Command Palette
Search for a command to run...
视觉如何转化为文本:定位 Vision-Language Models 中的 OCR Routing 瓶颈
视觉如何转化为文本:定位 Vision-Language Models 中的 OCR Routing 瓶颈
Jonathan Steinberg Oren Gal
摘要
视觉语言模型(Vision-language models, VLMs)能够从图像中读取文本,但这种光学字符识别(OCR)信息究竟是在何处进入语言处理流的?我们通过对 2B–8B 参数规模下的五个稠密模型进行因果干预(causal interventions),研究了三种架构家族(Qwen2-VL、Phi-4、InternVL2.5)中的 OCR 路由机制。通过计算原始图像与文本修复版本(text-inpainted versions)之间的激活差异(activation differences),我们识别出了具有架构特性的 OCR 深度区间(depth bands),其主导位置取决于视觉与语言的集成策略:DeepStack 模型(如 Qwen)在处理场景文本时,其敏感度峰值出现在中层(约 50%);而单阶段投影模型(single-stage projection models,如 Phi-4、InternVL)的敏感度峰值则出现在早期层(6–25%),尽管最大效应的具体层数会随数据集的变化而波动。研究发现,OCR 信号具有极低的维度:第一主成分(PC1)捕捉了 72.9% 的方差。至关重要的一点是,在某一数据集上学习到的主成分分析(PCA)方向可以迁移到其他数据集,这证明了模型内部存在共享的文本处理路径。令人惊讶的是,在具有模块化 OCR 电路(modular OCR circuits)的模型中(尤其是 Qwen2-VL-4B),移除 OCR 信息反而能提升计数任务的性能(提升高达 6.9 个百分点),这表明在这一参数规模范围内,对于具有足够模块化架构的模型而言,OCR 信息可能会干扰其他的视觉处理过程。
一句话总结
通过对 Qwen3-VL、Phi-4 和 InternVL3.5 应用因果干预和主成分分析,研究人员识别出了特定架构的 OCR 路由深度带,揭示了单阶段投影模型在比 DeepStack 架构更早的层处理文本信号,并且模块化 OCR 电路偶尔会干扰视觉计数性能。
核心贡献
- 本文通过使用因果干预和激活修补(activation patching)来定位 2B–8B 参数规模视觉语言模型中处理文本信息的深度带,从而识别出特定架构的 OCR 路由机制。
- 研究表明 OCR 信号集中在一个低维子空间中,其中主成分捕获了 72.9% 的方差,并表现出跨不同数据集的可迁移特性。
