Command Palette
Search for a command to run...
相信你的模型:分布引导的置信度校准
相信你的模型:分布引导的置信度校准
Xizhong Yang Haotian Zhang Huiming Wang Mofei Song
摘要
随着测试时扩展(test-time scaling)技术的进步,大推理模型(Large Reasoning Models)展现出卓越的性能。该技术通过生成多个候选回答并选择最可靠的答案,显著提升了预测准确率。尽管 prior 研究已指出,模型内部信号(如置信度分数)可在一定程度上反映回答的正确性,并与准确率呈现分布层面的相关性,但此类分布信息尚未被充分用于指导答案选择。受此启发,我们提出了 DistriVoting 方法,在投票过程中将分布先验作为除置信度之外的另一关键信号。具体而言,本方法首先利用高斯混合模型(Gaussian Mixture Models, GMM)将混合的置信度分布分解为正样本与负样本两个分量;随后,基于这两个分量中的正负样本构建拒绝过滤器,以缓解两类分布之间的重叠。此外,为进一步从分布本身的角度减轻重叠问题,我们提出了 SelfStepConf 机制,该机制利用步骤级置信度(step-level confidence)动态调整推理过程,从而增大正负分布间的分离度,提升投票过程中置信度信号的可靠性。在涵盖 16 个模型与 5 个基准测试的实验中,我们的方法显著优于当前最先进(state-of-the-art)的现有方案。
一句话总结
东南大学与快手科技的研究人员提出了 DistriVoting,这是一个新颖的框架,通过将分布先验与置信度分数相结合,增强了大型推理模型。该方法通过分解置信度分布并引入 SelfStepConf 进行动态推理调整,在多个基准测试中显著提高了答案选择的可靠性,优于现有的最先进方法。
主要贡献
- 大型推理模型在测试时扩展过程中难以评估答案质量,因为缺乏外部奖励信号,导致置信度分数与正确性之间的分布相关性未被充分利用于答案选择。
- 提出的 DistriVoting 方法利用高斯混合模型(GMM)将混合置信度分布分解为正负分量,并应用拒绝过滤器以减轻重叠;同时,SelfStepConf 利用步骤级置信度动态调整推理过程,进一步分离这些分布。
- 在包括 HMMT2025 和 AIME 在内的 16 个模型和 5 个基准测试上的实验表明,该方法通过提高基于置信度的投票的可靠性,显著优于最先进的方法。
引言
大型推理模型依赖测试时扩展来生成多个候选答案,但由于推理过程中缺乏外部标签,选择最准确的响应仍然困难。虽然先前的方法利用内部置信度分数来指导这一选择,但它们往往未能充分利用区分正确答案与错误答案的独特统计分布,导致高置信度错误与低置信度正确响应之间存在显著重叠。为解决这一问题,作者提出了 DistriVoting,该方法利用高斯混合模型将置信度分布分解为正负分量,以在投票前过滤掉不可靠的样本。此外,作者还引入了 SelfStepConf,利用步骤级置信度动态调整推理过程,以增加正确与错误分布之间的分离度,从而在各种模型和基准测试中显著提高答案选择的准确性。
方法
所提出的框架包含两个主要组件:用于推理过程中动态置信度调整的 SelfStepConf (SSC),以及用于推理后轨迹过滤与聚合的 DistriVoting。
