Command Palette
Search for a command to run...
HiFi-Inpaint:面向高保真参考式图像修复以生成细节保留的人 - 物图像
HiFi-Inpaint:面向高保真参考式图像修复以生成细节保留的人 - 物图像
摘要
人机融合图像通过展示人与产品的有机结合,在广告、电子商务及数字营销领域发挥着至关重要的作用。生成此类图像的核心挑战在于如何高保真地保留产品细节。在现有方法中,基于参考的图像修复(reference-based inpainting)通过利用产品参考图像引导修复过程,提供了一种针对性的解决方案。然而,该方法在以下三个方面仍存在局限:缺乏多样化且大规模的训练数据、现有模型难以聚焦于产品细节的保留,以及粗粒度监督机制无法实现精确引导。针对上述问题,本文提出 HiFi-Inpaint——一种专为生成人机融合图像而设计的高保真参考式图像修复新框架。HiFi-Inpaint 引入了共享增强注意力机制(Shared Enhancement Attention, SEA)以细化细粒度产品特征,并设计了细节感知损失函数(Detail-Aware Loss, DAL),利用高频图实现精确的像素级监督。此外,我们构建了一个名为 HP-Image-40K 的新数据集,其样本源自自合成数据,并经过自动过滤处理。实验结果表明,HiFi-Inpaint 取得了最先进的性能,能够生成细节保留优异的人机融合图像。
一句话总结
来自中国科学院大学(UCAS)、香港中文大学(CUHK)和字节跳动的研究人员提出了 HiFi-Inpaint,这是一个用于生成高保真人物 - 产品图像的高保真框架。通过引入共享增强注意力(Shared Enhancement Attention)和细节感知损失(Detail-Aware Loss),该方法克服了以往在细节保留方面的局限性,并利用新构建的数据集在电商和广告应用中实现了最先进的成果。
主要贡献
- 提出的 HiFi-Inpaint 框架引入了共享增强注意力以细化细粒度特征,并采用细节感知损失,利用高频图实施像素级监督。
- 作者构建了一个名为 HP-Image-40K 的新数据集,包含超过 40,000 个精心策划的样本,并证明该方法在生成保留细节的人物 - 产品图像方面达到了最先进的性能。
- 实验结果表明,HiFi-Inpaint 取得了最先进的性能,能够生成细节保留优异的人机融合图像。
引言
人物 - 产品图像生成对于广告和电子商务至关重要,因为将产品无缝集成到场景中同时保留纹理和品牌等细粒度细节的能力,直接影响消费者的信任度。现有的基于参考的图像修复方法难以应对这一任务,因为它们缺乏多样化的大规模训练数据,无法聚焦于特定的产品细节,并且依赖粗糙的监督,导致生成幻觉内容或平均化内容。为了克服这些障碍,作者引入了 HiFi-Inpaint,这是一个利用共享增强注意力来细化细粒度特征,并通过高频图实施精确像素级监督的框架。此外,他们还贡献了一个名为 HP-Image-40K 的新数据集以支持鲁棒的模型训练,在生成高保真人物 - 产品图像方面取得了最先进的成果。
数据集
-
数据集构成与来源 作者构建了两个主要数据集:合成数据集 HP-Image-40K 和一个内部真实世界数据集。HP-Image-40K 是使用预训练的文本到图像模型生成的,以克服数据稀缺问题;而真实世界数据集则从公开可用的互联网图像中精心策划,以确保现实世界的多样性。
-
每个子集的关键细节
- HP-Image-40K:包含超过 40,000 个高质量样本,涵盖瓶子、罐子和管状物等多样化的产品类别。数据覆盖了广泛的掩码面积比例,用于训练模型以适应不同尺度和空间分布的物体。
- 真实世界数据集:包含约 14,000 个训练样本和一个独立的 2,000 个样本的测试集。与合成数据相比,该子集表现出更高的复杂性,具有多变的光照、姿态、遮挡和背景杂乱。
-
数据使用与训练策略 作者利用 14,000 个真实世界样本与合成 HP-Image-40K 一起进行模型训练,以增强泛化能力。2,000 个真实世界样本专门保留用于评估,以测试模型在非受控环境下的鲁棒性。合成数据由于其与任务定义的良好控制对齐,作为主要的训练来源。
-
处理与构建细节