- 研究显示,通过手术式地移除该 OCR 特定子空间可以提高其他视觉任务(如计数)的性能,这表明在模块化架构中,OCR 与其他视觉处理功能之间存在能力竞争。
引言
视觉语言模型 (VLMs) 依赖光学字符识别 (OCR) 来解释图像中的文本,这一能力对于从文档理解到自主网络浏览等任务至关重要。虽然这些模型表现出强大的文本读取性能,但将视觉文本转换为语言处理流的内部路由机制仍不为人所知。这种缺乏清晰度的现象带来了显著的安全风险,因为嵌入在图像中的对抗性文本可以通过排版提示注入(typographic prompt injections)来劫持模型行为。研究人员利用因果干预和主成分分析 (PCA) 来识别处理 OCR 信息的特定架构深度带。研究证明 OCR 信号具有显著的低维特性,且其处理路径在不同数据集之间保持一致。此外,研究表明,手术式地移除该 OCR 子空间实际上可以提高计数等非文本任务的性能,这表明在某些模型架构中,OCR 电路可能会干扰其他视觉推理过程。
数据集
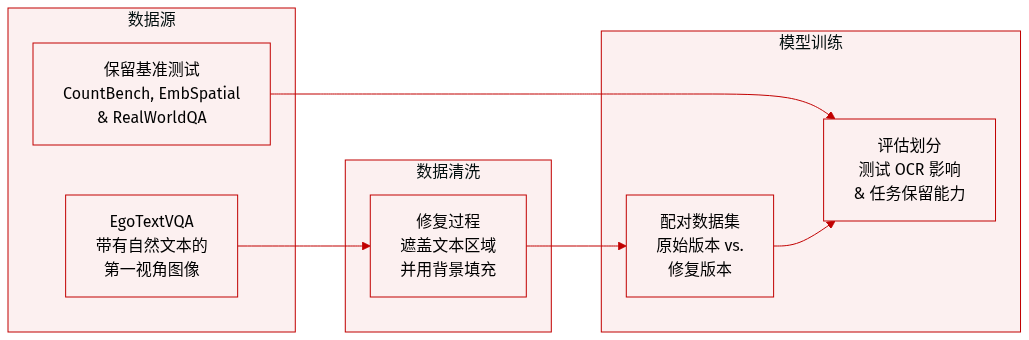
研究人员利用多个数据集来评估 OCR 干预对视觉模型的影响:
- EgoTextVQA (主要数据集): 使用该第一人称视角数据集,其特征是包含自然文本(如标志、标签和屏幕)的图像。为了研究文本如何影响模型激活,创建了一个由原始图像和经过修复(inpainted)且移除了文本的版本组成的配对数据集。
- 修复处理 (Inpainting Processing): 为了生成修复版本,从现有标注中提取文本区域边界框,并将其扩大 10% 以确保完全覆盖。然后应用标准的修复模型来填充这些掩码区域。该过程的质量通过对 50 个随机样本进行人工抽检得到了验证。
- 保留基准 (Retention Benchmarks): 为了衡量对非 OCR 任务的附带损害,使用了三个特定的基准测试,采用完整数据集和确定性贪婪解码:
- CountBench: 用于衡量物体计数能力的基准。
- EmbSpatial: 旨在测试具身任务空间推理和理解能力的基准。
- RealWorldQA: 基于真实世界图像的通用视觉问答基准。
方法
为了调查视觉语言集成如何影响 OCR 路由,研究人员检查了三种不同的视觉语言模型 (VLMs) 架构家族。第一类由 DeepStack 模型组成,包括 Qwen3-VL-4B-Instruct、Qwen3-VL-2B-Instruct 和 Qwen3-VL-8B-Instruct。这些模型采用渐进式注入策略,将视觉特征引入大语言模型 (LLM) 主干的多个层中。相比之下,第二类包含单阶段模型,如 Phi-4-multimodal-instruct 和 InternVL3.5-4B。这些架构仅在输入层注入所有视觉 tokens。这种集成策略的差异有助于识别 OCR 瓶颈是如何分布在模型各层中的。
