Command Palette
Search for a command to run...
Holi-Spatial:将视频流演进为整体三维空间智能
Holi-Spatial:将视频流演进为整体三维空间智能
摘要
对空间智能的探索从根本上依赖于大规模、细粒度的三维数据。然而,现有方法主要通过在少量人工标注数据集上生成问答(QA)对来构建空间理解基准,而非从原始网络数据中系统性地标注新的大规模三维场景。因此,其可扩展性受到严重制约,且模型性能也因这些精心筛选数据集中固有的领域差距而进一步受限。在本研究中,我们提出了 Holi-Spatial,这是首个完全自动化、大规模且具备空间感知能力的多模态数据集。该数据集利用我们提出的数据策展流程,直接从原始视频输入构建,全程无需人工干预。Holi-Spatial 支持多层次的空间监督,涵盖几何精确的三维高斯泼溅(3D Gaussian Splatting, 3DGS)重建及其渲染深度图、物体级与关系级语义标注,以及相应的空间问答(QA)对。遵循一套原则性强且系统化的流程,我们进一步构建了 Holi-Spatial-4M,这是首个大规模、高质量的三维语义数据集。该数据集包含 12,000 个经过优化的 3DGS 场景、130 万个二维掩码、32 万个三维边界框、32 万个实例描述、120 万个三维定位实例,以及 120 万个涵盖几何、关系和语义推理任务的三维空间问答对。实验结果表明,Holi-Spatial 在数据策展质量方面表现卓越,在 ScanNet、ScanNet++ 和 DL3DV 等数据集上显著优于现有的前馈式及逐场景优化方法。此外,利用该数据集对视觉 - 语言模型(VLMs)进行空间推理任务的微调,也带来了模型性能的显著提升。
一句话总结
上海人工智能实验室与多所高校的研究人员推出了 Holi-Spatial,这是一个全自动流水线,利用 3D 高斯泼溅(3D Gaussian Splatting)和视觉语言模型(VLMs),将原始视频转换为高保真 3D 场景。该方法克服了人工标注的限制,构建了 Holi-Spatial-4M 数据集,显著提升了视觉语言模型的空间推理与定位能力。
主要贡献
- Holi-Spatial 通过引入一个全自动框架,解决了原始空间数据稀缺和不平衡的问题。该框架无需显式 3D 传感器或人工介入,即可将原始视频流转换为高保真 3D 几何结构和整体语义标注。
- 该方法采用三阶段流水线:结合 3D 高斯泼溅进行几何优化,利用开放词汇 VLM 和 SAM3 进行图像级感知,并通过场景级细化来合并实例,生成详细的描述和定位对。
- 在 ScanNet++ 和 DL3DV-10K 等基准测试上的评估表明,生成的 Holi-Spatial-4M 数据集将多视图深度估计的 F1 分数提高了高达 0.5,3D 检测 AP50 提升了 64%;同时,对 Qwen3-VL 进行微调后,3D 定位准确率提升了 15%。
