)。该框架旨在处理包括文档、图像、音频和视频流在内的多种输入。
如框架图所示:

该方法的基础在于构建大规模统一语料库。该语料库整合了异构任务,例如文档的结构化解析、图形的单图及多图差异分析,以及音频和视频的复杂时序理解。为了专门处理音频模态,本文实现了一个时间对齐的解析过程。这包括使用说话人日志 (speaker diarization) 进行带有说话人属性的转录,以创建 "SpeakerID-ASR-Timestamp" 三元组,同时进行声学场景建模以捕捉环境噪声或音乐等非语言线索。这些元素被合成为统一的音频语义块,为跨模态对齐提供高分辨率监督。
训练过程遵循两阶段渐进策略,从 Qwen3-Omni-30B-A3B 模型开始初始化。第一阶段名为“全景认知基础”,模型在包含 1600 万个样本的大规模数据集上进行全参数监督微调 (SFT)。此阶段优先考虑数据规模和覆盖范围,以建立全面检测和细粒度识别的基础技能。它通过约 1260 万个基于图像的 QA 对进行大规模视觉知识注入,并聚合了多样化的原子能力,如文档结构解析和视听字幕生成。
第二阶段“统一解析对齐”侧重于通过平衡的指令微调来精炼模型。为了纠正第一阶段的任务分布偏差,本文使用了 500 万个样本的高质量数据集。此阶段激活了跨所有领域的完整 L1 到 L3 渐进式解析流水线。
参考训练流水线图:
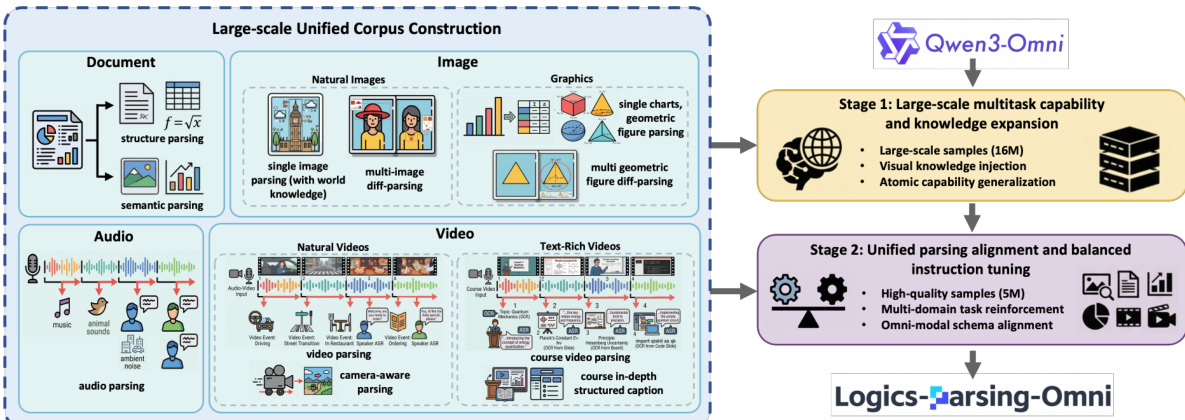
在此对齐阶段,模型接受训练,将异构的全模态输入映射为标准化的 JSON 格式。这确保了双重对齐,即模型既能执行结构化提取,又能进行流畅的自然语言生成。通过强制执行这种统一的模式,模型学会了将时空定位与高层语义推理联系起来,有效地实现了信号级感知与认知解读之间的协同。
实验
评估框架通过两个核心维度评估模型性能:感知(验证信号检测和结构恢复)和认知(衡量语义深度和逻辑推理)。在自然图像、图形、文档、音频和视频上的实验表明,Logics-Parsing-Omni 达到了最先进或极具竞争力的结果,通常超过了 Gemini-3-Pro 等领先的专用模型。研究结论认为,将细粒度结构化解析与语义描述相结合,为在复杂多模态场景中实现稳健且抗幻觉的推理提供了必要基础。
本文在 OmniParsingBench 的自然视频模块上评估了 Logics-Parsing-Omni 模型,并将其与 Gemini-3-Pro 和 Qwen3-Omni-30B-A3B 基准模型进行了对比。结果显示,虽然模型在感知和认知方面表现出竞争力,但在相机运动分析等特定领域取得了显著优势。该模型在感知维度的相机运动分析中获得了领先分数。在认知维度,模型在视觉语义和动态方面表现出强劲性能,特别是在相机字幕准确性方面。模型在视听推理任务(包括情感和因果推理)中保持了极具竞争力的结果。

