Command Palette
Search for a command to run...
迷失于叙事之中:LLMs 长故事生成中的一致性缺陷
迷失于叙事之中:LLMs 长故事生成中的一致性缺陷
Junjie Li Xinrui Guo Yuhao Wu Roy Ka-Wei Lee Hongzhi Li Yutao Xie
摘要
当讲述者遗忘其自身的故事时会发生什么?大型语言模型(LLMs)现已能够生成长达数万字的叙事文本,但其在维持整体一致性方面往往表现不佳。在生成长篇叙事时,这些模型常会与其已确立的事实、人物特征及世界观规则产生矛盾。现有的故事生成基准测试主要关注情节质量与语言流畅度,而对一致性错误的系统性探索仍显不足。为填补这一空白,我们提出了 ConStory-Bench,一个专为评估长文故事生成中叙事一致性而设计的基准测试。该基准涵盖四个任务场景下的 2,000 个提示(prompt),并定义了一个包含五个错误类别及其 19 个细分子类的错误分类体系。此外,我们开发了 ConStory-Checker,这是一个自动化检测流程,能够识别矛盾之处,并将每一项判断建立在明确的文本证据基础之上。通过五个研究问题对多种大型语言模型进行评估,我们发现一致性错误呈现出若干显著规律:此类错误在事实维度与时序维度上最为常见;多出现在叙事的中间部分;更易发生于词元级熵值较高的文本片段中;且某些错误类型倾向于并发出现。这些发现可为未来提升长文叙事生成一致性的研究工作提供重要参考。项目主页请访问:https://picrew.github.io/constory-bench.github.io/。
一句话总结
来自微软和新加坡科技设计大学的研究人员推出了 ConStory-Bench,这是一个带有自动化检查器的新基准,用于评估长篇幅故事生成中的叙事一致性。该基准揭示了事实性和时间性错误经常出现在叙事中段,从而为未来的模型改进提供了指导。
主要贡献
- 现有的故事生成基准忽视了长篇幅叙事中的一致性错误,这促使了 ConStory-Bench 的创建。该基准包含 2,000 个提示词,并建立了一个包含 5 个错误类别和 19 个细分子类的分类法。
- 作者引入了 CONSTORY-CHECKER,这是一个自动化流程,能够检测叙事中的矛盾,并通过精确引用将每个判断建立在明确的文本证据之上。
- 对多种大语言模型(LLM)的系统评估显示,一致性错误在事实和时间维度上最为频繁,倾向于出现在故事的中段,并且与更高的词元级熵(token-level entropy)相关。
引言
长篇幅叙事生成对于内容创作和教育写作日益重要,然而大语言模型往往无法在数千个词元的跨度内保持一致性,经常与既定事实、角色特征或世界观规则相矛盾。先前的工作主要集中在情节质量和流畅度上,而忽视了对全局一致性的系统评估,且现有的自动化评判器通常缺乏明确的文本证据来支持其评估。为了填补这些空白,作者推出了 ConStory-Bench,这是一个包含 2,000 个提示词和详细错误分类法的综合基准,同时推出了 CONSTORY-CHECKER,这是一个能够检测矛盾并将每个判断建立在精确文本引用之上的自动化流程。