SelfStepConf (SSC) 作者利用 token 的负对数概率实时评估轨迹质量。对于包含 N 个 token 的轨迹,轨迹置信度 Ctraj 定义为最终答案段中 top-k 个 token 的平均负对数概率:
Ctraj=−NG×k1i∈G∑j=1∑klogPi(j)其中 G 代表用于置信度计算的 token 子集。在推理过程中,系统监控逐步置信度 CGm。如果相对变化 Δconf 低于阈值 δ 且置信度呈下降趋势,系统将触发自我反思。这涉及通过交换最高概率 token 的概率与反思 token 的概率来注入反思 token,从而在不破坏置信度计算机制的情况下迫使模型重新考虑其推理路径。
DistriVoting 推理结束后,该方法采用基于分布的投票策略从生成的轨迹中选择最终答案。该过程包括对置信度分布进行建模、过滤低质量样本以及执行分层投票。
该流程的核心是将采样轨迹的置信度分数建模为两个高斯分布的混合,分别代表正(正确)和负(错误)的推理路径。作者应用高斯混合模型(GMM)来近似这种双峰分布:
p(x)=π1N(x∣μ1,σ12)+π2N(x∣μ2,σ22)其中 π1 和 π2 是混合权重。均值较高的分量被映射到正分布,而均值较低的分量对应于负分布。
如下图所示:
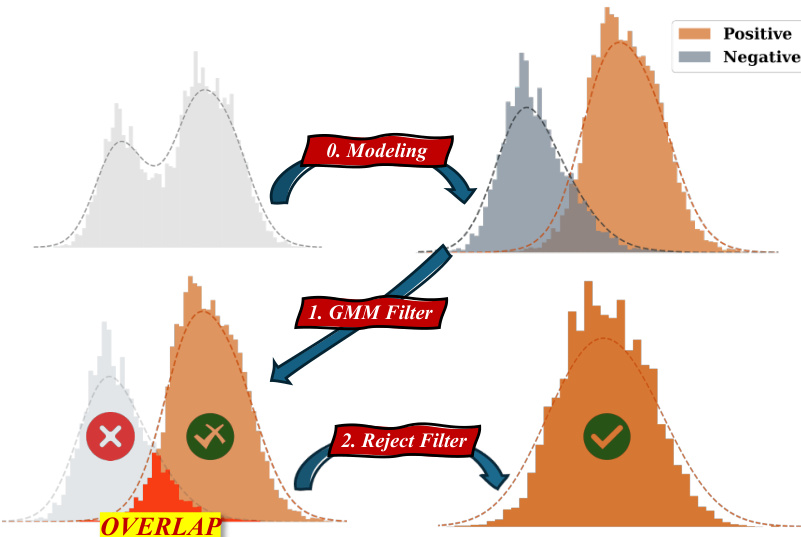
该框架按图中所示分为三个不同的阶段。首先,在建模阶段,原始置信度直方图被拟合到 GMM 分量。其次,GMM 过滤器根据拟合的分布将轨迹分离为潜在正确(Vpos)和潜在错误(Vneg)的集合。然而,这些分布之间通常存在显著重叠。为了解决这一问题,拒绝过滤器阶段利用负集合来识别并消除候选池中的假阳性样本。具体而言,该方法从负集合中识别出最可能的错误答案,并从正集合中移除与该错误答案一致的轨迹,从而细化候选池 V^pos。
最后,该方法在细化后的正池上执行分层投票 (HierVoting)。置信度分数被划分为 NC 个子区间。在每个区间内,执行加权多数投票以选择一个子答案。然后,这些子答案通过最终的加权多数投票进行聚合,以确定最终答案 Afinal。这种分层方法通过利用置信度区间确保稳健的投票,弥补了过滤阶段可能存在的性能不足。
实验
- DistriVoting 和 SelfStepConf (SSC) 被验证优于现有的测试时扩展方法(如 Self-Consistency 和 Best-of-N),证明了分布感知投票和增强的置信度区分能显著提高推理准确性。
- 自适应 GMM 过滤器通过有效建模正确和错误轨迹的双峰分布,始终优于固定的 Top-50 过滤,从而为投票提供更高品质的候选池。
- SSC 通过增加正确和错误样本置信度分布之间的分离度来增强投票性能,这提高了过滤过程的可靠性,而无需扩展模型的基本推理极限。
- 消融研究证实,GMM 过滤器是 DistriVoting 中最关键的组件,而拒绝过滤器仅在建立在稳健的分布分割之上时才能提供额外的增益。
- 所提出的方法在各种模型规模和预算下均表现出鲁棒性,随着样本量增加以提供可靠的分布信息,性能提升变得更加显著。
- 利用段落级分隔符进行步骤拆分以及基于置信度下降触发反思,被确定为在推理过程中保持逻辑完整性并提高轨迹质量的有效策略。