Command Palette
Search for a command to run...
LoGeR:基于混合记忆机制的长上下文几何重建
LoGeR:基于混合记忆机制的长上下文几何重建
Junyi Zhang Charles Herrmann Junhwa Hur Chen Sun Ming-Hsuan Yang Forrester Cole Trevor Darrell Deqing Sun
摘要
前馈式几何基础模型在短窗口重建任务中表现优异,然而,受限于二次方复杂度的注意力机制或循环设计中有限的有效记忆容量,将其扩展至长达数分钟的视频序列仍面临瓶颈。本文提出 LoGeR(Long-context Geometric Reconstruction,长上下文几何重建),一种新型架构,能够在无需后优化(post-optimization)的前提下,将稠密三维重建扩展至极长序列。LoGeR 以分块方式处理视频流,利用强大的双向先验实现高保真的块内推理。为应对跨块边界一致性的关键挑战,我们提出了一种基于学习的混合记忆模块。该双组件系统结合了参数化的测试时训练(Test-Time Training, TTT)记忆机制,用于锚定全局坐标系并防止尺度漂移;以及非参数的滑动窗口注意力(Sliding Window Attention, SWA)机制,以保留未压缩的上下文信息,从而实现高精度的相邻块对齐。值得注意的是,该记忆架构使 LoGeR 能够在仅 128 帧的序列上进行训练,并在推理阶段泛化至数千帧。在标准基准测试及一个经重新构建、包含长达 19,000 帧序列的 VBR 数据集上的评估结果表明,LoGeR 显著优于此前最先进的前馈方法——在 KITTI 数据集上将绝对轨迹误差(ATE)降低了逾 74%——并在前所未有的时间跨度上实现了鲁棒且全局一致的三维重建。
一句话总结
来自 Google DeepMind 和加州大学伯克利分校的研究人员提出了 LoGeR,这是一种前馈模型,通过将测试时训练(Test-Time Training)用于全局一致性与滑动窗口注意力(Sliding Window Attention)用于局部精度相结合,将 3D 重建扩展至长视频,无需后优化即可在包含数千帧的数据集上实现卓越的精度。
主要贡献
- 目前的前馈几何模型由于注意力复杂度的二次方增长和内存限制,难以扩展到长达一分钟的视频,导致短窗口重建与长序列所需的全局一致性之间存在关键差距。
- LoGeR 引入了一种新颖的分块架构,配备混合记忆模块,该模块结合参数化测试时训练以锚定全局坐标系,并结合非参数化滑动窗口注意力以保持高精度的局部对齐。