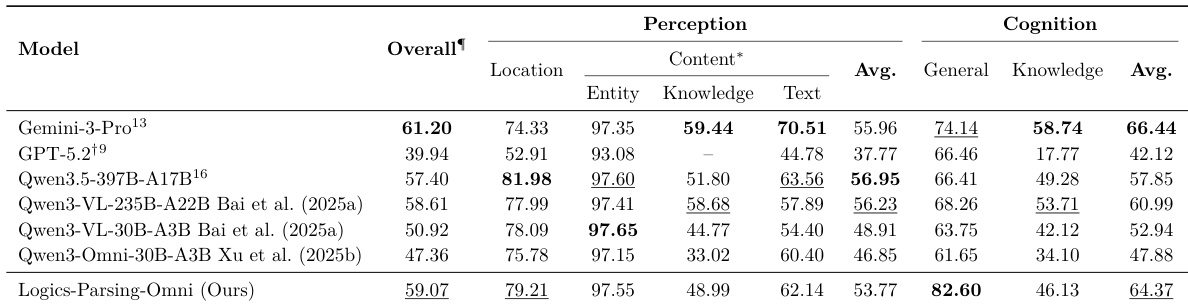
该表对比了各种视觉语言模型在实体、知识感知实体和文本解析任务上的表现。结果显示,虽然不同模型在定位召回率或语义准确性等特定子指标上表现出色,但其整体平均性能差异显著。具有最高整体平均分数的模型在不同解析类别之间表现出强大的平衡性。在文本解析方面,其中一个模型在评估组中实现了最高的定位召回率和语言准确性。对于知识感知实体,表现最好的模型显示出优于其他评估模型的定位召回率。

本文在 OmniParsingBench 的自然图像模块上评估了多个模型,对比了感知和认知能力。结果显示,所提出的模型在通用语义理解方面获得了高分,在该特定维度上超过了开源模型和专用模型。所提出的模型在通用认知方面获得了最高分,超越了专用模型。该模型在空间定位和语义内容提取之间保持了具有竞争力的平衡。虽然模型在通用语义理解方面表现出色,但其在知识感知实体解析方面的表现低于其通用实体和文本识别能力。
本文在 OmniParsingBench 的音频模块上评估了 Logics-Parsing-Omni 模型,并将其与多个基准模型进行了对比。结果显示,受认知任务强劲表现的驱动,所提出的模型获得了最高的总分。Logics-Parsing-Omni 在音频模块上达到了最先进的整体得分。与最强的基准模型相比,该模型在音频识别方面表现出优越性能。模型在音频信息提取方面表现出极高的熟练度,有助于其领先的认知平均分。

本文在 OmniParsingBench 的图形模块上评估了 Logics-Parsing-Omni 模型,重点关注图表和几何图形。结果显示,与几种最先进的模型相比,该模型实现了最高的整体准确率,在感知提取和认知推理方面均表现出优越性能。该模型在图表认知方面取得了领先性能,特别是在 OCR 和数据提取任务中。Logics-Parsing-Omni 在提取结构化图表中的视觉元素方面表现出卓越能力。该模型在图形领域的整体认知准确率超过了开源和专用基准。

Logics-Parsing-Omni 模型在 OmniParsingBench 的自然视频、文本、自然图像、音频和图形模块上进行了评估,以验证其针对各种开源和专用基准的感知和认知能力。该模型在音频识别、图表认知和相机运动分析方面表现出最先进的性能,同时在通用语义理解和视觉推理方面保持了强大的平衡。总体而言,结果表明该模型在多样化多模态领域的复杂认知任务和结构化数据提取方面表现出色。