Command Palette
Search for a command to run...
通过强化学习中组级自然语言反馈进行 Bootstrapping 探索
通过强化学习中组级自然语言反馈进行 Bootstrapping 探索
Lei Huang Xiang Cheng Chenxiao Zhao Guobin Shen Junjie Yang Xiaocheng Feng Yuxuan Gu Xing Yu Bing Qin
摘要
大语言模型(LLMs)通常通过与环境交互,接收到多样化的自然语言(NL)反馈。然而,目前的强化学习(RL)算法仅依赖于标量奖励(scalar rewards),导致 NL 反馈中蕴含的丰富信息未能得到充分利用,进而引发探索效率低下的问题。在这项工作中,我们提出了 GOLF,这是一个通过显式利用组级语言反馈(Group-level Language Feedback)来引导针对性探索,并实现可执行改进(actionable refinements)的 RL 框架。GOLF 聚合了两种互补的反馈来源:(i) 指出错误或提出针对性修复方案的外部评论(external critiques);(ii) 提供替代性局部构思及多样化失败模式的组内尝试(intra-group attempts)。这些组级反馈被聚合以生成高质量的改进方案(refinements),并作为 off-policy scaffolds 自适应地注入训练过程,从而在稀疏奖励区域提供针对性的引导。同时,GOLF 在统一的 RL 循环中联合优化生成(generation)与改进(refinement)能力,构建了一个持续提升这两项能力的良性循环。在可验证(verifiable)与不可验证(non-verifiable)benchmark 上的实验表明,GOLF 实现了卓越的性能和探索效率;与仅基于标量奖励训练的 RL 方法相比,其样本效率(sample efficiency)提升了 2.2 倍。
一句话总结
作者提出了 GOLF,这是一个强化学习框架,通过聚合外部批评和组内尝试来启动探索,生成组级自然语言反馈,从而产生可操作的优化,这些优化作为离线策略支架被自适应注入,用于在稀疏奖励区域提供针对性指导,并在统一 RL 循环中联合优化生成和优化,在可验证和不可验证基准上相比仅基于标量奖励训练的 RL 方法实现了 2.2 倍的样本效率提升。
核心贡献
- 本文介绍了 GOLF,这是一个强化学习框架,聚合外部批评和组内尝试以产生高质量的优化。这些优化作为离线策略支架被自适应注入训练,以在稀疏奖励区域提供针对性指导。
- 该工作在结果奖励下联合训练问题解决和自优化,以创造改进的良性循环。学习到的优化能力生成高质量样本,作为探索的自适应指导。
- 在可验证和不可验证基准上的实验表明,该框架实现了卓越的性能和探索效率。结果表明,与仅基于标量奖励训练的强化学习方法相比,样本效率提高了 2.2 倍。
引言