- 合成流程:作者使用 FLUX.1-Dev 生成双联画图像,左侧为产品,右侧为人物 - 产品场景,由特定的提示模板引导。
- 分割:使用 Sobel 滤波器检测垂直边缘,将双联画分割为单独的产品图像和人物 - 产品图像。
- 过滤机制:团队应用基于 YOLOv8 和 CLIP 的语义过滤,以确保配对之间的产品一致性。通过 InternVL 进行的文本过滤比较提取的文本字符串,以保证品牌和标签的保真度。
- 样本格式化:每个最终样本包括文本提示、掩码后的人物图像、产品图像和真实人物 - 产品图像。掩码是通过检测并掩码人物图像中的产品区域生成的。
- 预处理:真实世界图像在分辨率和宽高比方面与合成数据对齐,以维持公平的比较协议。
方法
作者提出了 HiFi-Inpaint,这是一个高保真的基于参考的图像修复框架,旨在生成无缝的人物 - 产品图像。该系统接收简洁的文本提示 T、掩码后的人物图像 Ih 和产品参考图像 Ip 作为输入,生成图像 Ig,将产品集成到掩码区域中,同时遵循文本描述。整体流程涵盖数据集构建、高频图引导的 DiT 架构以及专门的训练策略。
参考下方的框架图以全面了解系统组件和数据流。
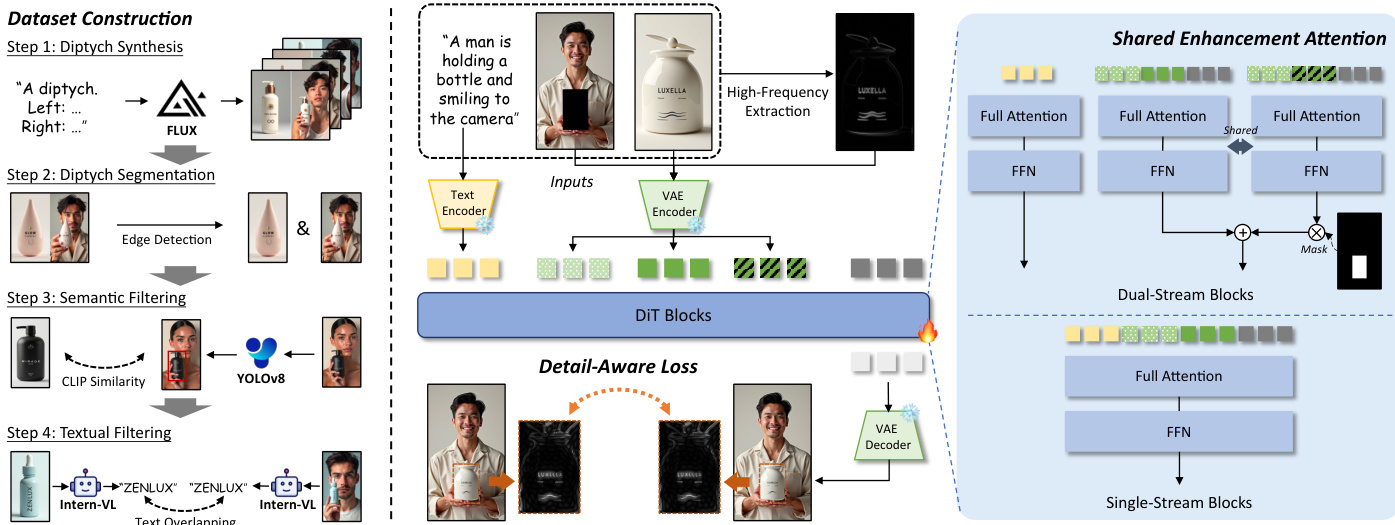
数据集构建 为了支持模型训练,作者精心策划了一个名为 HP-Image-40K 的大规模数据集。如图中左侧部分所示,该过程涉及四个步骤。首先,使用预训练的文本到图像模型进行双联画合成,以创建配对图像。其次,双联画分割利用边缘检测分离人物和产品组件。第三,语义过滤采用 CLIP 相似度和 YOLOv8 以确保视觉相关性。最后,文本过滤使用 Intern-VL 验证文本一致性并防止文本重叠问题。
高频图引导的 DiT 核心架构基于 FLUX.1-Dev 模型构建,该模型利用多模态扩散 Transformer(MMDiT)。作者引入了一种令牌合并机制以有效地注入条件。文本令牌从提示中编码,而视觉令牌则源自掩码后的人物图像、产品图像和带噪声的真实值。这些被连接起来形成联合视觉令牌 z0:
z0=Concat(E(Ih),E(Ip),N(E(Igt),t))其中 E(⋅) 表示 VAE 图像编码器,N(⋅,t) 表示在时间步 t 添加噪声。为了增强细节保留,使用离散傅里叶变换(DFT)和高通滤波器从产品图像中提取高频图。这生成了单独的高频视觉令牌序列 z0′:
z0′=Concat(E(Ih),E(H(Ip)),N(E(Igt),t))其中 H(⋅) 表示高频提取过程。
共享增强注意力 为了细化掩码区域内的视觉特征,作者引入了共享增强注意力(SEA)。如图中右侧部分详述,该模块在双流视觉 DiT 块内运行。SEA 为标准处理分支补充了一个用于高频视觉令牌的额外分支,该分支共享相同的参数。对于第 i 个双流块 Bi(⋅),更新规则被修改以纳入高频信息:
zi=Bi(zi−1)+αi⋅Mask(Bi(zi−1′),Mds)这里,αi 是一个可学习的加权因子,允许模型将高频细节与全局上下文和谐地融合。掩码操作 Mask(⋅,Mds) 确保增强仅应用于相关的下采样掩码区域,防止来自图像其他部分的干扰。
细节感知训练策略 训练过程使用细节感知损失(DAL)进行优化,以提供精确的像素级监督。如图中底部中心所示,该损失函数针对掩码区域内的高频分量。其公式化为:
LDA=H(I^gt)⊙M−H(Igt)⊙M22其中 I^gt 是预测图像,Igt 是真实值,M 是掩码。这与标准的潜在级 MSE 损失 LMSE 相结合,以确保全局一致性。总体损失函数定义为:
LOverall=LMSE+LDA这种组合方法确保模型在全局语义连贯性和复杂产品细节保留之间取得平衡。
实验
- 与四种基于参考的图像修复方法的定量和定性比较表明,HiFi-Inpaint 在文本对齐、视觉一致性和整体图像质量方面实现了最先进的性能,特别是在保留文本和徽标等细粒度产品细节方面。
- 用户研究证实,与现有基线相比,所提出的方法在文本对齐、视觉一致性和生成质量方面更符合人类偏好。
- 消融研究验证了合成 HP-Image-40K 数据集、共享增强注意力机制和细节感知损失都是关键组件,显著提高了细节保留和视觉保真度。
- 在真实世界数据和具有挑战性的泛化场景上的评估表明,即使在复杂的光照、姿态变化和多样的环境条件下,该模型仍能保持鲁棒性和高保真的产品集成。