Command Palette
Search for a command to run...
WAXAL:大规模多语言非洲语言语音语料库
WAXAL:大规模多语言非洲语言语音语料库
摘要
语音技术的进步主要惠及高资源语言,导致绝大多数撒哈拉以南非洲语言的使用者面临严重的数字鸿沟。为弥补这一差距,我们推出了 WAXAL——一个面向 24 种语言、覆盖超 1 亿使用者的大规模开源语音数据集。该数据集包含两大核心组成部分:一是自动语音识别(ASR)数据集,收录了来自多样化说话群体的约 1,250 小时经转写的自然语音;二是文本转语音(TTS)数据集,包含超过 235 小时的高质量单人录音,内容基于音素平衡的脚本朗读而成。本文详细阐述了数据采集、标注及质量控制的方法论,该过程与四家非洲学术及社区组织建立了合作伙伴关系。我们提供了该数据集的详细统计概览,并讨论了其潜在的局限性与伦理考量。WAXAL 数据集已在 https://huggingface.co/datasets/google/WaxalNLP 发布,采用宽松的 CC-BY-4.0 许可协议,旨在推动相关研究、促进包容性技术的开发,并为这些语言的数字化保存提供关键资源。
一句话总结
为了解决撒哈拉以南非洲语言面临的巨大数字鸿沟,WAXAL 提供了一个大规模、开放可访问的语音语料库,涵盖 24 种语言,代表超过 1 亿使用者。该语料库包含约 1,250 小时用于自动语音识别(ASR)的转录自然语音,以及超过 235 小时用于文本转语音(TTS)的高质量单人录音,内容为阅读语音平衡脚本。该项目与四家非洲学术和社区组织合作开发,并在 CC-BY-4.0 许可下发布,以促进研究、推动包容性技术发展并支持数字保存。
核心贡献
- 我们介绍了 WAXAL,一个涵盖 24 种撒哈拉以南非洲语言的大规模语音数据集,代表超过 1 亿使用者。该集合包含一个自动语音识别(ASR)数据集,约有 1,250 小时转录自然语音,以及一个文本转语音(TTS)数据集,拥有超过 235 小时的高质量录音。
- 我们详细说明了通过四家非洲学术和社区组织合作建立的数据收集、标注和质量控制方法。此过程支持纳入多样化的说话者,并为生成的语音资源保持质量控制标准。
- 数据集发布在 https://huggingface.co/datasets/google/WaxalNLP,采用宽松的 CC-BY-4.0 许可,以促进研究并推动包容性技术的发展。我们提供了数据集的详细统计概览,并讨论了其潜在限制和伦理考量。
引言
自动语音识别系统通常缺乏针对非洲语言足够的训练数据,这限制了这些地区的技术可访问性和包容性。现有数据集通常无法提供在整个大陆实现稳健模型性能所需规模或多语言多样性。作者介绍了 WAXAL,一个旨在解决这一资源缺口的大规模多语言非洲语言语音语料库。他们还强调,发布任何大规模人类数据都需要仔细考虑其局限性和伦理影响。
数据集
-
数据集组成和来源
- 作者介绍了 WAXAL,一个涵盖 24 种由超过 1 亿人使用的撒哈拉以南非洲语言的大规模语音数据集。
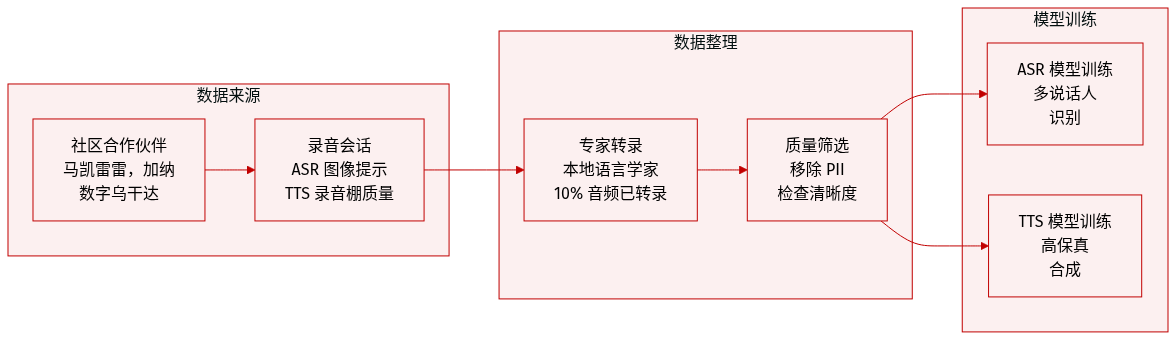
- 收集工作与四家非洲学术和社区组织合作进行,例如 Makerere University 和 University of Ghana。
- 整个集合在 CC-BY-4.0 许可下发布,以鼓励学术和商业研究。
-
每个子集的关键细节
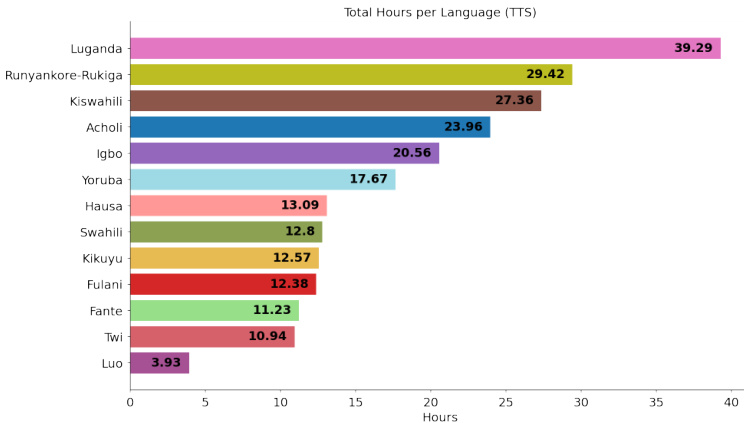
- ASR 子集: 包括 14 种语言中约 1,250 小时的转录自然语音。录音采用图像提示以捕捉自发语音,最短持续时间为 15 秒。
- TTS 子集: 包含来自 10 种语言中 72 位配音演员的超过 180 小时录音室质量录音。说话者在专业环境中阅读语音平衡脚本。
- 文件统计: 发布的 ASR 数据占用 1.7 TB,而 TTS 数据总计 99 GB。
-
数据使用和处理
- 预期用途: ASR 数据适用于训练和评估多说话者识别模型,而 TTS 数据专为高保真语音合成设计。
- 标注策略: 转录由当地语言专家使用当地脚本或英文音译创建。发布的转录内容仅占总收集音频的 10%。
- 元数据构建: 数据集包括说话者人口统计信息,如年龄、性别和录音环境(例如,室内、室外)。
- 质量控制: 作者移除了个人身份信息,并筛选了音频的清晰度、语言准确性和适当内容。