Command Palette
Search for a command to run...
大型语言模型能否跟上节奏?面向持续知识流的在线适应性基准测试
大型语言模型能否跟上节奏?面向持续知识流的在线适应性基准测试
Jiyeon Kim Hyunji Lee Dylan Zhou Sue Hyun Park Seunghyun Yoon Trung Bui Franck Dernoncourt Sungmin Cha Minjoon Seo
摘要
在动态的现实世界场景中运行的大型语言模型(LLMs)常面临知识持续演变或增量涌现的挑战。为保持准确性与有效性,模型必须能够实时适应新 arriving 的信息。为此,我们提出了“面向持续知识流的在线适应”(Online Adaptation to Continual Knowledge Streams, OAKS)基准,用于评估模型在持续更新的知识流中进行在线适应的能力。该基准被构建为一系列细粒度的上下文片段序列,其中事实信息在不同时间区间内动态变化。OAKS 包含两个数据集:OAKS-BABI 与 OAKS-Novel,其中单个事实在多个上下文片段中经历多次演变。这两个数据集均提供密集标注,以衡量模型是否能够准确追踪知识变化。我们对 14 种采用不同推理策略的模型进行了评估,发现现有方法存在显著局限。无论是当前最先进的模型,还是基于智能体(agentic)的内存系统,在 OAKS 上均未能实现稳健的在线适应,表现出状态追踪延迟以及在流式环境中易受干扰的问题。
一句话总结
来自 KAIST、北卡罗来纳大学教堂山分校、Google、KRAFTON、Adobe 和纽约大学的研究人员推出了 OAKS,这是一个用于评估在线适应持续知识流的基准测试。该研究揭示,当前最先进的模型和代理记忆系统在动态环境中难以进行实时状态跟踪,且极易受到干扰。
主要贡献
- 现有基准测试无法隔离模型随时间跟踪相同事实持续更新的能力,因此需要对在线环境中的动态知识转换进行细粒度评估。
- 作者推出了 OAKS,这是首个文本领域基准测试,利用两个新数据集(OAKS-BABI 和 OAKS-Novel)在单个事实的粒度上评估流式知识更新,这两个数据集均包含用于跟踪事实演变的密集标注。
- 对 14 个模型的评估显示,无论是系统最先进的系统还是代理记忆方法,在稳健适应方面均表现不佳,在流式环境中表现出显著的状态跟踪延迟和高度的抗干扰脆弱性。
引言
现实世界的知识是动态的,要求语言模型随着事实随时间演变而不断更新其理解。现有基准测试往往无法捕捉这一现实,因为它们依赖于有限的更新或不同的事实,而非跟踪对同一底层信息的重复变化。此外,以往的状态跟踪工作通常侧重于短期的结构化对话槽位,而非长期的、开放式的知识流。作者通过推出 OAKS 解决了这些差距,这是首个旨在评估在单个事实粒度上对持续知识流进行在线适应的基准测试。该框架将长上下文分割为时间块,以评估模型在不更新模型参数的情况下保持时间一致性和跟踪状态变化的能力。
数据集
-
