Command Palette
Search for a command to run...
输入有偏,输出亦有偏?在基础模型中探索无偏子网络
输入有偏,输出亦有偏?在基础模型中探索无偏子网络
Ivan Luiz De Moura Matos Abdel Djalil Sad Saoud Ekaterina Iakovleva Vito Paolo Pastore Enzo Tartaglione
摘要
深度学习中的算法偏见问题催生了多种去偏技术,其中许多方法涉及复杂的训练流程或数据集操作。然而,一个引人深思的问题随之浮现:能否在不依赖额外数据(如无偏训练集)的情况下,从标准范型训练(vanilla-trained)模型中提取出公平且与偏见无关的子网络?本文提出了一种名为“偏差不变子网络提取”(Bias-Invariant Subnetwork Extraction, BISE)的学习策略,该策略能够在不重新训练或微调原始参数的情况下,识别并隔离已存在于常规训练模型中的“无偏”子网络。我们的研究表明,通过剪枝即可提取此类子网络,且这些子网络无需任何修改即可正常运行,从而有效降低对偏见特征的依赖,同时保持鲁棒性能。本研究成果表明,通过参数移除对预训练神经网络进行结构适配,可实现高效的偏见缓解,相较于依赖数据或需(重新)训练全部模型参数的高成本策略,更具优势。在多个常用基准数据集上的大量实验表明,本方法在去偏模型的性能与计算效率方面均展现出显著优势。
一句话总结
来自巴黎电信学院和热那亚大学的研究人员提出了“偏差不变子网络提取”(Bias-Invariant Subnetwork Extraction, BISE)方法。该方法通过剪枝预训练模型来隔离公平子网络,无需重新训练或额外数据,为依赖数据集操纵或全参数更新的复杂去偏技术提供了一种计算高效的替代方案。
主要贡献
- 当前的去偏技术通常需要复杂的重新训练或额外的无偏数据,而本工作解决了从标准原生训练模型中提取公平子网络的挑战,无需任何参数更新或外部数据集。
- 提出的偏差不变子网络提取(BISE)方法通过结构化剪枝,优化一个平衡经验损失并最小化偏差相关信息的目标函数,从而识别并隔离与偏差无关的子网络。
- 在常见基准测试上的大量实验表明,这些提取出的子网络无需修改即可有效运行,并在进一步微调时达到最先进水平(SOTA)的准确率,为高成本的数据中心策略提供了一种计算高效的替代方案。
引言
深度学习中的算法偏差通常源于模型学习了训练数据中的虚假相关性,导致不公平的结果,违反了如《欧盟人工智能法案》等新兴法规。当前的缓解策略通常需要复杂的重新训练程序、对抗性目标,或访问往往不可用或难以策划的平衡数据集。作者提出了偏差不变子网络提取(BISE),这是一种利用结构化剪枝在标准原生训练模型中识别并隔离抗偏差子网络的方法。该方法通过学习辅助变量来移除与偏差相关的参数,同时保留任务性能,从而消除了对重新训练或额外无偏数据的需求。
数据集
数据集概览
作者使用五个流行的数据集来评估其方法,这些数据集旨在测试图像和文本领域的去偏能力。每个数据集都在目标标签和偏差属性之间引入了特定的虚假相关性。
- BiasedMNIST:基于 MNIST 构建的合成数据集,其中背景颜色与数字标签相关。训练集使用高相关概率(ρ)创建强偏差对齐,而测试集使用 ρ=0.1 以确保无偏评估。
- Corrupted-CIFAR10:源自 CIFAR10,该数据集应用了与物体类别相关的特定图像损坏(如雾、亮度)。训练集生成的偏差对齐概率范围从 0.95 到 0.995,而测试集保持无偏,ρ=0.1。
- CelebA:一个包含 202,599 张图像和 40 个属性的真实人脸数据集。作者将“金发”(BlondHair)视为目标标签,将“男性”(Male)视为偏差,利用数据中金发主要与女性相关的虚假相关性。
- Multi-Color MNIST:一个用于处理多重偏差的基准测试,其中图像背景被分为左右两侧,每侧都有与数字相关的不同颜色。训练集对两侧均使用高相关概率(ρL=0.99,ρR=0.95),而测试集对两侧均使用低概率(0.1)。
- CivilComments:一个用于预测毒性分类的文本数据集。偏差定义为存在任何敏感属性(如性别、种族、宗教)。作者使用了该数据集的粗粒度版本,其中这八个属性被聚合为单个二元偏差标签。
使用与处理细节