- 该模型仅在 128 帧的序列上进行训练,却能泛化至数千帧,并通过将 KITTI 数据集上的绝对轨迹误差降低超过 74%,以及在新建的 19k 帧 VBR 基准测试上将结果提升 30.8%,实现了最先进(SOTA)的性能。
引言
大规模稠密 3D 重建对于从自动驾驶到生成式世界构建等应用至关重要,但现有方法难以在计算效率与长程一致性之间取得平衡。虽然经典优化流程可以处理城市级场景,但它们依赖缓慢的离线过程且无法处理稀疏输入;而现代前馈几何模型虽然速度快,却因注意力复杂度的二次方增长以及缺乏长序列训练数据,仅限于短小、有界的场景。为了弥合这一差距,作者提出了 LoGeR,这是一个前馈框架,利用混合记忆模块,结合非参数化滑动窗口注意力以获取高保真局部细节,并结合参数化关联记忆以维持全局结构完整性。这种方法使模型能够以线性计算成本处理长达 19,000 帧的庞大序列,有效克服了此前阻碍前馈模型扩展至现实世界长时程轨迹的上下文和数据瓶颈。
数据集
-
数据集构成与来源:作者利用了一个包含 14 个大规模数据集的多样化混合集,涵盖室内、室外及自动驾驶环境中的真实世界和合成场景,以支持长上下文几何重建。
-
各子集的关键细节:
- 导航和大规模场景数据集(如 TartanAirV2 和 VKITTI2)被赋予较高权重,以鼓励长程几何推理。
- DL3DV 因其卓越的真实世界场景多样性而获得高采样权重,有助于模型泛化。
- 较小或以物体为中心的数据集在混合集中被降低权重。
- OmniWorld-Game 的贡献仅限于基于训练时公开数据发布的 5,000 个序列子集。
-
数据使用与混合比例:训练配置采用相对采样百分比,如表 4 所示,该混合比例经过专门调整,以提供足够的长时程信号和多样化的场景先验。
-
处理与过滤策略:
- 所有数据集均标准化为多视图序列,包含 48 个视图(H200 GPU 训练时为 128 个视图),统一分辨率为 504 × 280。
- 采样策略遵循 CUT3R 方法。
- 应用严格的深度过滤以确保几何监督质量。
- 像 ARKitScenes 和 ScanNet 这样的度量尺度数据集使用最大深度阈值(例如 80.0 米),而像 DL3DV 和 TartanAir 等其他数据集则使用基于百分位的裁剪(例如第 90 或第 98 百分位)来屏蔽噪声或无效的深度值。
方法
作者提出了 LoGeR,这是一种新颖的架构,旨在将稠密 3D 重建扩展至极长视频序列,且无需后优化。为了克服全局注意力的二次方复杂度以及长时程训练数据的稀缺性,该方法按分块顺序处理视频流。这种方法在确保局部推理仍处于现有短上下文训练数据分布内的同时,严格限制了计算成本。
请参阅框架图以了解所提出的分块处理流程及其在长序列上的性能概览。