数据集构成与来源 作者推出了 OAKS,这是一个包含两个不同数据集的基准测试,旨在评估对流式知识的在线适应:OAKS-BABI(简称 OAKS-B)和 OAKS-Novel(简称 OAKS-N)。OAKS-B 是源自 BABILong 基准的合成数据集,而 OAKS-N 则是从 39 本冒险、悬疑和科幻题材的完整文学小说中人工策划的数据集。
-
各子集的关键细节
- OAKS-BABI: 该子集包含 1,200 个问题,分为四种类型:跟踪、计数、桥接和比较。它使用 128k 个 token 的上下文长度,分为 65 个块,每个问题平均有 4.7 次答案变更。数据侧重于实体和位置的动态状态跟踪。
- OAKS-Novel: 该子集包含 870 道选择题,每个问题平均有 5.5 个选项。上下文平均每本书跨度为 150.6k 个 token(77.6 个块),每个问题平均有 4.7 次答案变更。问题需要综合多个叙事块中的信息,以跟踪不断变化的角色状态或情节要点。
- 分层: 两个数据集均根据每个问题的答案变更频率划分为三个子集:稀疏(2–3 次变更)、中等(4–5 次变更)和频繁(OAKS-B 为 6–20 次变更;OAKS-N 为 5–19 次变更)。
-
数据使用与评估策略 作者利用数据模拟流式环境,其中每个时间间隔会揭示一个新的上下文块(2k 个 token)。模型在每个间隔使用截至该点的累积上下文对同一组问题进行评估。性能通过间隔级准确率进行衡量,将模型预测与反映该特定时刻知识状态的真实答案进行比较。评估涵盖了 14 个模型,使用了各种推理策略,包括 RAG 和代理记忆系统。
-
处理与元数据构建
- 分块: 文本使用 GPT-NeoX 分词器分割为 2k 个 token 的块。对于 OAKS-N,在块内保留句子边界以维持叙事连贯性。
- 标注: OAKS-B 问题通过解析事实并将动词标准化以创建状态转换而算法生成。OAKS-N 问题最初由 Gemini 2.5 Pro 起草,随后由人类专家严格策划。
- 质量控制: 对于 OAKS-N,人类标注者将初始问题池筛选至 55%,移除了那些不需要多跳推理或答案模糊的问题。标注者为每个块中的每个状态转换标记正确答案,并提供精确的句子级证据。
- 安全与隐私: 在 OAKS-B 中,所有角色和地点名称均经过随机化处理,以防止与现实世界的关联。OAKS-N 依赖于公开可用的小说,且所有数据均为英文。
- 答案选项: OAKS-N 在相关信息出现之前的间隔中包含“此时我们无法回答此问题”的选项,确保一旦信息被揭示,每个块都恰好存在一个有效答案。
方法
作者利用了一个检索增强框架,专为长篇幅叙事中的动态实体跟踪而设计。该系统按顺序处理文本,从之前的时间间隔检索相关的记忆块,同时严格禁止访问未来信息。该检索机制结合了代理记忆系统,如 HippoRAG-v2 或 A-Mem,这些系统将记忆组织为互联的知识网络。在某些配置中,像 MemAgent 这样的代理使用 GRPO 进行训练,以处理具有线性计算复杂度的长上下文。
操作流程如时间线图所示。该过程在间隔 Ti 中展开,系统跟踪真实值 at 以及针对传入块 ct 的相应准确率。如下图所示:
