Command Palette
Search for a command to run...
RACAS:通过单一 Agent 系统控制多样化机器人
RACAS:通过单一 Agent 系统控制多样化机器人
Dylan R. Ashley Jan Przepióra Yimeng Chen Ali Abualsaud Nurzhan Yesmagambet Shinkyu Park Eric Feron Jürgen Schmidhuber
摘要
许多机器人平台通过应用程序接口(API)暴露底层控制能力,使外部软件能够指挥其执行器并读取传感器数据。然而,从这些低级接口过渡到高级自主行为,需要构建复杂的处理流水线,其各组成部分往往要求不同的专业领域知识。现有旨在弥合这一鸿沟的方法,要么针对每种新机器人构型都需要重新训练,要么仅在结构相似的平台上得到验证。本文提出 RACAS(基于智能体系统的机器人无关控制),这是一种协作式智能体架构。该架构包含三个基于大语言模型(LLM)或视觉 - 语言模型(VLM)的模块——监测器(Monitors)、控制器(Controller)和记忆策展器(Memory Curator),它们仅通过自然语言进行通信,从而实现闭环机器人控制。RACAS 仅需提供机器人的自然语言描述、可用动作定义以及任务规范;在不同平台间迁移时,无需修改任何源代码、模型权重或奖励函数。我们在多种任务中评估了 RACAS 的性能,测试平台包括轮式地面机器人、近期发表的新型多关节机器人肢体以及水下航行器。实验结果表明,RACAS 在这些截然不同的平台上均成功完成了所有指定任务,彰显了智能体人工智能在显著降低机器人方案原型构建门槛方面的巨大潜力。
一句话总结
来自 KAUST 及瑞士、波兰合作研究所的研究人员推出了 RACAS,这是一种协作式智能体架构,利用 LLM 和 VLM 模块,仅依靠自然语言提示而非重新训练或代码修改,即可在截然不同的机器人之间实现零训练泛化。
主要贡献
- 当前的机器人控制流程难以在多样化平台上弥合底层 API 与高层自主性之间的鸿沟,通常仅能在结构相似的机器人上进行重新训练或验证。
- RACAS 引入了一种协作式智能体架构,其中基于 LLM/VLM 的模块仅通过自然语言进行通信,从而仅利用声明式提示配置即可实现闭环控制。
- 该系统在三种截然不同的异构平台上实现了零训练泛化,包括轮式地面机器人、新型多关节肢体以及水下航行器,无需修改源代码或模型权重。
引言
