Command Palette
Search for a command to run...
Flash-KMeans:快速且内存高效的精确 K-Means 算法
Flash-KMeans:快速且内存高效的精确 K-Means 算法
摘要
K-means 算法在历史上主要被定位为一种离线处理原语,通常用于数据集组织或嵌入预处理,而非作为在线系统中的核心组件。本文在现代 AI 系统设计的视角下重新审视这一经典算法,成功将 K-means 转化为一种在线原语。我们指出,现有的 K-means GPU 实现仍主要受限于底层系统约束,而非理论算法复杂度。具体而言,分配阶段因在高带宽内存(HBM)中显式构建大规模的 N×K 距离矩阵而遭受严重的 I/O 瓶颈;同时,质心更新阶段则因不规则的散射式(scatter-style)令牌聚合所引发的高并发硬件级原子写冲突而性能大幅受损。为弥合这一性能差距,我们提出了 Flash-KMeans,这是一种面向现代 GPU 工作负载、具备 I/O 感知且无争用特性的 K-means 实现方案。Flash-KMeans 引入了两项核心内核级创新:(1)FlashAssign,该机制将距离计算与在线 argmin 操作融合,从而完全绕过中间内存的显式构建;(2)排序 - 逆映射更新(sort-inverse update),该机制显式构建逆映射,将高争用的原子散射操作转化为高带宽、分段级的局部归约。此外,我们融合了算法与系统协同设计策略,包括分块流重叠(chunked-stream overlap)和缓存感知的编译启发式方法,以确保方案的实际可部署性。在 NVIDIA H200 GPU 上的广泛评估表明,Flash-KMeans 相比最佳基线实现了高达 17.9 倍的端到端加速,同时其性能分别比工业标准库 cuML 和 FAISS 高出 33 倍和超过 200 倍。
一句话总结
来自加州大学伯克利分校、麻省理工学院和德克萨斯大学奥斯汀分校的研究人员提出了 flash-kmeans,这是一种感知 IO 的 GPU 实现方案。该方案通过 FlashAssign 和排序逆更新(sort-inverse update)技术,消除了距离矩阵的物化以及原子操作竞争,为现代 AI 工作负载中的可扩展在线聚类提供了高达 17.9 倍的加速。
主要贡献
- 现有的 GPU k-means 实现受到严重 IO 瓶颈的阻碍,这些瓶颈源于大规模距离矩阵的物化以及质心更新期间的硬件级原子竞争,导致其无法作为高效的在线原语使用。
- Flash-KMeans 通过两项核心内核创新解决了这些问题:FlashAssign 将距离计算与在线 argmin 融合,绕过中间内存存储;排序逆更新将高竞争的原子分散操作转化为局部规约操作。
- 在 NVIDIA H200 GPU 上的评估显示,与最佳基线相比,端到端加速比高达 17.9 倍,与 FAISS 相比提升超过 200 倍,同时支持在多达十亿个数据点上无缝执行外核(out-of-core)计算。
引言
K-means 聚类正从离线数据处理工具演变为现代 AI 系统的关键在线原语,包括向量量化、大语言模型中的稀疏路由以及生成式视频流水线。尽管发生了这一转变,现有的 GPU 实现仍无法满足延迟要求,因为它们受限于硬件约束而非算法复杂度。先前的方法由于显式物化大规模距离矩阵而导致严重的内存带宽浪费,并因质心更新期间的原子写入竞争而遭受硬件级串行化的影响。为了解决这些问题,作者引入了 Flash-KMeans,这是一种精确且感知 IO 的实现方案,它将距离计算与在线 argmin 融合以绕过中间内存存储,并用排序逆更新策略替代不规则的原子分散操作以实现高效聚合。这种系统级的重新设计消除了关键瓶颈,在基线之上实现了高达 17.9 倍的端到端加速,同时支持在超过十亿个数据点的数据集上进行可扩展执行。