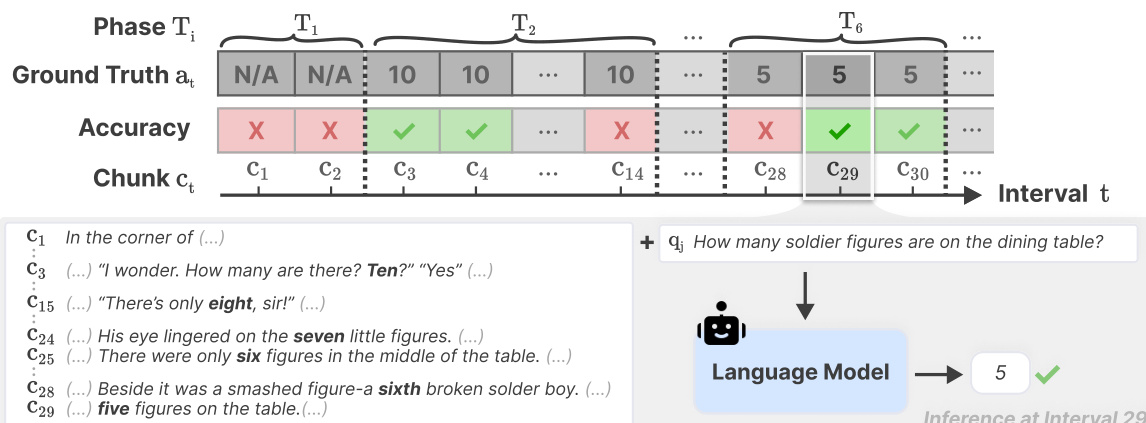 在特定的推理点(例如间隔 29),语言模型接收查询 qi(例如“餐桌上有多少个士兵雕像?”)以及相关的文本上下文。模型生成一个简洁的答案,并得到当前或先前块中证据的支持,然后将其与真实值进行比较以确定正确性。
在特定的推理点(例如间隔 29),语言模型接收查询 qi(例如“餐桌上有多少个士兵雕像?”)以及相关的文本上下文。模型生成一个简洁的答案,并得到当前或先前块中证据的支持,然后将其与真实值进行比较以确定正确性。
为了评估模型推理的时间动态,作者将性能分类为不同的行为模式。如行为分析网格所示:
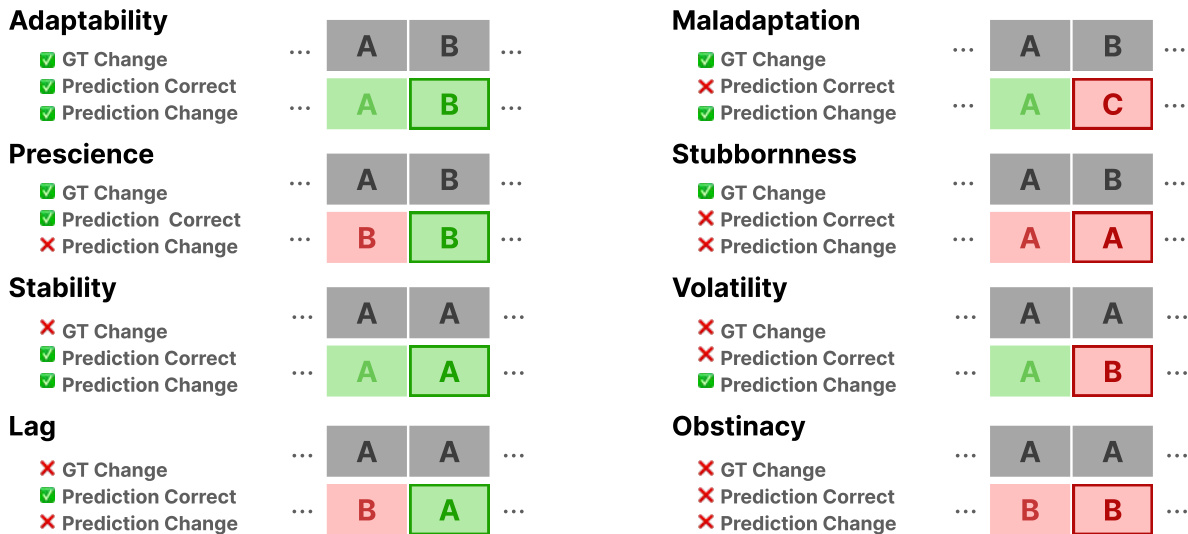 这些模式包括适应性(Adaptability),即模型在真实值发生变化后成功更新其预测;以及稳定性(Stability),即模型在真实值未变时正确保持预测。相反,诸如滞后(Lag)、波动(Volatility)和固执(Stubbornness)等类别则识别出特定的失败模式,即模型要么延迟更新,要么错误地波动,要么尽管有新证据仍坚持过时信息。
这些模式包括适应性(Adaptability),即模型在真实值发生变化后成功更新其预测;以及稳定性(Stability),即模型在真实值未变时正确保持预测。相反,诸如滞后(Lag)、波动(Volatility)和固执(Stubbornness)等类别则识别出特定的失败模式,即模型要么延迟更新,要么错误地波动,要么尽管有新证据仍坚持过时信息。
实验
- 在 OAKS 基准测试上对 14 个大语言模型的评估证实,对持续演变知识的在线适应仍然是一个重大挑战,即使是顶级的专有模型也只能达到有限的准确率。
- 比较模型规模的实验证实,性能通常随着基础模型的增大而提高,且更强大的基础架构始终比较弱的架构产生更好的结果。
- 对知识转换频率的分析显示,涉及频繁答案变更的任务要困难得多,因为模型难以在及时更新与保留先前有效信息之间取得平衡。
- 对朴素检索增强生成(RAG)的测试表明,简单的检索策略不足以应对动态上下文,由于检索歧义以及模型无法处理复杂、重叠的上下文,往往无法提高性能。
- 研究表明,通过显式思维模式进行的推理时扩展显著增强了需要多跳整合的复杂推理任务的性能,尽管对于简单的跟踪问题,其带来的增益微乎其微。
- 对先进代理记忆系统的评估表明,虽然它们可以在特定子集上匹配或略优于朴素 RAG,但整体表现仍然不佳,突显了细粒度、持续知识更新的难度。
- 行为分析揭示了一个持久的权衡:模型经常检测到真正的知识转换,但也表现出高比例的不必要更新,导致随着上下文长度的增加而出现不稳定和干扰。
- 跨问题类型的比较研究表明,桥接问题由于多状态跟踪要求而受干扰影响最大,而跟踪问题由于频繁的状态变化而面临高失败率。
- 纵向分析证实,准确率随时间间隔下降,特别是在证据仅出现一次的数据集中,表明误差累积是一个关键的失败模式,仅靠标准的长上下文能力无法解决。