Command Palette
Search for a command to run...
大型语言模型中工具使用的上下文强化学习
大型语言模型中工具使用的上下文强化学习
Yaoqi Ye Yiran Zhao Keyu Duan Zeyu Zheng Kenji Kawaguchi Cihang Xie Michael Qizhe Shieh
摘要
尽管大语言模型(LLMs)展现出强大的推理能力,但其在处理复杂任务时的性能往往受限于模型内部知识的不足。一种极具前景的解决方案是为这些模型引入外部工具,例如用于数学计算的 Python 解释器或用于检索事实信息的搜索引擎。然而,如何使模型有效利用这些工具仍是一项重大挑战。现有方法通常依赖“冷启动”流程,即先进行监督微调(SFT),再实施强化学习(RL)。这类方法往往需要大量标注数据用于 SFT 阶段,而数据的标注或合成成本高昂。本文提出了一种名为“上下文强化学习”(In-Context Reinforcement Learning, ICRL)的新型框架。该框架仅采用强化学习,通过在强化学习的 rollout( rollout 阶段)中利用少样本提示(few-shot prompting),完全摒弃了对监督微调的依赖。具体而言,ICRL 在 rollout 提示中嵌入上下文示例,以引导模型学习如何调用外部工具。随着训练过程的推进,上下文示例的数量逐步减少,最终过渡到零样本(zero-shot)设置,使模型能够独立调用工具。我们在多个推理与工具使用基准测试上进行了广泛实验。结果表明,ICRL 取得了最先进(state-of-the-art)的性能,证明了其作为一种可扩展、数据高效的替代方案,相较于传统基于 SFT 的流程具有显著优势。
一句话总结
来自耶鲁大学、斯坦福大学及其他机构的研究人员提出了“上下文强化学习”(In-Context Reinforcement Learning),这是一个新颖的框架,使大型语言模型能够通过动态上下文更新自主优化工具使用策略,显著提升了在复杂多步推理任务中的适应性和性能,且无需进行大量的微调。
主要贡献
- 大型语言模型常因内部知识有限而难以应对复杂任务,现有的工具使用训练方法依赖昂贵的监督微调来提供初始指导。
- 本工作引入了“上下文强化学习”,这是一个仅基于强化学习(RL)的框架,通过在 rollout 过程中使用少样本提示(few-shot prompting)来教授工具调用,无需任何监督微调。
- 在 TriviaQA 和 AIME2024 等基准测试上的实验表明,该方法在消除对昂贵标注数据需求的同时,实现了最先进的性能,并在强基线模型上取得了显著的准确率提升。
引言
大型语言模型往往因依赖静态预训练知识而难以应对复杂任务,这使得集成代码解释器和搜索引擎等外部工具对于现实世界应用至关重要。当前方法通常依赖一个结合监督微调与强化学习的冷启动流程,该过程需要昂贵且耗时的标注数据来教导模型如何有效调用工具。作者提出了“上下文强化学习”,这是一个仅基于强化学习的框架,通过将少样本演示直接嵌入到 rollout 提示中,消除了对监督微调的需求。该方法采用一种课程学习策略,逐步减少这些示例,引导模型从模仿学习过渡到自主工具使用,在显著提升数据效率的同时实现了最先进的性能。