如下图所示:
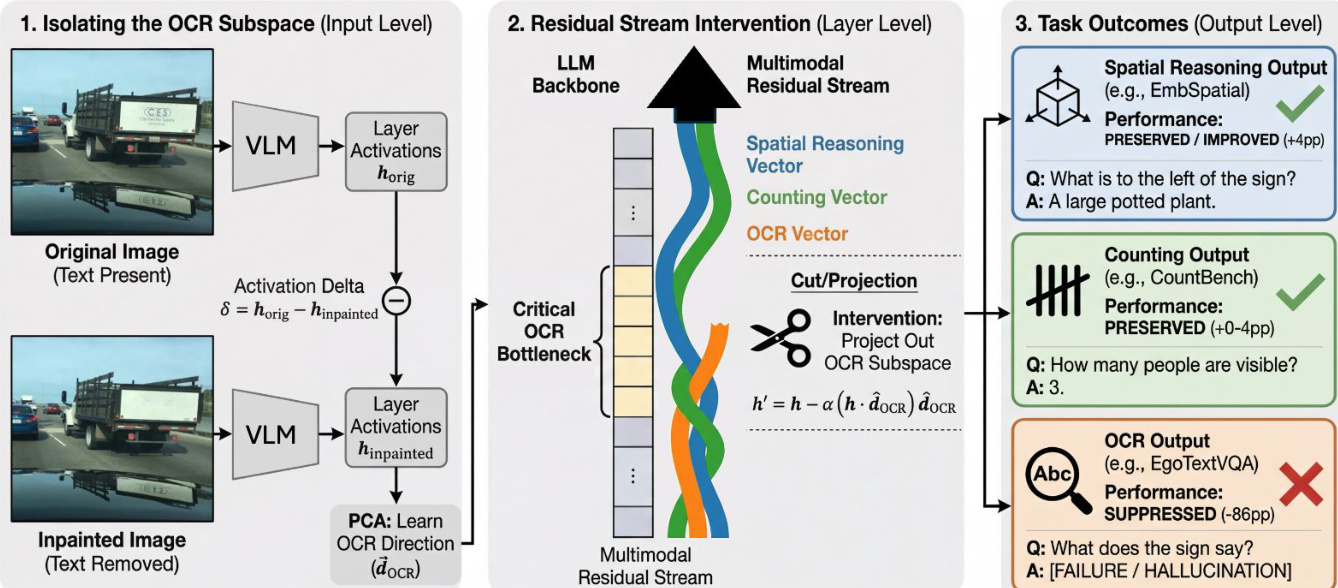
研究人员采用基于 PCA 的子空间移除方法来隔离负责文本处理的残差流组件。对于每一层 ℓ,使用以下公式在留出训练集上计算激活差异: Δhℓ=hℓoriginal−hℓinpainted 其中 hℓoriginal 代表包含文本的图像的激活,hℓinpainted 代表移除文本后的图像的激活。通过对这些差异进行主成分分析 (PCA),研究人员识别出了捕获文本存在时发生的特定变化的成分。
在推理过程中,通过从残差流中投影掉前 N 个主成分来进行干预。干预后的激活 hℓint 计算如下: \nhℓint=hℓ−α∑i=1N(hℓ⋅pci)pci 在该方程中,hℓ 是第 ℓ 层的残差流激活,pci 是第 i 个主成分,N 是移除的成分数量,α 是干预强度的缩放因子。研究人员设置 α=1 以实现完全投影移除。这些干预通过在 transformer 层输出上设置前向钩子(forward hooks)来实现,专门针对 post-MLP 残差流。
作为子空间移除的补充,研究人员还进行了注意力头消融(head ablation),以识别专门用于 OCR 的注意力头。为每个注意力头定义了一个选择性比例,计算为分配给 OCR 区域的注意力权重与分配给背景区域的权重之比。比例大于 1.0 的头被认为优先关注文本。研究人员根据此选择性对所有 720 个头进行排序,并在 prefill 和 decode 阶段通过将前 N 个头的输出投影置零来进行消融,以评估它们对文本阅读任务的因果重要性。
实验
研究人员在多个 OCR 和视觉推理基准测试中评估了五种视觉语言模型,以识别并干预文本处理瓶颈。实验表明,OCR 信号集中在低维子空间中,且这些瓶颈的位置由模型架构决定:DeepStack 模型表现出中层敏感性,而单阶段模型表现出早期层敏感性。结果表明,有针对性的 OCR 移除可以通过减少表示干扰来实际提高某些视觉任务(如物体计数)的性能,特别是在表现出更多模块化电路组织的较大模型中。
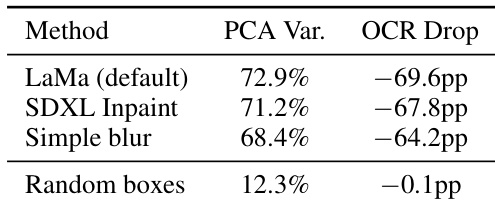
研究人员进行了对照实验,以确保观察到的 OCR 抑制源于实际的文本移除,而非修复过程引入的伪影。通过将三种不同的修复方法与随机框基准进行对比,验证了基于 PCA 干预的特异性。不同的修复技术产生相似的解释方差和 OCR 抑制水平。随机框对照显示对方差和 OCR 准确性的影响极小。结果证实,识别出的信号是针对文本移除的,而非通用的图像扰动。
