Command Palette
Search for a command to run...
OCR 还是非 OCR?在 MLLMs 时代利用真实世界大规模数据集重新思考文档信息抽取
OCR 还是非 OCR?在 MLLMs 时代利用真实世界大规模数据集重新思考文档信息抽取
Jiyuan Shen Peiyue Yuan Atin Ghosh Yifan Mai Daniel Dahlmeier
摘要
多模态大语言模型(Multimodal Large Language Models, MLLMs)提升了自然语言处理的潜力。然而,它们在文档信息提取方面的实际影响尚不明确。特别是,目前尚不清楚仅采用 MLM 的 pipeline——尽管其更为简洁——是否能够真正达到传统“OCR + MLLM”组合的性能水平。在本文中,我们进行了一项大规模的 benchmarking 研究,旨在评估各种现成的(out-of-the-box)MLM 在商业文档信息提取任务中的表现。为了检测并探索失效模式(failure modes),我们提出了一种自动化的层级错误分析框架,利用 LLM 来系统性地诊断错误模式。我们的研究结果表明,对于强大的 MLM 而言,OCR 可能并非必要,因为仅凭图像输入即可达到与 OCR 增强方案相当的性能。此外,我们还证明了通过精心设计的 schema、exemplars 和 instructions 可以进一步提升 MLM 的性能。我们希望这项工作能为推进文档信息提取技术提供实践指导和宝贵的见解。
一句话总结
通过大规模基准测试研究和自动化分层错误分析框架,本研究评估了各种开箱即用的多模态大语言模型 (MLLMs) 在商业文档信息提取方面的表现,发现当利用优化的 schema、exemplars 和 instructions 时,仅图像的 pipeline 可以实现与传统 OCR 增强设置相当的性能。
核心贡献
- 本工作进行了一项大规模基准测试研究,评估了各种开箱即用的多模态大语言模型 (MLLMs) 在商业文档信息提取方面的表现,旨在将仅图像的 pipeline 与传统的 OCR 增强设置进行比较。
- 本文引入了一个自动化分层错误分析框架,利用大语言模型系统地诊断并发现文档提取任务中的错误模式。
- 研究表明,对于强大的 MLLMs,仅图像输入可以达到与 OCR 增强方法相当甚至更优的性能,并表明通过精心设计的 schema、exemplars 和 instructions 可以进一步提升性能。
引言
实现发票和财务报表等商业文档结构化信息的自动提取,对于简化企业工作流程至关重要。传统的行业 pipeline 通常依赖于一个复杂的两阶段框架,即先使用光学字符识别 (OCR),随后使用专门的提取模型,但这种方法容易产生错误传播,且难以在不同新领域之间进行泛化。研究人员进行了一项大规模基准测试研究,以评估多模态大语言模型 (MLLMs) 是否可以取代这些传统设置。研究提出了一种自动化分层错误分析框架,用以系统地诊断失败模式,并证明对于强大的 MLLMs,仅图像输入可以匹配甚至超越 OCR 增强 pipeline 的性能。