大型语言模型通常依赖由稀疏标量奖励驱动的强化学习,但这种方法阻碍了探索效率,因为策略缺乏如何纠正错误的明确指导。虽然自然语言反馈提供了更丰富的监督,但现有算法往往未能充分利用此信息,或未能利用同一 rollout 组内替代尝试的互补信号。作者提出了 GOLF,这是一个聚合外部批评和组内尝试以产生可操作优化的框架。它们将这些高质量的优化作为离线策略支架注入,以指导稀疏奖励区域的探索,同时在统一循环内联合优化生成和优化。
数据集
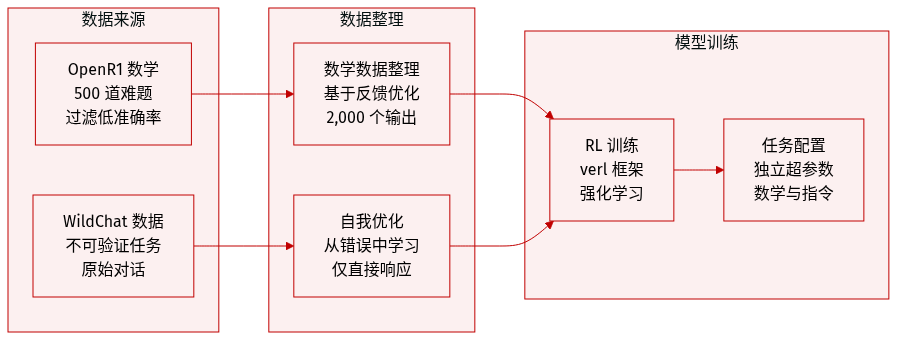
作者使用以下组成和处理策略构建数学推理和不可验证任务的数据集:
- 数学推理: 从 OpenR1 中提取了一个包含 500 个问题的挑战性子集。作者筛选了 Qwen-3-8B 实现零 pass@4 准确率的项。在不同反馈条件下执行优化以生成 2,000 个输出进行评估。
- 不可验证任务: 团队利用 WildChat 数据,采用自优化提示结构。通过从错误中学习并结合候选响应及其相关反馈分数中的优势来合成响应。输出生成被限制为仅提供直接响应,而不包含元评论或介绍性文本。
- 评估基准: 使用六个基准来衡量性能,具有特定的大小和评分协议:
- AlpacaEval-v2:805 个提示,使用 GPT-4o 通过一对一胜率进行评估。
- WildBench:1,024 个提示,针对 GPT-4 参考使用实例级评分标准进行评分。
- ArenaHard-v2:500 个查询,使用 GPT-4.1 法官结合风格控制进行评估。
- CreativeWriting-v3:96 个故事章节,在 0 到 100 的尺度上评估。
- IFEval:超过 500 个提示,跨越 25 种指令类型,通过 Python 函数验证。
- IFBench:58 个约束,经过策划以测试泛化能力,使用域外提示。
- 训练和处理: 强化学习使用 verl 框架实现。针对数学推理、指令遵循和不可验证任务应用单独的超参数配置。
方法
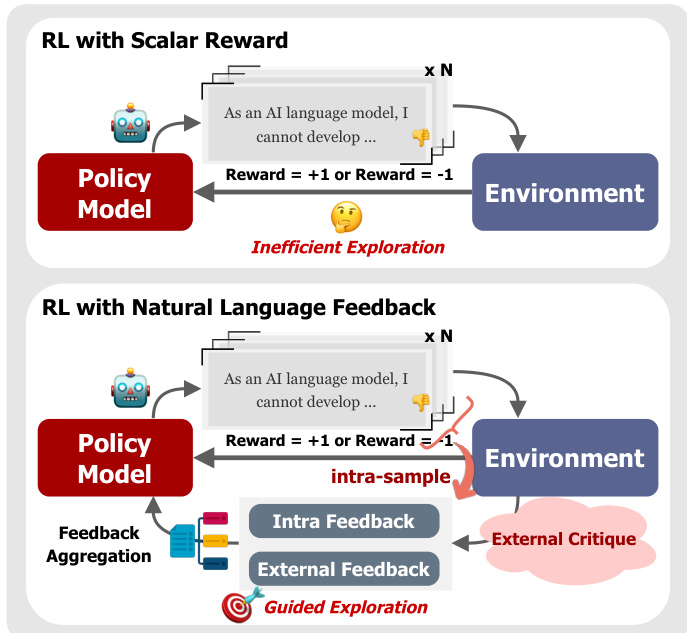
提出的框架 GOLF 引入了带自然语言反馈的强化学习 (RL-NL) 的结构化方法。与仅依赖标量奖励的标准 RL 方法不同,GOLF 利用丰富的文本批评来指导策略走向更好的解决方案。参考下方的框架图,可视化从标量奖励的低效探索到使用自然语言反馈的指导探索的转变。
该方法的核心建立在组相对策略优化 (GRPO) 之上,GRPO 通过消除对可训练价值函数的需求简化了近端策略优化。对于给定的提示 x,模型采样一组 N 个响应 {y(i)}i=1N。每个响应的优势通过在组内归一化标量奖励来计算:
A(i)=std({r(j)}j=1N)r(i)−mean({r(j)}j=1N)
然后使用带有针对参考策略的 KL 惩罚的截断代理目标来优化策略。GOLF 通过集成三个紧密耦合的组件扩展了这一基线:组级反馈聚合优化、通过混合策略优化实现自适应指导,以及自优化的联合优化。
组级反馈聚合优化
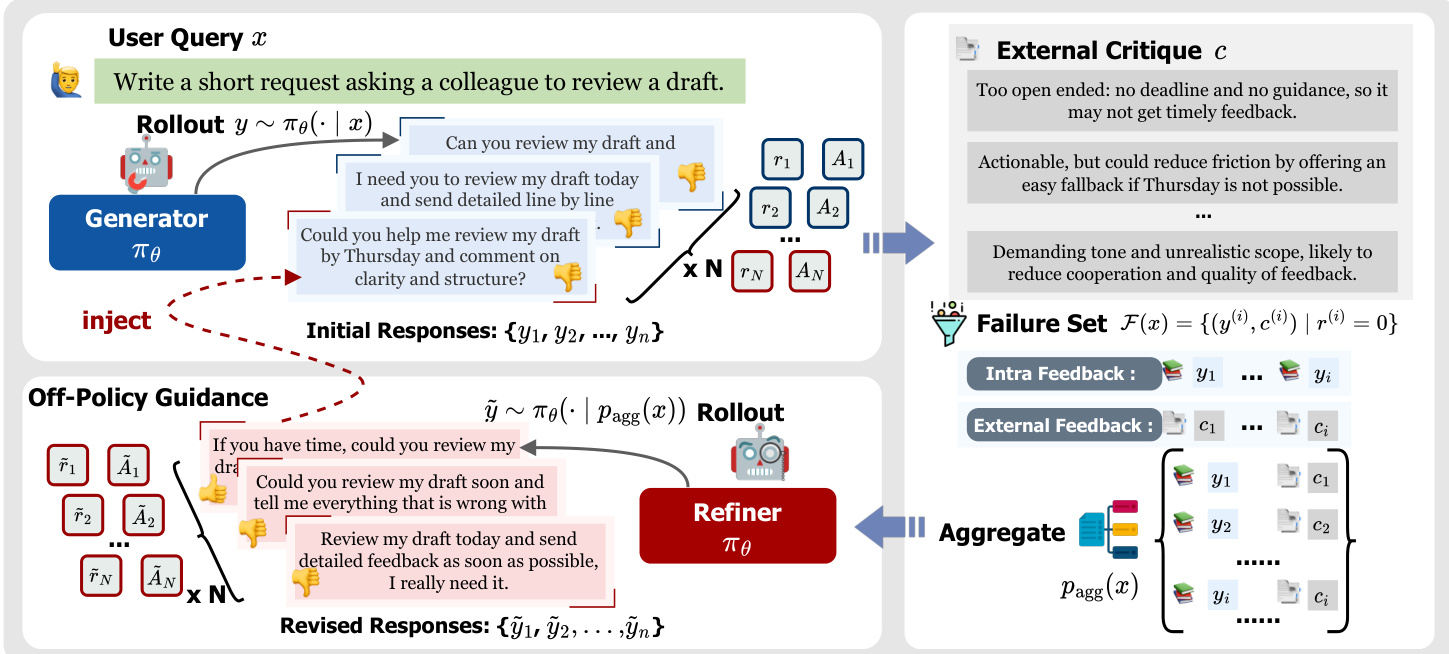