现代机器人技术依赖于复杂的流程,将底层传感器 API 与高层自主行为连接起来,但这一过程需要分散的专业知识,且随着机器人平台多样性的增加,其扩展性较差。先前的解决方案要么需要对每种新的机器人形态进行大量的重新训练和数据收集,要么仅在受控环境中针对结构相似的机器进行过验证,导致在截然不同的系统上缺乏零训练泛化能力。作者介绍了 RACAS,这是一种协作式智能体架构,利用三个基于自然语言的模块实现闭环控制,无需修改源代码、模型权重或奖励函数。通过将所有特定于形态的知识限制在声明式提示中,并利用动态记忆策展人,该系统成功在轮式地面机器人、新型多关节肢体和水下航行器上执行了任务,展示了在异构形态和环境之间前所未有的适应性。
数据集
- 作者在三个不同的机器人平台上评估了他们的方法:Limb 多关节机械臂、Clearpath Dingo 轮式地面机器人以及 BlueROV2 水下航行器。
- Limb 平台配备单指末端执行器和六个机载摄像头,但作者禁用了两个侧向摄像头以增加任务难度。
- 对于 Limb 机器人,低分辨率 100×100 像素的摄像头输入在使用两阶段 Swin2SR 超分辨率流程进行 VLM 推理之前,被上采样至 768×768 像素。
- Clearpath Dingo 在 NVIDIA Isaac Sim 仿真环境和物理环境中运行,其动作集仅限于地面平面运动,包括前进、后退和旋转指令。
- Dingo 的仿真使用三个分辨率为 640×480 像素的摄像头,而真实世界设置则依赖单个前向摄像头,分辨率为 1280×800 像素。
- Dingo 的成功定义为与目标物体的距离在 1 米以内。
- BlueROV2 是一款由推进器驱动的车辆,通过 MAVLink 协议和 ArduSub 固件进行控制,使用单个前向 1920×1080 像素摄像头。
- 尽管 BlueROV2 是全驱动系统,但本研究将控制限制在三个轴(纵荡、垂荡和偏航),从而形成包含六个指令的离散动作集。
- BlueROV2 的推力大小配置在 0–1000 量级中的 300 到 600 之间,指令持续时间固定为 2 秒。
方法
作者提出了一个语言驱动的机器人控制框架,旨在无需重新训练即可在异构机器人形态上运行。核心方法将闭环控制分解为三个协作的 LLM 流程:感知、决策和记忆,并通过统一的自然语言接口连接。所有特定于形态的知识都封装在声明式提示配置中,而非学习参数。
整体系统架构将依赖机器人的组件与不依赖机器人的智能分离开来。请参阅框架图以直观了解这些交互。依赖机器人的一侧管理物理接口,包括原生机器人 API 和基于工具的 API 层,以及文本机器人描述。不依赖机器人的一侧则容纳智能模块:监控器、控制器和记忆策展人。这种分离使得通过更新任务描述和 API 即可轻松更改任务和机器人,而无需修改控制逻辑。
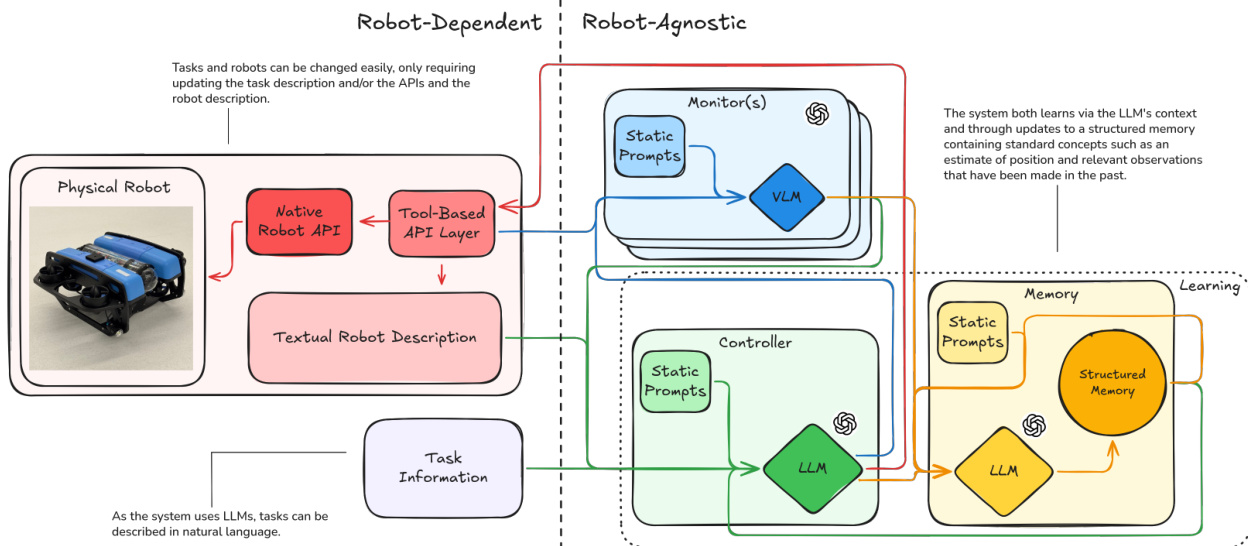