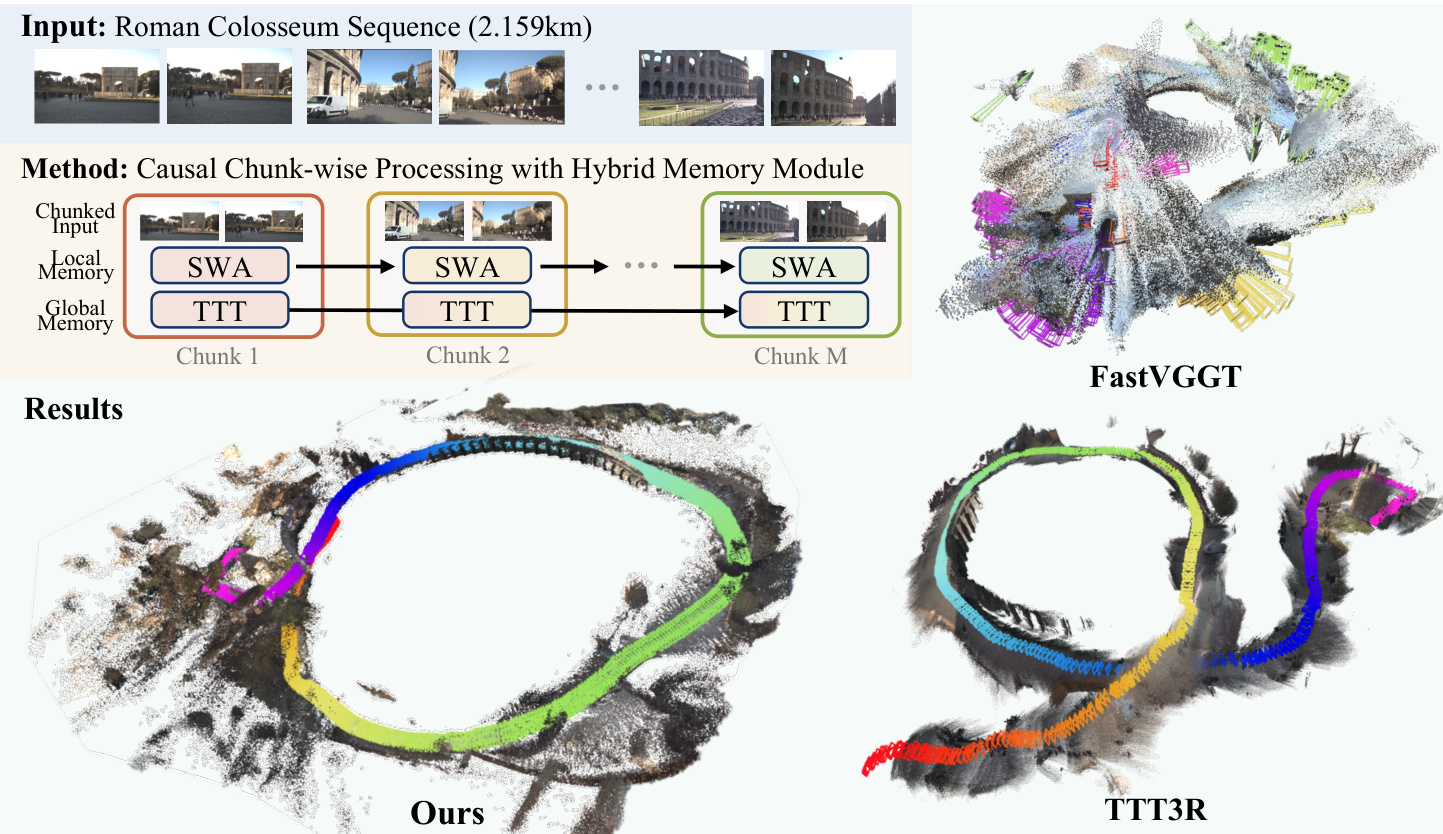
核心创新在于一个基于学习的混合记忆模块,用于管理分块边界之间的一致性。这个双组件系统结合了参数化测试时训练(TTT)记忆以锚定全局坐标系并防止尺度漂移,以及非参数化滑动窗口注意力(SWA)机制以保留未压缩的上下文,从而实现高精度的相邻对齐。
如下图所示,该架构按连续分块处理输入序列,针对第一个分块与后续分块利用特定机制以有效传播信息。
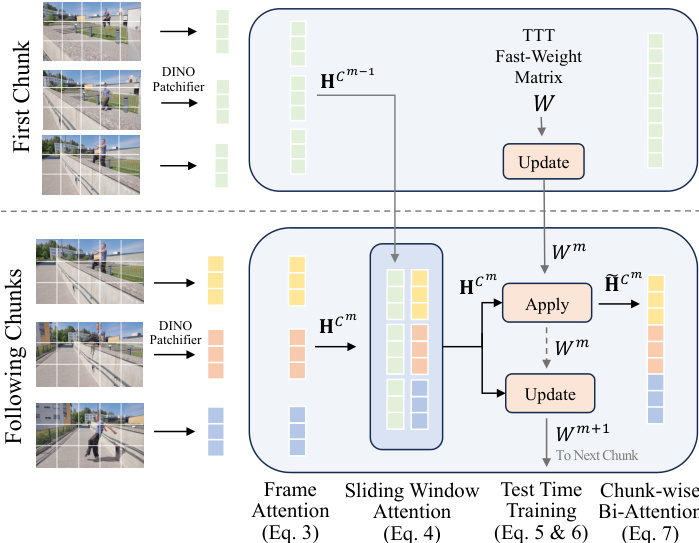
在几何骨干网络的每个残差块中,作者引入了混合记忆系统。该过程首先进行逐帧注意力计算,以独立提取每一帧的空间特征。为了对齐相邻分块,在网络深度的子集中插入了稀疏滑动窗口注意力层。这些层同时关注来自前一分块 Cm−1 和当前分块 Cm 的令牌,为高保真特征传播建立了一条无损信息高速公路。
为了整合全局上下文,模型维护一组快速权重 Wm,用于总结直到分块 m 的信息。TTT 层在分块级别执行“先应用后更新”的过程。在应用操作中,TTT 层利用权重中存储的历史信息来调节网络对当前分块的处理。在更新操作中,权重被编辑以存储来自当前分块的信息,从概念上压缩重要但冗余的几何信息。TTT 更新和应用操作的数学公式定义如下:
W←W−η∇WL(fW(k),v) Apply operation:o=fW(q)其中 η 是学习率,L 是鼓励函数 fW 将键与对应值关联的损失函数。最后,在每个分块内,采用双向注意力模块,在有限的上下文窗口下进行强大的几何推理。
在训练方面,作者采用渐进式课程策略以稳定循环 TTT 层的优化。训练计划从较短序列开始,并逐渐增加复杂度,迫使模型将依赖从局部滑动窗口注意力转移到全局 TTT 隐藏状态。此外,为了减轻极长流中的预测误差,一种名为 LoGeR* 的变体引入了纯前馈对齐步骤。该步骤通过计算分块之间重叠帧的刚性 SE(3) 变换,将原始预测对齐到一致的全局坐标系中。
实验
- 在 KITTI 和 VBR 基准测试上的长序列评估表明,LoGeR 有效缓解了数千帧范围内的累积漂移,在先前方法失效的情况下保持了全局尺度和轨迹一致性。
- 在 7-Scenes、ScanNet 和 TUM-Dynamics 上的短序列测试证实,所提出的模型和基线在 3D 重建和相机姿态估计方面显著优于现有的前馈和优化方法。
- 消融研究验证了混合架构的必要性,其中测试时训练层确保了全局一致性,而滑动窗口注意力层保持了局部几何平滑度。
- 关于数据混合和课程训练的实验证明,纳入大规模导航数据集和渐进式训练计划对于泛化以及稳定循环层优化至关重要。