数据集
-
数据集构成与来源 作者通过聚合来自七个不同公共语料库的种子故事构建了 ConStory-Bench:LONGBENCH、LONGBENCH_WRITE、LONGLAMP、TELLMEASTORY、WRITINGBENCH、WRITINGPROMPTS 和 WIKIPLOTS。这些来源提供了创意写作查询和完整叙事,作为构建基准的基础。
-
每个子集的关键细节 最终数据集由 2,000 个高质量提示词组成,分布在四种不同的任务类型中,旨在测试特定的叙事挑战:
- 生成(Generation):从最小化的情节设定中生成自由形式的叙事。
- 续写(Continuation):在保持既定事实的同时,将初始故事片段扩展为完整叙事。
- 扩展(Expansion):通过阐述隐含细节,从简洁的情节大纲中发展出长篇幅故事。
- 补全(Completion):根据预定的开头和结尾撰写完整故事,填充中间的情节。 每个提示词的目标生成长度限制在 8,000 至 10,000 词之间。
-
数据使用与处理 作者利用全部 2,000 个提示词进行评估而非训练,让模型在可比设置下为所有任务场景生成输出。数据处理流程包括:
- LLM 重写:使用 o4-mini 模型将收集到的故事转换为基于真实叙事元素的任务特定提示词。
- 去重:应用基于 MinHash 的技术去除近重复的提示词。
- 质量控制:通过人工检查和自动启发式方法的组合,过滤掉低质量或琐碎的案例。
-
元数据与错误分类法 为了实现系统评估,作者开发了一个分层的一致性错误分类法,包含五个顶层类别和 19 种细粒度错误类型。该框架涵盖了时间线与情节逻辑、角色塑造、世界观构建规则、事实细节以及叙事风格方面的矛盾。该基准采用“以 LLM 为评判器”(LLM-as-judge)的流程来检测这些错误并将其分类到定义的类别中。
方法
作者推出了 ConStory-Checker,这是一个自动化的“以 LLM 为评判器”流程,专为长篇幅叙事生成中的可扩展且可审计的一致性评估而设计。该系统通过一个结构化的四阶段流程运行,将原始故事文本转化为量化的一致性指标。
参考框架图以了解整个流程的概览,该流程涵盖了长故事生成、一致性分析和加权评分。
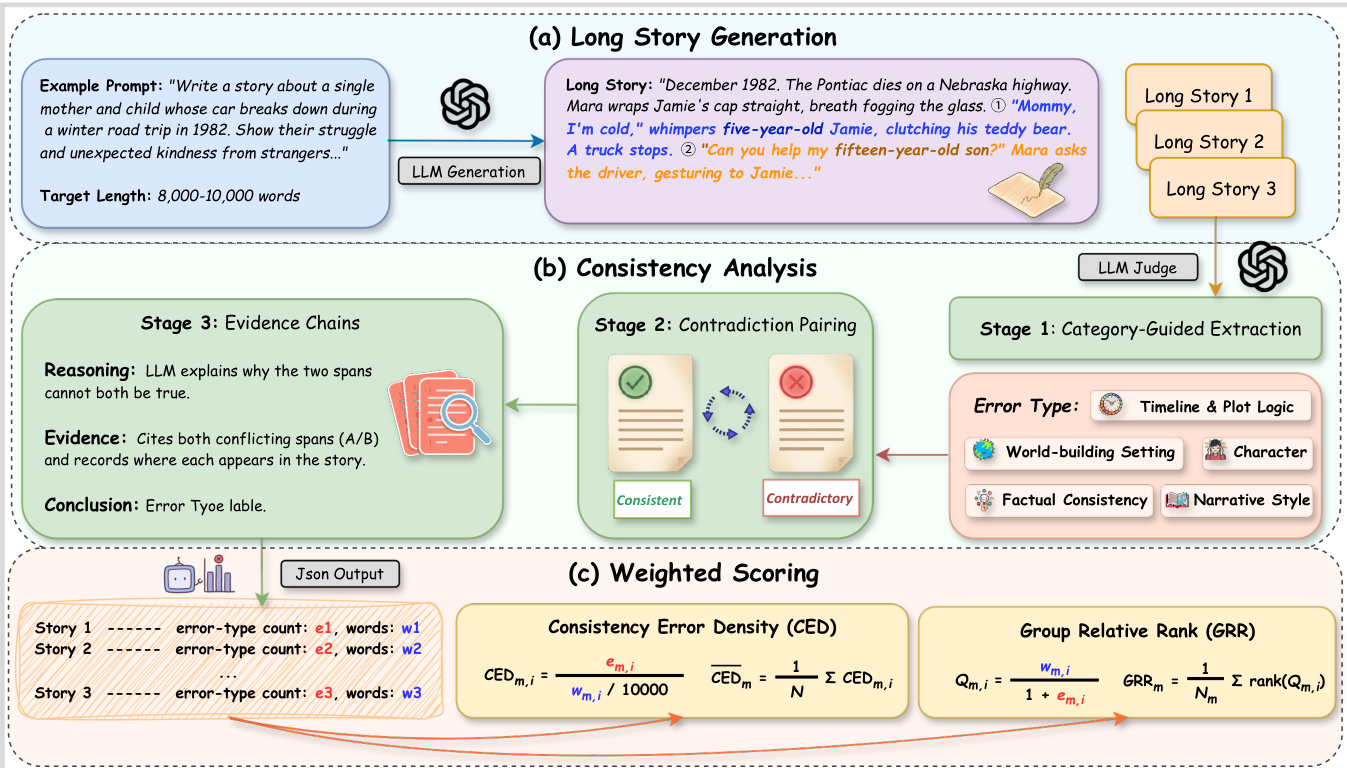
一致性分析阶段分为三个核心阶段。阶段 1 涉及类别引导提取(Category-Guided Extraction),即使用特定提示词在五个维度上扫描叙事:时间线与情节逻辑、角色塑造、世界观与设定、事实与细节一致性以及叙事风格。该阶段根据详细的分类法提取易产生矛盾的片段。