数据集
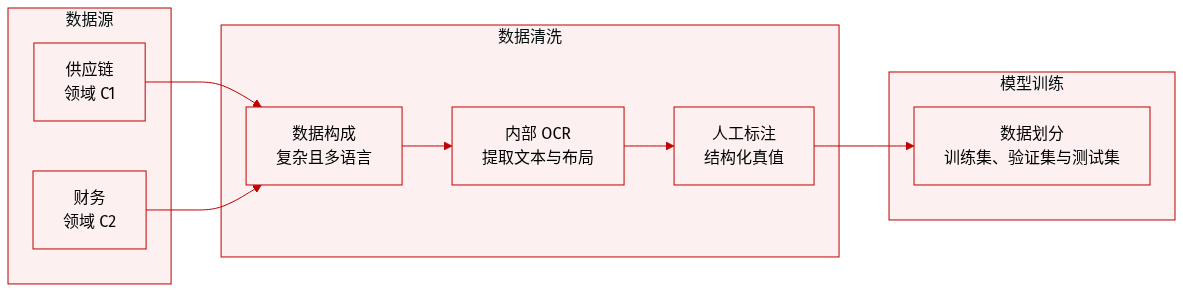
研究使用了专门设计的内部工业文档数据集,以应对现实世界商业文档的复杂性。数据集的组成和处理细节如下:
- 数据集组成与来源:数据集由两个主要子集组成:源自供应链领域的 C1,以及源自金融领域的 C2。
- 关键特征:与标准的开源数据集不同,该集合的特点是具有高结构复杂性和多语言内容。它包括包含嵌套信息、行项目内存在堆叠单元格以及异构表头结构的文档。
- 数据处理与 OCR:研究采用了专门为商业文档开发的专有内部 OCR 引擎。该引擎在多种语言中实现了超过 90% 的平均准确率,表现优于主要的机器学习平台服务。
- 元数据与布局保留:为了保持结构完整性,处理 pipeline 通过在提取的文本中保留空格作为结构分隔符来保留布局信息。
- Ground Truth 构建:每份文档除了 OCR 提取的文本结果外,还附带了人工标注、精心策划的结构化 ground truth 标签。
方法
研究提出了一种多阶段评估 pipeline 和一个分层错误分析框架,旨在系统地诊断和分类文档信息提取中的失败情况。
评估 pipeline 从 OCR 引擎开始,该引擎在提取文档图像文本内容的同时保留位置信息。对于仅关注图像输入的实验,该 OCR 步骤会被跳过。在随后的阶段,系统执行结构化信息提取。对于基于多模态大语言模型 (MLLM) 的方法,研究利用包含格式 instructions 和文档 schema 的 prompt template 来促进 zero-shot 提取。目标 schema 旨在捕获表头字段和代表结构化表格数据的行项目列表。MLLM 生成一个 JSON 对象,其中键表示实体类型,值包含提取的内容。最后,使用标准的 F1 score 对性能进行量化,该分数通过计算所有提取的键值对的 precision 和 recall 得出。
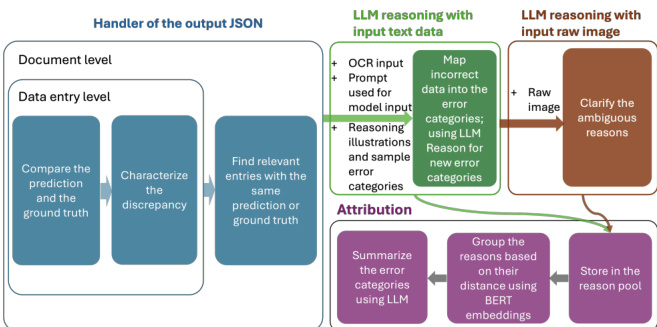
为了应对提取错误的复杂性,研究实现了一个分层错误分析框架。如框架图所示,该过程通过三个不同的模块从初始错误检测演进到高级归因:Handler、LLM Reasoning 和 Attribution。
该过程由自动化错误处理器 (Handler) 启动。该模块在字符级和语义级将预测值与 ground-truth 值进行比较。Handler 在字段级和文档级运行,执行三个主要任务:将预测值与 ground truth 进行比较、描述差异的性质,以及识别具有相似预测或 ground-truth 值的相关条目以便进行更深入的调查。
在 Handler 之后,LLM reasoning 模块细化错误分类。此阶段采用 LLMs 和 MLLMs 来生成结构化的诊断报告,而不是依赖人工分析。推理过程涉及两个步骤。首先,LLMs 使用 OCR 结果、预测值和 ground-truth 标签等文本输入,将错误的预测映射到预定义的错误类别中。其次,为了解决由布局复杂性或视觉细微差别引起的歧义,系统引入原始文档图像作为额外输入以澄清推理。这种双模态方法允许模型在必要时从文本推理过渡到视觉推理。