控制循环在离散时间步 t 中进行。在每一步,控制器根据当前任务状态生成一个有针对性的视觉查询 qt。该查询被分发给每个监控器 mc,监控器通过视觉语言模型(VLM)处理其摄像头图像 It(c),返回自然语言场景描述 ot(c)。随后,控制器接收所有监控器的观察结果,对其进行推理,并从允许的动作集 A 中选择一个动作 at。该动作通过硬件抽象层分发给机器人。最后,记忆策展人将交互记录整合到持久环境记忆 Mt 中。
下图展示了实际运行期间推理过程的详细视图:
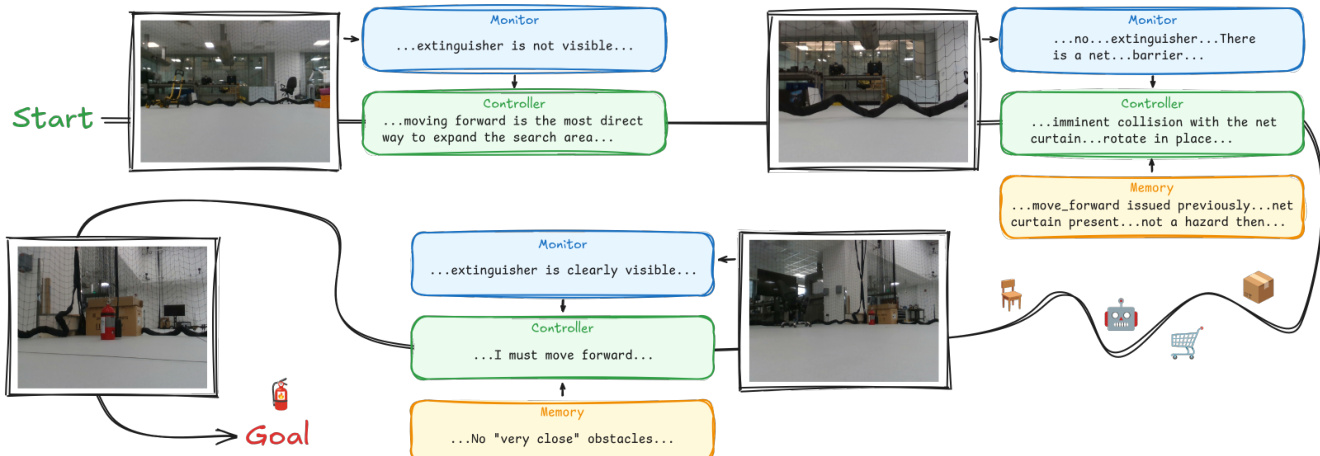
控制器在每一步都会使用动态组成的系统提示进行重新初始化。该提示组装了六个组件:机器人描述 D、动作接口 A、环境记忆 Mt−1、本体感知状态 st、动作历史 Ht 以及任务规范 τ。在第一步中,控制器基于此上下文进行推理以生成视觉查询 qt。在随后的步骤中,它接收监控器观察结果,输出推理轨迹,随后输出单个动作 at。
感知由监控器模块处理,该模块将感知重新表述为语言条件的视觉问答过程。与产生固定模式数值输出的传统流程不同,这种设计确保了感知是任务自适应的。查询 qt 随执行阶段而变化,允许监控器在不改变架构的情况下关注场景的不同方面。输出位于与控制器输入相同的表示空间中,消除了对手工设计编码器的需求。
为了管理长期交互,系统采用了由 LLM 策展的持久记忆。简单地附加观察结果会导致上下文无限增长,因此记忆策展人执行增量重写。它接收当前记忆 Mt−1 和最新的交互记录,以生成更新后的记忆 Mt。此操作压缩冗余信息,解决矛盾,并丢弃无关细节。策展人将知识组织为四类:物理环境、机器人状态、重要命令的策展历史以及任务状态。此外,系统通过交叉模态位置推断,将摄像头观察结果与机器人动作相交,以估计物体相对于机器人的位置。
实验中使用的物理形态(如下所示的移动机械臂)完全通过自然语言描述和 API 规范定义。

将框架适配到新平台需要编写三个文本文件:机器人描述 D、指定动作 A 的工具定义文件以及任务描述。无需修改源代码、模型权重或奖励函数。系统通过 LLM 的上下文以及包含标准概念(如位置估计和相关过去观察)的结构化记忆更新进行学习。
实验
- 该框架在三个不同的机器人平台(机器人肢体、地面机器人和水下航行器)上进行了评估,以验证其使用相同的控制逻辑在截然不同的形态和环境中进行泛化的能力。
- 在物体定位、目标接近和水下导航方面的实验表明,该系统能够在合理的步数内成功完成任务,在适用的情况下显著优于随机动作基线。
- 结果表明,该系统有效利用了大型语言和视觉模型的泛化能力来解决导航任务,无需针对特定平台的代码修改或训练数据。
- 性能分析显示,任务完成时间主要受限于传感器保真度和定位物体所需的时间,而非底层控制架构或模型推理。
- 研究证实,统一的零训练控制框架可以仅通过自然语言描述和现有 API 适配到新机器人,尽管当前的局限性包括高推理延迟和缺乏直接深度信息。