引言
空间智能对于使大型多模态模型能够感知和推理真实 3D 世界至关重要,这对机器人操作、导航和增强现实等应用尤为关键。当前的方法由于依赖稀缺的人工标注 3D 数据集或专用扫描硬件,在可扩展性方面面临困难,导致语义覆盖有限且标注成本高昂。为了克服这些障碍,作者推出了 Holi-Spatial,这是一个全自动框架,无需人工标注或显式 3D 传感器,即可将原始视频流转换为具有整体语义标注的高保真 3D 几何结构。该系统统一了几何优化、图像级感知和场景级细化,生成了一个庞大且多样化的数据集,显著提升了下游 3D 定位和空间推理任务的性能。
数据集
-
数据集构成与来源:作者推出了 Holi-Spatial-4M,这是一个完全自动化的大规模数据集,源自 ScanNet、ScanNet++ 和 DL3DV-10K 的原始视频流。该集合是首个在无人类干预下构建的大规模 3D 语义数据集,包含超过 12,000 个经过优化的 3D 高斯泼溅(3DGS)场景。
-
各子集的关键细节:该数据集包含超过 400 万个高质量空间标注,包括 130 万个 2D 实例掩码、32 万个 3D 边界框、32 万个详细的实例描述以及 120 万个 3D 定位实例。它通过利用视觉语言模型标注大量细粒度的室内物品,而非依赖封闭的类别集合,从而支持开放词汇的多样性。
-
在模型训练中的应用:作者利用该数据微调视觉语言模型,以增强其空间推理能力。生成的 125 万个空间问答对被构建为全面的分类体系,涵盖以相机为中心的任务(如旋转和移动方向)以及以物体为中心的任务(包括物体间距离和尺寸测量)。
-
处理与构建细节:该流水线通过几何优化和场景级细化阶段,将原始视频输入转换为整体 3D 空间标注。这一自动化过程生成了多级监督,从具有渲染深度图的几何精确 3DGS 重建,到物体级和关系语义标注,确保了任务分布的平衡,以实现对整体 3D 空间的理解。
方法
作者提出了 Holi-Spatial,这是一个全自动流水线,旨在将原始视频输入转换为高保真 3D 几何结构和全面的空间标注。如框架概览所示,该系统支持从 3D 物体检测和重建到空间推理及 3D 定位的多模态任务,最终生成超过 400 万个标签。

该构建框架包含三个核心阶段。第一阶段是几何优化,将原始视频流提炼为鲁棒的 3D 结构。作者首先利用运动恢复结构(Structure-from-Motion)解析相机内参和外参,随后利用空间基础模型初始化密集点云。为了解决前馈深度估计中固有的噪声和异常值,该方法引入 3D 高斯泼溅(3DGS)进行逐场景优化。此过程整合了几何正则化以强制多视图深度一致性,有效消除了原本会干扰 3D 边界框生成的大规模漂浮物。