最后一个阶段是归因 (Attribution) 模块,用于识别最高层级的失败来源。研究通过将分类后的原因存储在结构化的原因池中,对 LLM 生成的解释进行后处理。为了确保分类的一致性,研究应用基于 BERT 的 embedding 聚类,根据余弦相似度对相似原因进行分组。随后为每个簇提取代表性关键词。这使得框架能够确定错误是源于特定的根本原因,例如 OCR 误识别、布局误解、prompt 失配、模型能力限制或 schema 不一致。
实验
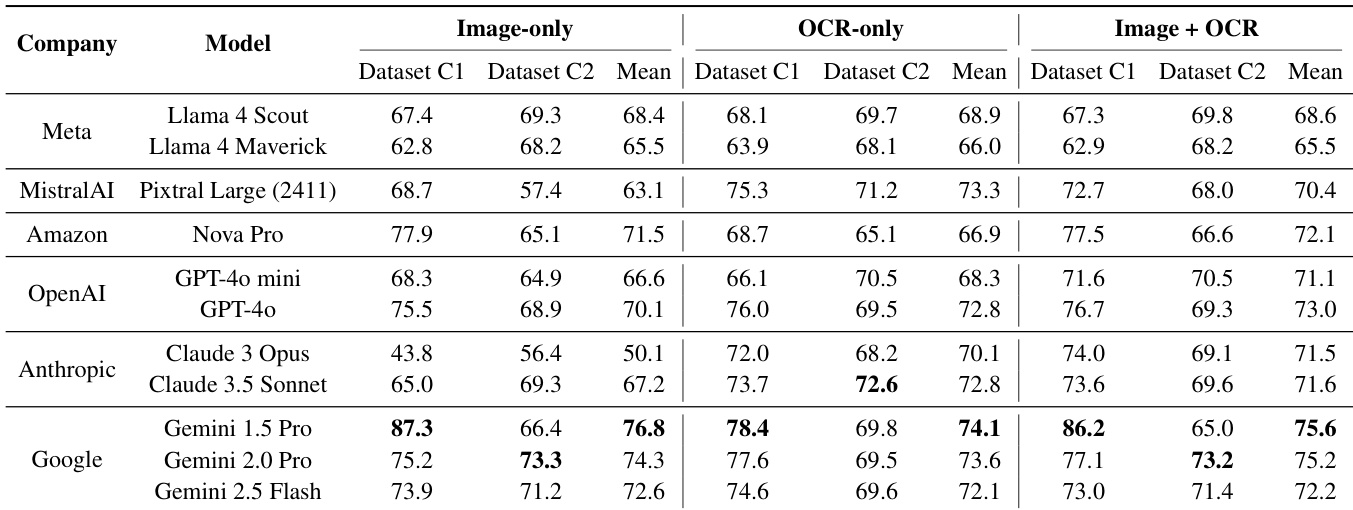
本研究使用三种输入模态:仅图像、仅 OCR 以及两者的结合,评估了最先进的多模态大语言模型 (MLLMs) 在商业文档信息提取方面的表现。实验表明,虽然结合模态可以稳定性能,但先进模型越来越具备直接从图像中进行信息提取的能力,而无需依赖 OCR。此外,研究结果表明,通过减少 schema 歧义并利用视觉编码器固有的布局理解能力,优化的仅图像方法可以超越传统方法。
研究提供了几种闭源多模态大语言模型的推理延迟和每页成本估算。结果显示,不同模型提供商在速度和费用方面表现出多种性能特征。与基准测试中的其他模型相比,Gemini 2.5 Flash 等模型表现出更低的延迟和更低的成本。速度与费用之间存在明显的权衡,一些高性能模型每页所需的成本显著更高。评估的模型之间延迟差异很大,从极快的响应到每页几秒钟不等。

研究比较了各种多模态大语言模型在三种输入模态下的性能:仅图像、仅 OCR 以及两者的结合。结果表明,虽然仅 OCR 输入提供了相对稳定的性能,但对于许多旗舰模型,结合图像和 OCR 输入可以带来更稳健的预测。来自 Google 的旗舰模型在仅图像设置中表现出高性能,有时甚至在没有显式 OCR 文本的情况下表现更好。与使用仅图像输入相比,结合图像和 OCR 输入往往能降低性能波动。某些模型在从仅 OCR 转换为多模态输入时表现出性能下降,这表明在整合视觉和文本信息方面可能存在困难。
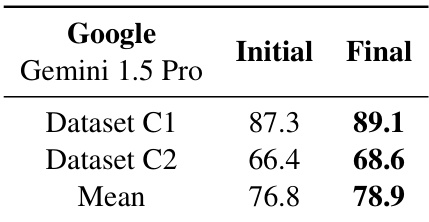
研究使用优化的 prompt template 配合仅图像输入,评估了 Gemini 1.5 Pro 的性能。结果显示,应用这些改进在两个测试的商业文档数据集中都带来了性能提升。优化的 prompt template 提高了 Dataset C1 和 Dataset C2 的性能。应用改进后的 prompt 策略后,平均性能有所提升。结果证明了在结合增强的 instructions 和 schema 调整时,仅图像方法的有效性。
研究通过分析不同输入模态下的推理延迟、成本效率和性能,评估了闭源多模态大语言模型。实验揭示了不同提供商之间在速度和费用之间的显著权衡,并表明结合图像和 OCR 输入通常可以增强预测的稳健性,尽管某些模型在有效整合这些模态方面存在困难。此外,针对仅图像输入优化 prompt template 可以成功提高在商业文档数据集上的性能。