方法
作者提出了 flash-kmeans,这是一种高度优化的实现方案,旨在克服标准基于 GPU 的 k-means 聚类中固有的严重内存和同步瓶颈。该方法侧重于重构执行数据流,以消除 IO 开销并解决写入侧竞争,同时不改变底层的数学目标。
FlashAssign:无物化分配
为了解决因物化大规模距离矩阵 D∈RN×K 而导致的内存墙问题,作者提出了 FlashAssign。该模块将距离计算与行规约融合为单个流式过程。FlashAssign 不再将完整的距离矩阵写入高带宽内存(HBM)再读回,而是直接在寄存器中维护最小距离和对应质心索引的运行状态。
该过程利用在线 argmin 更新。对于每个数据点,内核以分块方式扫描质心。它在片上计算局部距离,识别块内的局部最小值,并将其与运行最小值进行比较以更新全局分配。这种方法确保了 N×K 距离矩阵从未在内存中显式构建。
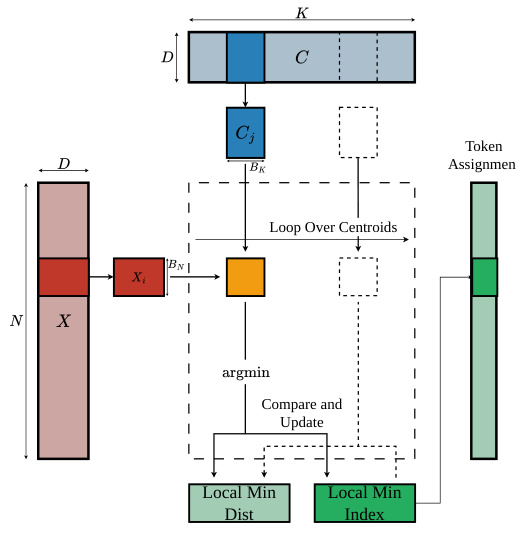
如上图框架所示,算法循环遍历质心块。对于每个点 Xi,它计算与质心块 Cj 的距离,找到局部最小值,并更新全局最小值索引。通过采用二维分块和异步预取,内核隐藏了内存延迟,同时将 IO 复杂度从 O(NK) 降低到 O(Nd+Kd)。
排序逆更新:低竞争聚合
在质心更新阶段,标准实现遭受严重的原子写入竞争,因为多个线程经常尝试使用分散式原子加法同时更新同一个质心。为了解决这一问题,作者提出了排序逆更新策略。
核心思想是将“令牌到簇”的更新转换为“簇到令牌”的收集操作。系统首先对分配向量 a 应用 argsort 操作以获得置换索引。这重新排列了令牌,使得相同的簇 ID 被分组到连续的段中。
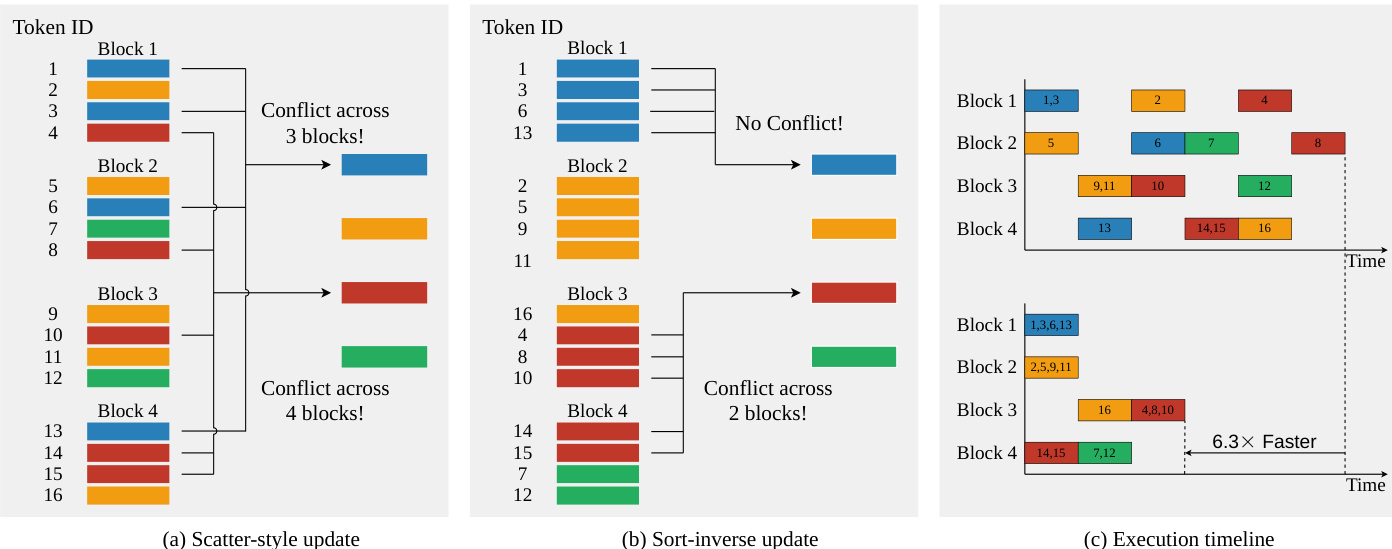
下图对比了标准的分散式更新与提出的排序逆方法。在标准方法(a)中,令牌不规则地分散,导致跨多个块的冲突。在排序逆方法(b)中,令牌按簇 ID 排序,形成连续段。这使得每个协作线程数组(CTA)能够处理排序序列的一个块,从原始矩阵中收集特征,并完全在快速片上内存中累积部分和。全局原子操作仅在段边界处发出。
这种重组将原子操作的数量从 O(Nd) 大幅减少到 O((K+⌈N/BN⌉)d)。如执行时间线(c)所示,这消除了由原子锁竞争引起的频繁停顿,实现了无竞争的内存写入,并显著加速了规约阶段。
算法 - 系统协同设计
为了确保在真实系统中的可部署性,flash-kmeans 包含了几项系统级优化。对于超出 GPU 内存的大规模数据,作者实现了分块流重叠设计。这将数据划分为块,并利用 CUDA 流协调异步主机到设备的传输与计算,遵循双缓冲流模式。此外,还采用了一种感知缓存的编译启发式方法,根据硬件特性和问题形状选择高质量的核配置,最大限度地减少了通常与 exhaustive tuning(穷举调优)相关的“首次运行”开销。
实验
- 效率评估表明,flash-kmeans 在各种工作负载中始终优于优化的基线,在计算密集型场景中实现了高达 17.9 倍的加速,在高度批处理设置中实现了 15.3 倍的加速,同时防止了内存密集型场景下的内存溢出故障。
- 内核级分析证实,自定义的 FlashAssign 和排序逆更新模块有效地消除了距离矩阵物化和原子竞争瓶颈,分别实现了高达 21.2 倍和 6.3 倍的加速。
- 大规模外核实验验证了该系统通过限制峰值内存使用量,成功处理了高达十亿个数据点的数据集,与最稳健的现有基线相比,迭代时间快了 6.3 倍至 10.5 倍。
- 算法 - 系统协同设计测试表明,与穷举调优相比,感知缓存的编译启发式方法将配置搜索时间减少了高达 175 倍,同时在可忽略的性能下降下保持了接近最优的运行时性能。