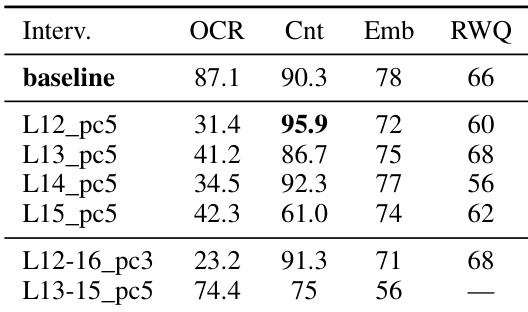
研究人员在 Qwen3-VL-2B 模型上评估了不同的逐层干预,以观察对 OCR 和视觉推理任务的影响。结果显示,网络中部的干预可以抑制 OCR,同时提高计数等某些视觉任务的性能。在特定中层的干预实现了显著的 OCR 抑制,同时提高了计数准确率。某些干预提供了权衡方案,即计数性能提高但空间推理和通用视觉 QA 分数下降。多层干预可以有效减少 OCR,但对下游视觉推理任务的影响各异。
研究人员通过根据选择性比例进行排序,识别出了最具 OCR 选择性的注意力头。这些头主要集中在特定的网络中层。最具选择性的头位于第 16、18、8、12 和 17 层。排名靠前的头的选择性比例范围大约在 1.10 到 1.41 之间。在第 16 层到第 20 层之间的中层范围内发现了一个显著的高选择性头集群。
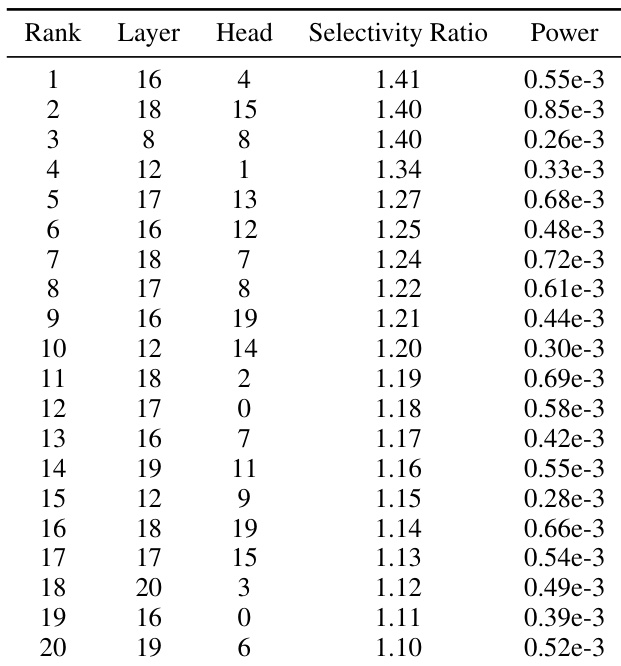
研究人员评估了针对性的 OCR 干预如何影响不同模型架构中的各种视觉推理任务。结果显示,虽然某些模型在提高计数任务性能的同时对其他指标影响极小,但其他模型在空间推理和通用视觉 QA 方面经历了显著退化。Qwen3-VL-4B 通过提高计数性能,且仅对空间推理和通用视觉 QA 产生轻微影响,实现了良好的权衡。较小的模型如 Qwen3-VL-2B 和 Phi-4 在计数方面有所提升,但在空间推理和通用视觉任务中出现了明显的下降。当对 InternVL 的早期层瓶颈应用干预时,所有测量的指标均表现出完全退化。
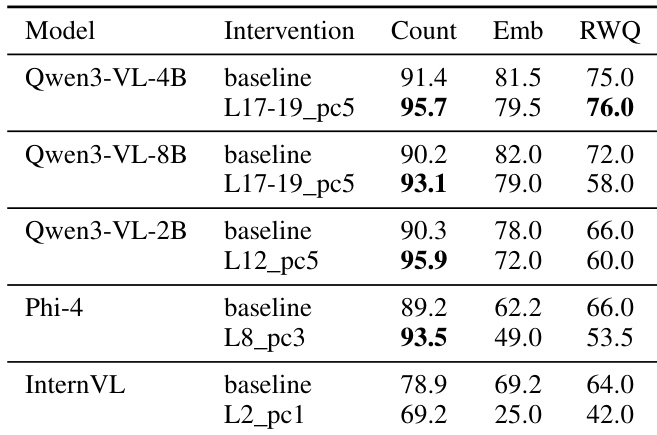
研究人员在 Qwen3-VL-4B 模型上评估了不同的基于 PCA 的干预,以识别用于 OCR 抑制的最佳层。结果显示,针对特定的中层组件可以提高物体计数性能,同时保持或轻微调整其他视觉推理能力。在第 17 层至第 19 层的多层干预通过提高计数和通用视觉 QA,同时对空间推理的影响极小,实现了良好的平衡。在第 18 层的单层干预导致通用视觉 QA 性能显著崩溃。某些中层干预(如 pca_L17_pc5)通过提高计数准确率并保留大部分其他指标,展示了有效的权衡。
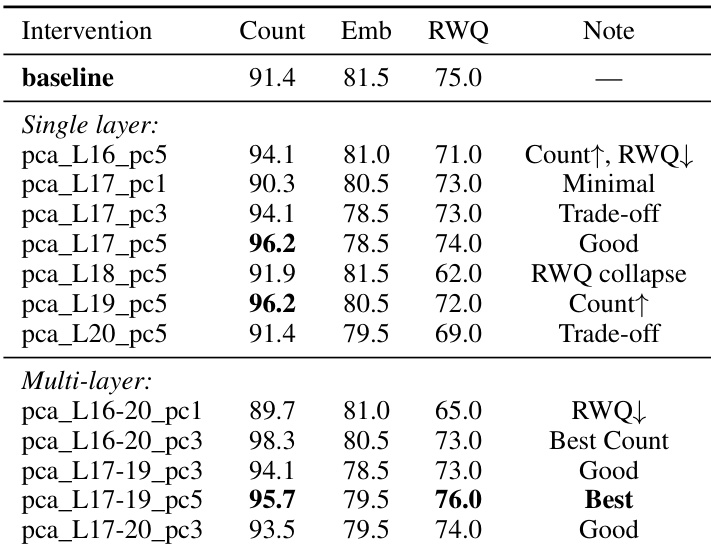
研究人员进行了对照实验和逐层干预,以验证基于 PCA 的方法是专门抑制 OCR,而非由通用图像扰动引起。通过识别网络中层的高度选择性注意力头,证明了针对性干预可以抑制文本识别,同时可能提高计数等某些视觉任务。这些干预的有效性随架构而异,一些模型在 OCR 抑制和推理能力之间实现了良好的平衡,而另一些模型则经历了性能权衡。