该方法不是孤立地优化失败,而是将多个失败尝试及其相应的批评聚合到单个上下文中。对于每个提示 x,生成器产生初始响应并接收标量奖励和外部批评 (r(i),c(i))。系统识别包含零奖励响应的失败集 F(x)。这些失败及其批评被连接起来以形成聚合优化提示 pagg(x):
pagg(x)=CONCAT(x, F(x))
以此提示为条件,模型采样一个优化组以产生改进的响应。此过程综合了多样化的失败模式和互补的部分想法。
如下图所示,架构明确地将初始响应的生成与优化过程分离,利用组内反馈和外部批评来构建优化器的聚合上下文。
通过混合策略优化实现自适应指导
为了解决在线策略组产生微弱优势的奖励较低的区域,作者将高质量优化视为离线策略支架。当生成组的平均奖励 s(x) 低于阈值 τ 时,触发自适应注入机制。在这种情况下,选择成功的优化并通过替换失败响应将其注入到 rollout 组中。
策略使用结合在线策略和离线策略轨迹的混合目标进行更新。混合目标 IMixed(θ) 定义为:
IMixed(θ)=Z1[on-policy objectivei=1∑Nont=1∑∣τi∣CLIP(ri,ton(θ),A^i,ε)+off-policy objectivej=1∑Nofft=1∑∣τj∣CLIP(f(rj,toff(θ)),A^j,ε)]
这里,Z 通过总 token 数量进行归一化,f(u) 是应用于离线策略比率的重塑函数,以强调低概率但有效的动作。优势通过在包含在线策略和注入的离线策略样本的增强组内归一化奖励来计算。
自优化的联合优化
最后,该框架明确训练语言模型在单个集成 RL 过程中改进直接问题解决和反馈条件优化。对于每个提示,系统收集生成和 rollout 组。这些被连接成一个联合批次,并在更新策略之前分别为每个组计算优势。这种联合优化创建了一个正反馈循环,其中改进的自优化为混合策略优化产生更高质量的支架,从而增强了对奖励轨迹的整体发现。
实验
本研究评估了 GOLF 框架在不可验证任务(如创意写作)和可验证领域(包括数学推理和代码生成)上的表现,并与多个强化学习基线进行了比较。实验结果表明,GOLF 通过聚合组级自然语言反馈以密集化学习信号,始终实现卓越的性能和更快的收敛。进一步的消融研究表明,将外部批评与组内尝试相结合显著增强了探索多样性和自优化能力,证实了文本指导在改进策略优化中的价值。
作者在 Llama-3.1-8B-Instruct 模型上针对五个不可验证基准评估了 GOLF 方法与 Pairwise-GRPO 基线的表现。结果表明,rollout 为 8 的 GOLF 始终优于 Pairwise-GRPO 变体,在大多数评估指标中实现了最高的平均得分和胜率。与 rollout 为 8 和 16 的 Pairwise-GRPO 基线相比,rollout 为 8 的 GOLF 实现了最佳平均得分。增加 Pairwise-GRPO 的 rollout 大小提高了其性能,但并未超越 GOLF 使用较少 rollout 所达到的结果。GOLF 在特定基准(如 AlpacaEval-v2 和 CreativeWriting-v3)上相对于基线方法表现出卓越的性能。