第二阶段是图像级感知,提取空间一致的物体标签。从视频流中均匀采样关键帧,视觉语言模型(VLM)在生成描述的同时维护动态类别标签记忆,以确保语义一致性。在这些提示的引导下,SAM3 执行开放词汇实例分割,生成二值掩码和置信度分数。
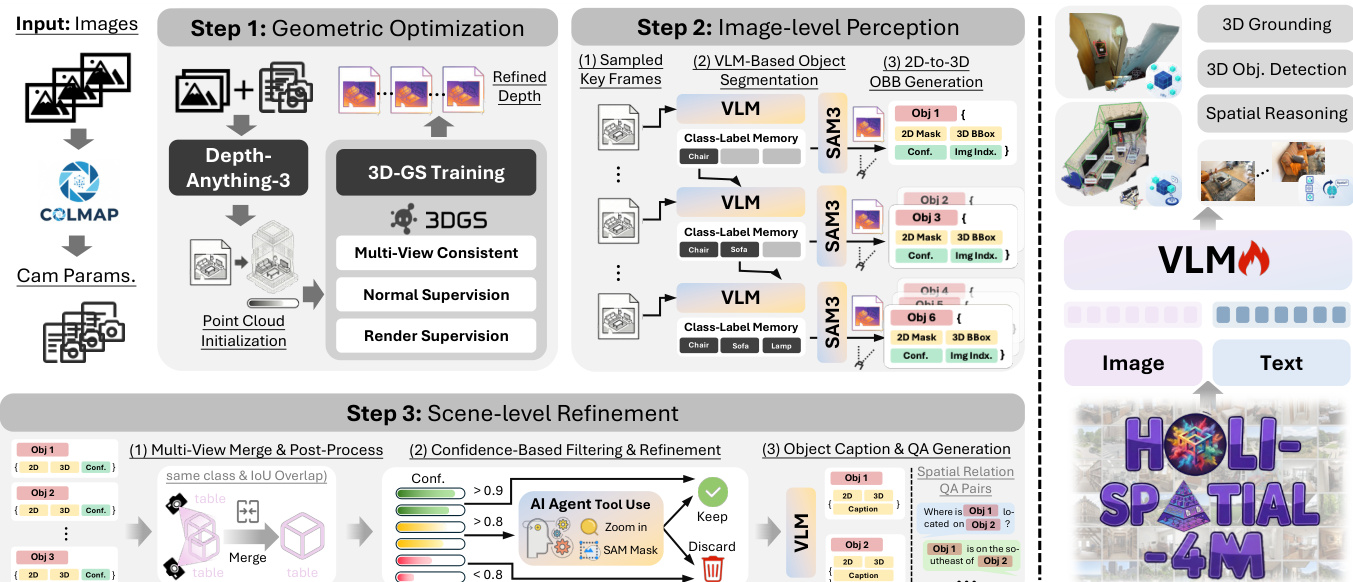
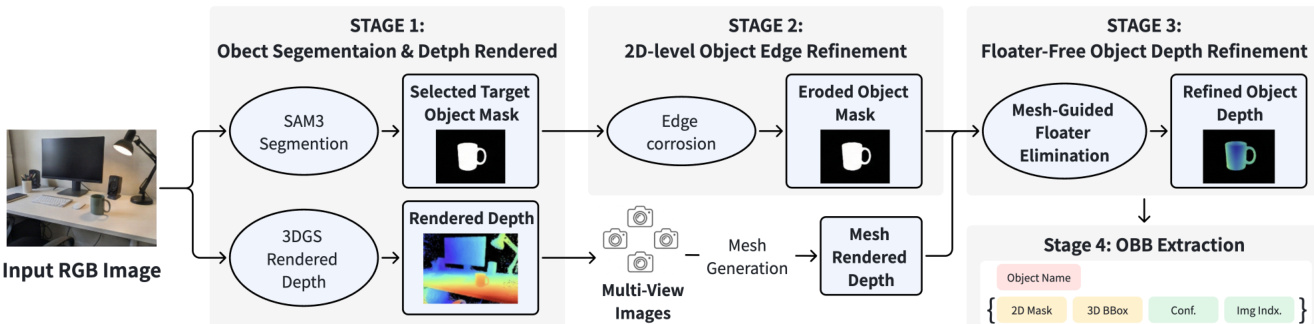
为了将这些 2D 掩码提升至 3D,作者利用从优化后的 3DGS 渲染的细化深度图对像素进行反投影。3D 点 P 计算如下: P=Dt(u)⋅K−1u~ 其中 K 是相机内参矩阵,u~ 表示齐次坐标。为了减轻深度漂浮物和边界误差,应用了几何感知过滤策略。这包括在轮廓附近腐蚀物体掩码以去除 2D 边界误差,并利用多视图一致的网格深度过滤 3D 异常值,确保估计的初始 3D 定向边界框(OBBs)源自可靠的几何子集。
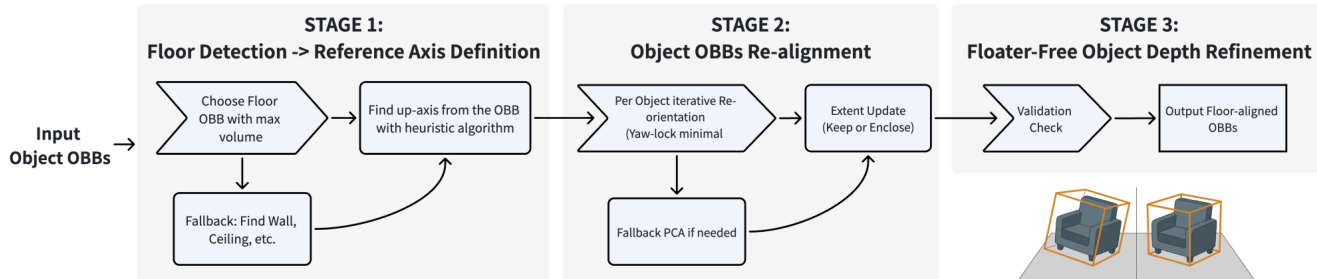
最后阶段是场景级细化。这种由粗到细的策略合并冗余检测并验证实例。首先,空间聚类合并具有相同类别且具有足够 3D 重叠的实例,其定义条件为: ci=cj∧IoU3D(Bi,Bj)>τmerge 其中 τmerge 设定为 0.2。合并之后,后处理模块将 3D OBB 对齐到全局重力轴。这涉及检测地板或作为备选的平面结构以推断全局上轴,并重新定向每个实例的垂直轴。
随后应用基于置信度的过滤,采用三级决策规则。高置信度(sk≥0.9)的提议被保留,而低置信度噪声(sk<0.8)被丢弃。模糊情况则由配备放大和重新分割工具的基于 VLM 的智能体进行验证。

在建立最终验证实例集后,系统生成密集语义标注。它为每个实例检索最佳源图像,并利用大型 VLM 生成细粒度描述,并程序化合成空间问答对。
实验
- 框架评估表明,所提出的方法在 3D 物体检测、2D 分割和深度估计方面同时实现了高质量性能,优于单模态基线。
- 定性结果显示,与 prior 工作相比,该框架生成的 3D 几何结构更清晰,鬼影和漂浮物显著减少,同时生成了更锐利的分割边界和更准确的 3D 边界框。
- 在构建的数据集上微调 VLM 显著提升了空间推理和 3D 定位能力,有效消除了视角偏差,并实现了在不同视图和深度下的可靠物体定位。
- 消融实验证实,利用细化深度进行几何训练对于防止因遮挡或深度伪影导致的实例碎片化和错误合并至关重要。
- 置信度过滤与基于智能体的验证相结合,成功平衡了精确率和召回率,在去除假阳性的同时恢复了原本可能被丢弃的困难实例。
- 多视图合并被验证为纠正图像级实例碎片化并确保空间一致性的关键,从而在多样化的室内场景中实现鲁棒的检测。