Command Palette
Search for a command to run...
无监督 RLVR 能在多大程度上扩展 LLM 训练?
无监督 RLVR 能在多大程度上扩展 LLM 训练?
摘要
无监督强化学习结合可验证奖励(Unsupervised Reinforcement Learning with Verifiable Rewards, URLVR)为突破大语言模型(LLM)训练中的监督瓶颈提供了一条可行路径,其核心在于无需依赖真实标签即可推导奖励信号。近期研究利用模型内在信号取得了初步成效,但其潜力与局限性尚不明确。本文对 URLVR 进行重新审视,并从分类体系、理论分析及大规模实验三个维度展开系统性研究。首先,我们依据奖励来源将 URLVR 方法划分为内在奖励与外在奖励两类;进而构建统一理论框架,揭示所有内在奖励方法均趋向于使模型初始分布趋于锐化。该锐化机制在模型初始置信度与正确性一致时能够有效发挥作用,而在二者失配时则会导致灾难性崩溃。通过系统性实验,我们发现内在奖励在不同方法中均呈现“先升后降”的演化规律,其崩溃时点由模型先验决定,而非工程调参选择。尽管存在上述扩展性限制,我们仍发现内在奖励在小规模数据集的测试时训练(test-time training)中具有重要价值,并进一步提出“模型崩溃步数”(Model Collapse Step)这一指标用于量化模型先验,可作为强化学习可训练性的实用判据。最后,我们探索了基于计算不对称性(computational asymmetries)进行验证的外在奖励方法,初步证据表明其有望突破“置信度 - 正确性”上限。本研究不仅界定了内在 URLVR 的适用边界,也为探索可扩展的替代方案指明了方向。
一句话总结
清华大学及合作机构的研究人员揭示,内在无监督 RLVR 方法不可避免地会通过锐化初始分布导致模型崩溃,他们提出了“模型崩溃步数”(Model Collapse Step)指标以预测可训练性,并主张利用外部奖励来实现可扩展的大语言模型训练。
主要贡献
- 本文建立了无监督 RLVR 的分类体系,并提供了一个统一的理论框架,表明所有内在奖励方法都会收敛于锐化模型的初始分布,而非发现新知识。
- 大量实验表明,内在 URLVR 始终遵循“先升后降”的模式:当模型的初始置信度与正确性不一致时,无论具体的工程选择如何,性能都会崩溃。
- 作者提出了“模型崩溃步数”指标来预测 RL 的可训练性,并证明内在奖励在小数据集的测试时训练中仍然有效,而基于计算不对称性的外部奖励则为突破这些扩展限制提供了一条潜在路径。
引言
目前,大语言模型依赖可验证奖励的强化学习来增强推理能力,但随着获取人工验证的基准真值标签变得极其昂贵且对超级智能系统不可行,这种方法面临关键瓶颈。无监督 RLVR 旨在通过无需标签即可推导奖励来解决这一问题,然而,以往依赖内在模型信号的工作存在根本性的“先升后降”模式:训练初期性能提升,随后因奖励黑客攻击和模型退化而崩溃。作者提供了全面的理论与实证分析,揭示内在方法仅仅是锐化了模型的初始分布,当置信度与正确性不一致时便会失效;同时,他们提出了“模型崩溃步数”作为预测可训练性的实用指标,并主张利用计算不对称性的外部奖励方法,以实现可扩展且稳定的改进。
