Command Palette
Search for a command to run...
MemSifter:基于结果驱动代理推理的 LLM 内存检索卸载
MemSifter:基于结果驱动代理推理的 LLM 内存检索卸载
Jiejun Tan Zhicheng Dou Liancheng Zhang Yuyang Hu Yiruo Cheng Ji-Rong Wen
摘要
随着大语言模型(LLM)在长周期任务中的应用日益广泛,如何维持高效、可靠的长期记忆已成为一项关键挑战。现有方法往往在成本与准确性之间面临权衡:简单的存储机制难以准确检索相关信息,而复杂的索引方法(如记忆图谱)则计算开销巨大,且可能导致信息丢失。此外,依赖主工作 LLM 直接处理全部记忆不仅计算成本高昂,响应速度也较慢。为克服上述局限,我们提出 MemSifter——一种新型框架,将记忆检索过程卸载至一个轻量级代理模型(proxy model)。MemSifter 并不增加主工作 LLM 的计算负担,而是先由小型代理模型对任务进行推理,再据此检索所需信息。该方案在索引阶段无需重型计算,在推理阶段亦仅引入极小开销。为优化代理模型,我们引入了一种面向记忆任务的强化学习(Reinforcement Learning, RL)训练范式。该范式设计了以任务结果为导向的奖励机制,其依据主工作 LLM 在完成任务中的实际表现进行评估。奖励信号通过多次与主工作 LLM 交互,量化所检索记忆的实际贡献,并依据贡献度呈阶梯式递减,从而区分不同检索排序的优劣。此外,我们还结合课程学习(Curriculum Learning)与模型融合(Model Merging)等训练技术,进一步提升模型性能。我们在八个 LLM 记忆基准测试(包括深度研究任务 Deep Research)上对 MemSifter 进行了评估。实验结果表明,在检索准确性与最终任务完成率两项指标上,MemSifter 均达到或超越了现有最先进方法(state-of-the-art)的性能水平。MemSifter 为 LLM 的长期记忆提供了一种高效且可扩展的解决方案。我们已开源模型权重、代码及训练数据,以支持后续研究。
标签中的推理依据以分析依赖关系,随后在` 标签内输出排序后的会话 ID 列表。指导此行为的具体提示结构在提示图中详细说明,其中列出了严格的标准,如主题一致性、用户需求连续性和细节重叠,以确保高质量的检索。检索到的会话随后与当前任务连接,形成工作代理的上下文。
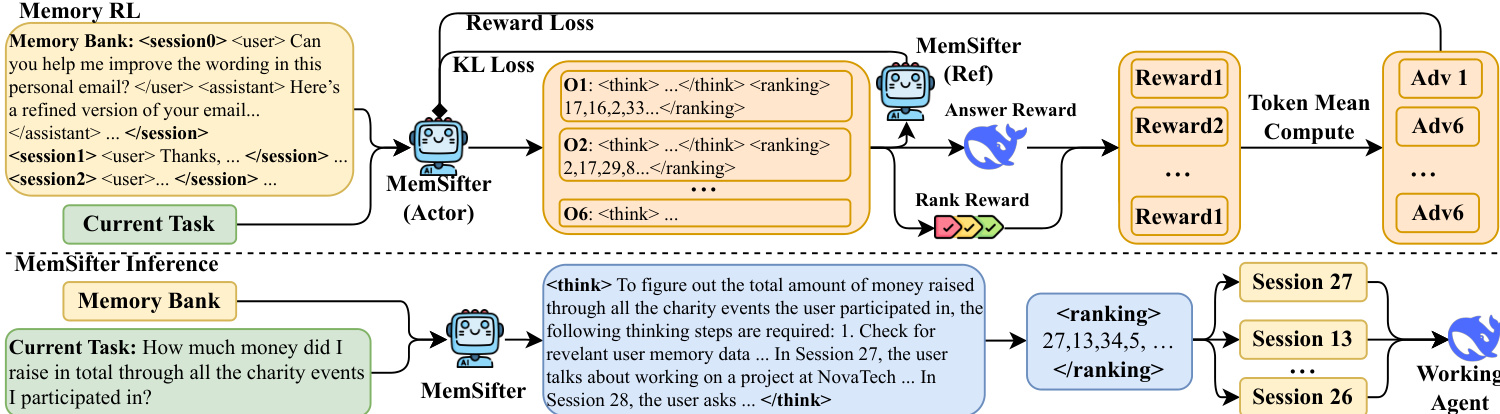

训练阶段采用强化学习(RL)方法,如框架图的上半部分所示。与标准检索指标不同,作者利用了一种面向任务结果的奖励信号。该机制根据检索到的记忆对工作 LLM 最终性能的实际影响来评估记忆,而不是其内在的检索质量。为了量化这种效用,系统采用了在奖励计算图中可视化的渐进评估策略。该过程首先获得无记忆时的基线分数 s0。然后逐步添加检索到的会话(例如,会话 27,然后会话 15)以计算分数 s1,s2,…。每个添加片段的边际效用计算为性能提升 Δsn=skn−skn−1。
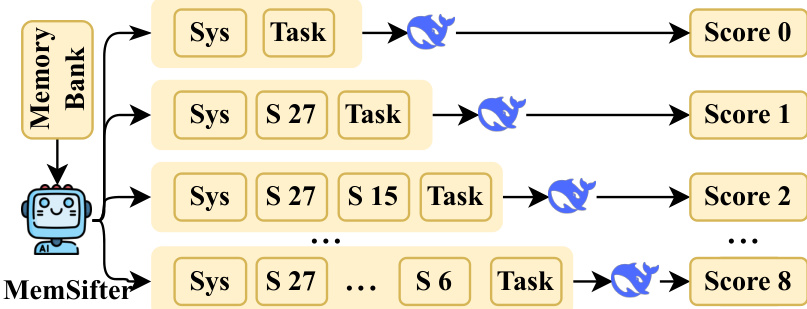
为了优先处理关键信息,奖励函数包含一个类似于 DCG 指标的秩敏感组件。最终奖励 Rans 表示为累积分数的加权和:
Rans=−s0+∑n=1Nwn⋅skn
其中权重 wn 呈对数衰减,以确保排名靠前的记忆带来的性能提升对总奖励的贡献更为显著。优化协议采用具有动态课程表的迭代训练策略。为了稳定训练的早期阶段,使用混合奖励,将基于结果的奖励与临时的检索质量指标相结合,随后退火至纯粹的面向结果优化。
实验
- MemSifter 与多种基线进行了评估,包括嵌入检索、记忆框架、基于图的推理、生成式重排序器以及原生长上下文 LLM。通过过滤噪声并优先处理具有高任务效用而非仅仅是语义相似性的信息,MemSifter 展示了更优越的任务成功率。
- 该方法证明比复杂的基于图的流程和长上下文模型更高效,以轻量级架构实现了最先进的性能,既缓解了“中间迷失”现象,又显著降低了计算成本。
- 消融研究证实,任务结果奖励机制对下游效用至关重要,因为仅针对静态相关性进行优化无法捕捉逻辑上至关重要的记忆,而秩敏感加权和边际效用指标对于准确的信用分配和训练稳定性是必不可少的。
- 进一步的分析显示,MemSifter 在召回率和排序精度方面优于推理繁重的基线,通过面向结果的奖励实现了更快的收敛,并通过适应模型不断演变能力的课程学习避免了性能平台期。
- 案例研究说明了该模型能够显式地推理任务依赖关系以过滤干扰并定位关键记忆片段,验证了其在现实场景中的有效性。