本文采用特定的架构和处理策略来在这些数据集上训练和评估模型。
- 模型架构:作者对 BiasedMNIST 使用卷积神经网络,对 CelebA 和 Corrupted-CIFAR10 使用在 ImageNet-1K 上预训练的 ResNet-18,对 Multi-Color MNIST 使用多层感知机(MLP),对 CivilComments 使用 BERT 模型。
- 训练策略:该方法涉及通过 SGD 学习掩码,学习率为 10−2,并采用衰减的温度参数 τ。辅助分类器训练 50 个 epoch 以识别偏差特征。
- 处理多重偏差:对于 Multi-Color MNIST,作者采用两个独立的辅助分类器来分别预测左侧和右侧背景颜色,遵循重加权策略以管理双重偏差。
- 数据划分:在所有基于图像的实验中,训练数据被故意设置为有偏,以迫使模型依赖虚假特征,而测试数据被构建为无偏,以测量真正的泛化能力。
- 微调:在使用 BISE 方法提取子网络后,作者使用与原始原生模型相同的优化器设置对模型进行微调。
方法
作者提出了 BISE(偏差不变子网络提取),这是一种去偏剪枝方法,旨在从预训练的有偏模型中识别并提取无偏子网络,而无需对原始参数进行额外训练或访问无偏数据。该方法在监督去偏设置下运行,其中训练数据集 Dtrain 包含目标标签 y 与偏差属性 b 之间的虚假相关性,而测试集 Dtest 是无偏的。
整体工作流程如下图所示,展示了从标准有偏模型到去偏剪枝模型的转变。
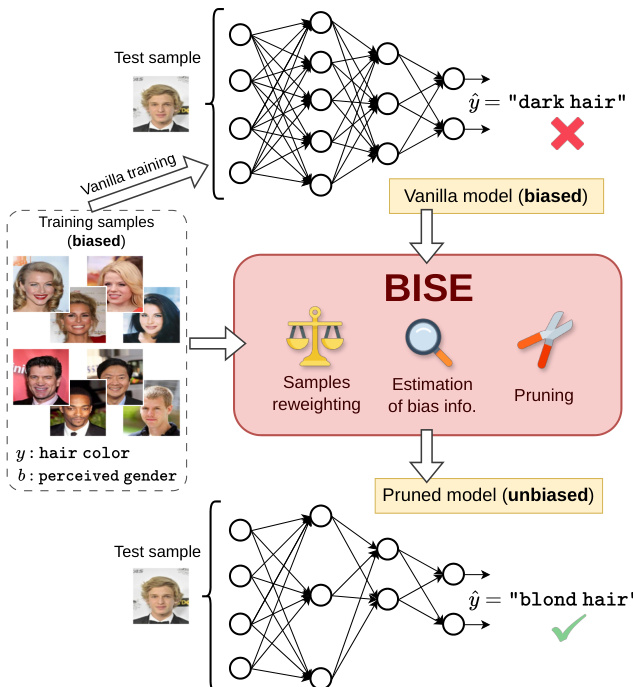
如图所示,该过程始于在偏差样本上训练的原生模型,由于依赖虚假特征,该模型在无偏测试用例上往往表现不佳。BISE 通过三种核心机制进行干预:样本重加权、偏差信息估计和剪枝。其目标是找到原始网络中维持目标任务准确率同时最小化对偏差属性依赖的神经元子集。
详细的架构和训练动态如下图所示。
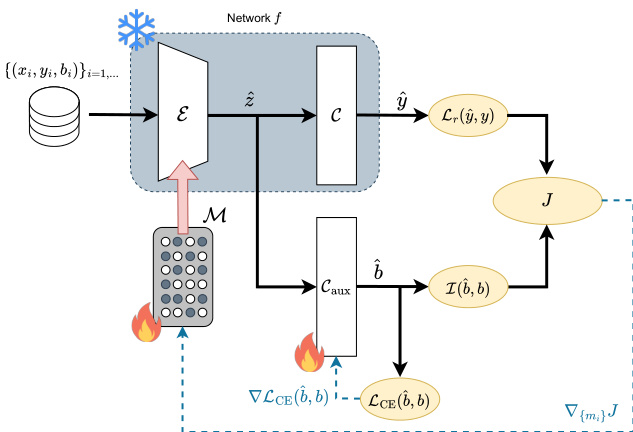
网络 f 被分解为编码器 E 和分类器 C。作者引入了一个可学习的剪枝掩码 M,应用于编码器的参数。具体而言,对于编码器中的每个结构组件(例如神经元或滤波器)i,学习一个掩码参数 mi。输出 hi 被修改为:
h^i=hi⋅1{m^i≥0.5}, with m^i=σ(τmi)其中 σ(⋅) 是 sigmoid 函数,τ 是在训练过程中退火至零的温度参数。这种门控机制强制对剪枝决策具有置信度,其中 mi<0 表示剪枝,mi≥0 表示保留。
为了优化掩码,作者定义了一个复合目标函数 J,以平衡任务性能和偏差减少:
J(y^,y,b^,b)=Lr(y^,y)+γI(b^,b)第一项 Lr(y^,y) 是重加权的交叉熵损失。为了抵消 Dtrain 中偏差对齐样本的普遍性,通过分配与组大小成反比的权重来放大偏差冲突样本的贡献。第二项 I(b^,b) 估计预测偏差 b^ 与真实偏差 b 之间的互信息。这是通过将辅助分类器 Caux 连接到瓶颈表示 z^ 来实现的,如架构图所示。辅助头被训练以从 z^ 预测 b,最小化 I(b^,b) 确保潜在表示包含较少的偏差属性信息。
训练过程涉及一个迭代循环,其中掩码参数 {mi} 和辅助分类器 Caux 联合更新。温度 τ 定期退火以锐化掩码决策。一旦温度降至阈值 τmin 以下,便提取最终的二进制掩码,生成一个对原始训练数据中存在的虚假相关性具有鲁棒性的剪枝子网络。
实验
- 在 BiasedMNIST、Corrupted-CIFAR10、CelebA、Multi-Color MNIST 和 CivilComments 上的主要实验验证了 BISE 提取的子网络具有比原生稠密模型更高的无偏准确率,即使在强偏差下也能有效缓解虚假相关性。
- 对比研究表明,BISE 通过识别无偏子结构且无需重新训练原始参数,其表现优于其他去偏方法以及随机或基于幅值的剪枝方法。
- 消融研究证实,损失函数中的互信息项对于实现高稀疏度和减少偏差相关特征的保留至关重要,同时该方法对超参数变化表现出低敏感性。
- 在无监督设置和噪声偏差标签下的实验表明,BISE 保持竞争力和鲁棒性,即使在没有真实偏差信息的情况下也能成功提取改进的子网络。
- 对潜在表示的分析表明,剪枝后的子网络使得偏差特征更难被预测,证实了偏差依赖的减少,尽管当偏差极其严重或多个偏差在没有后续微调的情况下相互作用时,性能会受到限制。