方法
作者将大型语言模型(LLM)中的工具使用形式化为马尔可夫决策过程(MDP)。给定查询 q 和外部工具 T,模型生成响应 y,其中每个 token 的条件依赖于查询、之前的 token 以及交互历史 Ht。该交互历史包括模型的动作(如内部推理、发出搜索查询或提供最终答案)以及工具返回的观测结果。条件分布定义如下:
πθ(y∣q,T)=t=1∏∣y∣πθ(yt∣y<t,q,Ht)为了优化该策略,作者采用了一个强化学习目标,旨在最大化预期奖励,同时约束与参考模型 πref 的散度。他们具体采用了组相对策略优化(GRPO)来训练策略 πθ。该训练的一个关键组件是损失掩码策略。由于 rollout 序列包含了模型未生成的、从外部工具检索到的内容,这些 token 被排除在损失计算之外。这确保了策略梯度更新仅专注于模型自身的决策(如工具调用和推理步骤),而不是工具检索到的固定内容。
所提出方法“上下文强化学习”(ICRL)的核心创新在于其训练课程。ICRL 并非从头开始训练或仅依赖静态少样本提示,而是将少样本学习的归纳偏置与强化学习的探索能力相结合。该过程开始时,在 rollout 模板中引入少量工具使用演示以引导模型。随着训练的进行以及模型获得工具使用能力,提示中的演示示例数量会被迭代减少。这种过渡使模型能够从模仿学习转向自主工具使用。
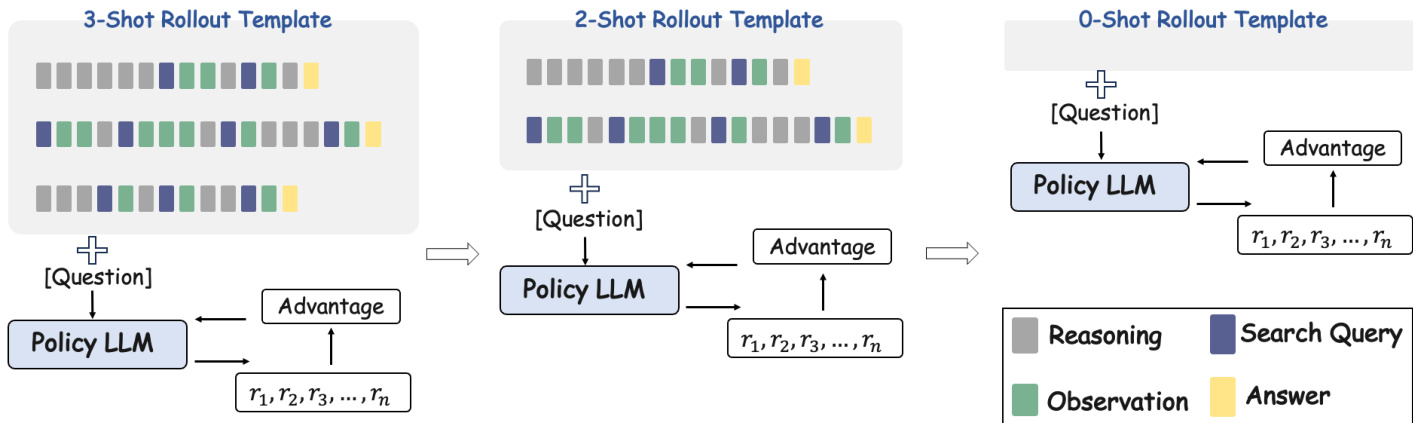
为了在此过程中提供稳健的学习信号,作者设计了一个组合奖励函数,结合了答案准确性和格式正确性。准确性奖励基于与真实标签的精确匹配,而格式奖励则对违反预期结构化输出(如错误的 XML 标签)的行为进行惩罚。总奖励是这两个分量的加权和,引导模型生成既正确又有效的工具使用序列。
实验
- 主要实验将 ICRL 与直接提示、基于检索的方法以及微调基线在多样化的问答基准测试中进行了对比,验证了 ICRL 在无需监督微调或标注工具轨迹的情况下,在复杂推理和多跳任务中实现了最先进的性能。
- 关于课程设计的消融研究表明,与导致过早停止并削弱多轮推理能力的激进减少策略相比,更简单的三阶段 rollout 调度能产生更高的准确率。
- 扩展实验证实,ICRL 能有效利用更大的模型容量,其中 14B 变体在保持数据效率的同时,显著优于提示方法和思维链(Chain-of-Thought)方法。
- 在代码编写和数学解题任务上的泛化测试显示,ICRL 成功迁移到了新的工具领域,为依赖昂贵冷启动监督微调的方法提供了一种数据效率更高的替代方案。
- 训练过程分析表明,即使仅针对格式有效性和最终答案准确性的稀疏奖励进行训练,模型也能学会内化结构化的工具使用行为,并随时间推移增加有效工具调用的次数。