数据集
- 训练数据集由 M 个提示 - 答案对组成,其中每个条目包含一个提示 xi 及其对应的基准真值答案 ai∗。
- 对于集合中的每个提示,作者使用当前策略 πθ 生成 N 个 rollout 响应。
- 每个生成的响应包含完整的推理轨迹以及从该轨迹中提取的答案。
- 这些数据构成了训练的基础,模型从中学习初始提示、生成的轨迹与已验证的基准真值答案之间的关系。
方法
作者利用了一个无监督可验证奖励强化学习(URLVR)框架,该框架通过仅由模型生成的代理内在奖励,消除了对基准真值标签的需求。该方法区分了构建奖励的两种主要范式:基于确定性(Certainty-Based)和基于集成(Ensemble-Based)的方法。
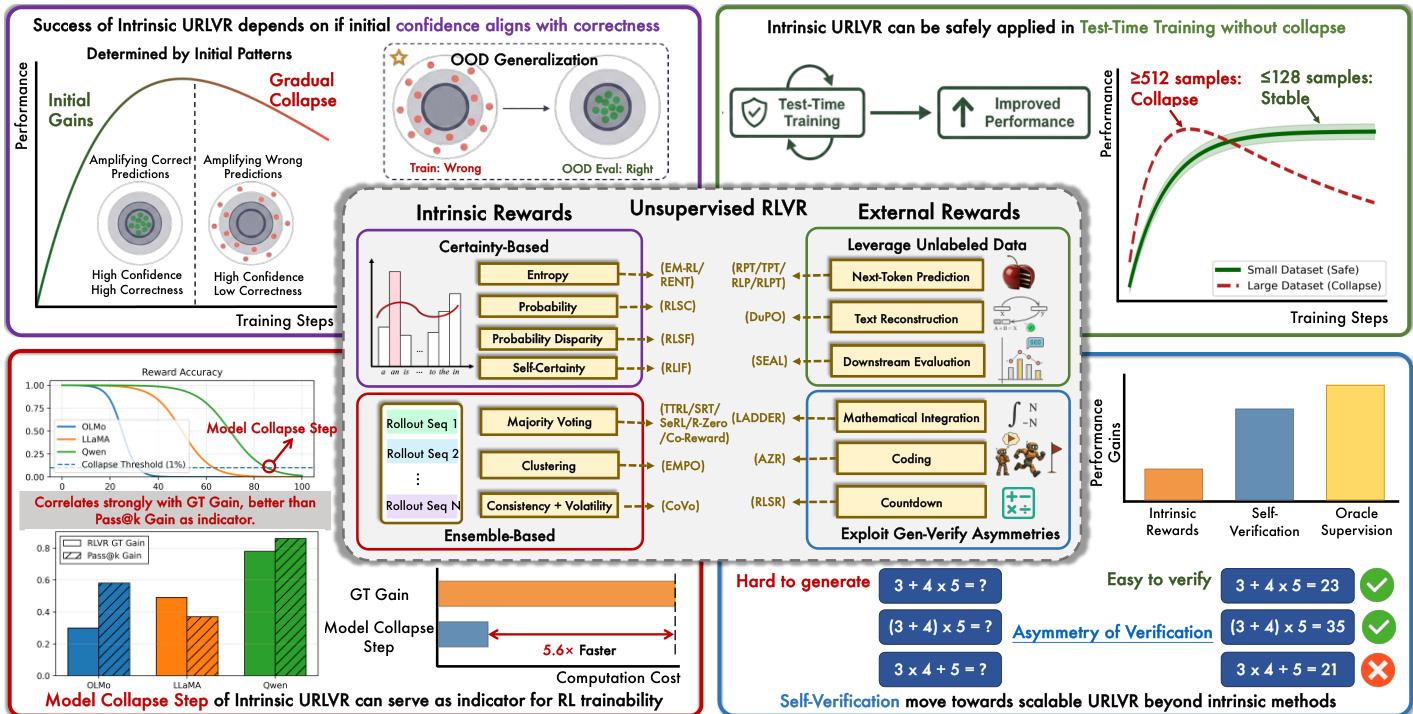
基于确定性的奖励从策略的置信度(如 logits 或熵)中推导信号,其假设是较高的置信度与正确性相关。这些方法包括 Self-Certainty 等估计器,它测量与均匀分布的 KL 散度;以及 Token-Level Entropy,它对每个生成步骤的不确定性进行惩罚。相反,基于集成的奖励利用“群体智慧”,为同一提示生成多个 rollout。它们假设这些多样化候选解之间的一致性(通常通过多数投票或语义聚类形式化)是正确性的稳健代理。
驱动这些方法的底层机制是一个锐化过程,模型在此过程中收敛于其初始分布。理论上,训练动态遵循 KL 正则化的 RL 目标。该目标的最优策略具有闭式解:
πθ∗(y∣x)=Z(x)1πref(y∣x)exp(β1r(x,y))其中 Z(x) 是配分函数,β 控制正则化强度。对于多数投票等内在奖励,这会形成“富者愈富”的动态。如果模型的初始置信度与正确性一致,锐化机制会放大这些正确预测,从而带来性能提升。然而,如果初始置信度不一致,同一机制会系统地强化错误,导致性能逐渐崩溃。
为了监控这种稳定性,作者引入了“模型崩溃步数”作为可训练性的指标。该指标追踪奖励准确率降至特定阈值(如 1%)时的训练步数。具有更强先验的模型能在崩溃前维持更长时间的内在 URLVR,从而允许在不进行完整强化学习训练的计算成本下高效地选择基座模型。该框架突显了内在 URLVR 成功的关键在于初始置信度与正确性之间的对齐。
实验
- 内在 URLVR 方法普遍表现出“先升后降”的模式:早期因置信度与正确性对齐带来的收益最终会因奖励黑客攻击而崩溃,无论超参数调整或具体奖励设计如何。
- 细粒度分析表明,训练主要放大了模型的初始偏好,而非纠正特定问题上的错误;然而,如果初始置信度与正确性一致,这种锐化仍可泛化以提高未见过的分布外任务的性能。
- 在小规模、特定领域的数据集上训练或在测试时训练时,模型崩溃得以避免,因为这些条件诱导的是局部过拟合,而非导致大规模训练失败的系统性策略偏移。
- “模型崩溃步数”(衡量内在训练期间奖励准确率下降的时机)是预测模型 RL 增益潜力的快速且准确的指标,其表现优于 pass@k 等静态指标。
- 利用生成 - 验证不对称性的外部奖励方法(如自我验证)比内在奖励提供了更具可扩展性的路径,因为它们提供的信号基于计算过程,而非模型的内部置信度。