作者进行了一项消融研究,以评估不同反馈源的有效性,比较简单基线与组内、外部和混合反馈策略。结果表明,虽然单独的外部反馈相比组内反馈提供了实质性的改进,但结合两种源可获得最佳整体性能。这表明外部批评和组内尝试提供了互补信号,增强了解决方案的多样性和最终输出的准确性。混合反馈在 pass@4 和准确率指标上均实现了最高性能。单独的外部反馈显著优于组内反馈,表明外部批评具有强大价值。简单基线未能产生成功结果,突显了反馈机制的必要性。

该表展示了使用 Llama-3.1-8B-Instruct 模型在四个不可验证基准上对 GOLF 方法的消融研究。完整 GOLF 配置实现了最高平均得分,表明将组内尝试与外部批评相结合比依赖任一源单独使用更有效。移除外部反馈导致大多数评估指标的性能下降最为显著。完整 GOLF 模型相比消融变体实现了最高平均得分。移除外部反馈导致 AlpacaEval、ArenaHard 和 CreativeWriting 上的性能最低。组内和外部反馈源对于实现最佳结果都是必要的。

该表展示了针对 Llama-3.1-8B-Instruct 模型的消融研究,比较了具有自适应指导的 GOLF 方法与非自适应变体。结果表明,启用自适应注入在所有不可验证基准(包括 AlpacaEval、WildBench 和 ArenaHard)上始终产生更高的性能。文本解释说,这种自适应策略通过针对模型面临优势崩溃的提示来改进训练,有效地将无信息组转换为可用梯度。与非自适应变体相比,自适应配置在所有评估基准上实现了更高的平均得分和胜率。性能提升在 AlpacaEval-v2 和 CreativeWriting-v3 上尤为显著,其中自适应方法领先幅度很大。自适应注入通过选择性地对低奖励区域应用指导而不是使用静态注入策略,防止了性能下降。

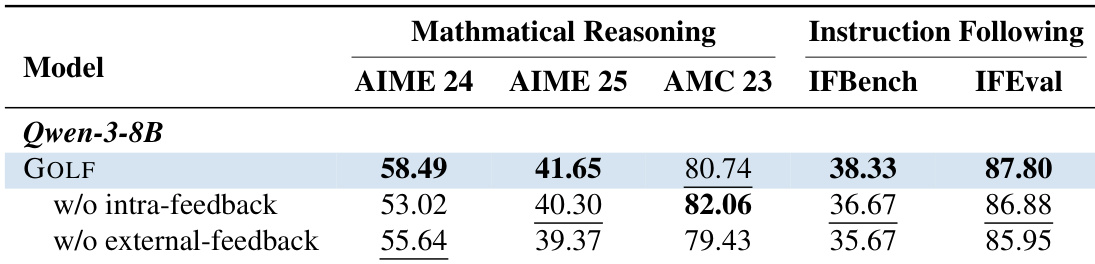
作者在 Qwen-3-8B 模型上呈现了一项消融研究,以评估 GOLF 框架内不同反馈源的贡献。结果表明,完整 GOLF 方法通常在数学推理和指令遵循基准上优于排除组内尝试或外部批评的变体。这表明聚合这两种类型的反馈对于实现最佳性能至关重要。完整 GOLF 模型通常比缺乏内部反馈或外部反馈的变体实现更高的性能。消融任一反馈组件导致大多数数学和指令遵循任务的性能下降。研究结果证实,将内部尝试与外部批评相结合为策略优化提供了互补优势。
作者在 Llama-3.1-8B-Instruct 和 Qwen-3-8B 模型上针对多个不可验证基准评估了 GOLF 方法与 Pairwise-GRPO 基线。消融研究表明,将组内尝试与外部批评相结合比单独使用任一源产生更好的性能,而自适应指导策略通过针对低奖励区域进一步增强了结果。总体而言,实验表明,集成多样化的反馈机制和自适应注入对于各种任务的最佳策略优化至关重要。