如下图所示,“时间线与情节逻辑”类别专注于提取包含冲突日历信息、持续时间矛盾、同时性问题以及因果逻辑违规的句子。

同样,“角色塑造”类别针对叙事中的记忆矛盾、知识不一致和技能波动。

“世界观与设定”类别评估核心规则违规、社会规范以及地理矛盾,以确保故事世界的内部逻辑保持稳定。

最后,“事实与细节一致性”类别解决外观不匹配、命名混淆和数量不匹配问题,以验证具体细节。

提取之后,阶段 2 执行矛盾配对(Contradiction Pairing),将提取的片段进行两两比较,并分类为“一致”或“矛盾”,以减少误报。阶段 3 生成证据链(Evidence Chains),记录推理过程、带有位置的具体证据引用以及每个已识别错误的结论。输出在阶段 4 被标准化为 JSON 报告,捕获引用、位置、配对以及锚定在精确字符级偏移量上的错误类别。
为了评估性能,作者采用了两个互补的指标来解决长度偏差和提示词难度问题。首先,一致性错误密度(Consistency Error Density, CED)通过输出长度对错误进行归一化,测量模型 m 在故事 i 上每万字的错误数:
CEDm,i=wm.i/10000em,i
其中 em,i 表示错误数量,wm,i 表示词数。模型级别的分数是对所有故事取平均值。其次,为了控制实例级别的难度,组相对排名(Group Relative Rank, GRR)在每个提示词组内对模型进行排名。对于每个故事 i,定义了一个感知长度的质量分数 Qm,i:
Qm,i=1+em.iwm,i
模型根据 Qm,i 在同一故事内进行排名,GRR 计算如下:
GRRm=Nm1∑i∈Imranki(Qm,i)
该框架允许在不同模型和生成策略之间对叙事一致性进行稳健的比较。
实验
- 使用 ConStory-Bench 和 ConStory-Checker 对专有、开源、能力增强型及代理系统进行的评估证实,当前的大语言模型系统地产生叙事不一致性,特别是在事实追踪和时间推理方面。
- 对输出长度的分析显示,随着故事长度的增加,一致性错误呈线性累积,尽管模型在生成偏好上存在显著差异,从而在叙事完整性和错误密度之间形成了多样的权衡。
- 对错误来源的调查显示,一致性失败发生在模型不确定性较高的区域,那里的词元级熵和困惑度(perplexity)较高,表明这些指标可以作为触发验证例程的可靠早期预警信号。
- 相关性研究表明,事实和细节错误充当中心枢纽,经常与角色塑造和世界观构建错误共同出现,而叙事和风格的不一致性则通过不同的机制独立产生。
- 位置分析表明,错误并非均匀分布;事实通常在叙事的中前期确立,而矛盾则随后出现。时间和地理错误表现出较大的差距,需要强大的长程记忆,而视角混淆则源于局部上下文的失败。
- 任务类型评估强调,与续写或补全任务相比,开放式故事生成构成了最大的一致性挑战。