Command Palette
Search for a command to run...
UniReason 1.0:面向世界知识对齐的图像生成与编辑的统一推理框架
UniReason 1.0:面向世界知识对齐的图像生成与编辑的统一推理框架
摘要
统一的多模态模型在处理需要深度推理的复杂生成任务时往往表现不佳,且通常将文本到图像生成与图像编辑视为相互独立的能力,而非相互关联的推理步骤。为解决这一问题,我们提出UniReason——一种通过双推理范式统一整合这两项任务的统一框架。我们将生成过程建模为增强世界知识的规划,以引入隐式约束;同时利用图像编辑能力实现细粒度的视觉优化,通过自我反思进一步修正视觉错误。该方法在共享表示空间中统一了生成与编辑,模拟了人类认知中“先规划、后修正”的思维过程。为支撑该框架,我们系统性地构建了一个大规模、以推理为核心的基准数据集(约30万样本),涵盖五大核心知识领域(如文化常识、物理规律等)用于规划任务,并引入由智能体生成的语料库以支持视觉层面的自我修正。大量实验表明,UniReason在多个高推理强度的基准测试(如WISE、KrisBench和UniREditBench)中均达到先进水平,同时保持了卓越的通用合成能力。
一句话总结
复旦大学与上海创新研究院的研究人员提出了 UniReason,这是一种统一框架,通过双重推理——结合世界知识进行规划与自我反思式优化——将文生图生成与图像编辑融为一体,在推理基准测试中超越先前模型,同时实现跨领域连贯且纠错的视觉合成。
主要贡献
- UniReason 引入了一个统一框架,将文生图生成与图像编辑视为相互关联的推理步骤,利用共享表征模拟人类的规划与优化过程,从而弥合抽象意图与忠实视觉输出之间的差距。
- 该框架结合了增强世界知识的文本推理(在生成前注入隐式约束)与基于自我反思的细粒度视觉优化(在生成后进行),实现迭代修正,并促进合成与编辑任务间的相互能力迁移。
- 该框架依托一个大规模推理数据集(约 30 万样本),涵盖五个知识领域及代理生成的自我修正语料,在 WISE、KrisBench 和 UniREditBench 等基准测试中达到最先进水平。
引言
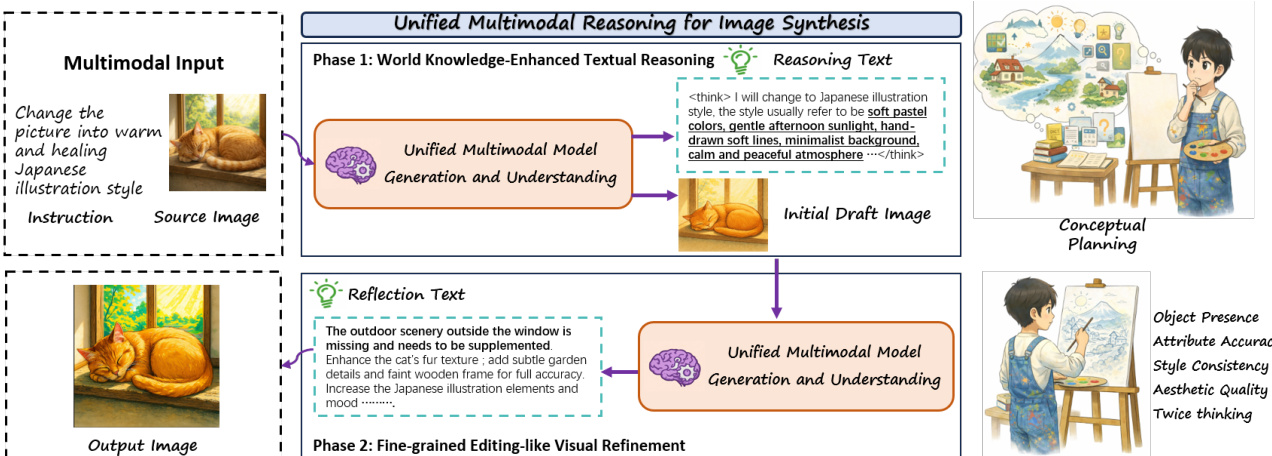
作者利用名为 UniReason 的统一框架,将文生图生成与图像编辑视为相互关联的推理步骤而非孤立任务,以弥合二者之间的鸿沟。先前方法要么仅在生成前推理而无视觉反馈,要么将生成与编辑分开处理,未能利用物理或文化常识等隐式世界知识,也未能发挥其结构协同效应。UniReason 引入两个关键组件:增强世界知识的文本推理(用于在合成前推断隐式约束)与细粒度编辑式视觉优化(用于在之后自我纠错),所有组件均在一个新构建的涵盖五个知识领域及代理生成优化语料的数据集上训练。该统一方法在推理密集型基准测试中达到最先进水平,同时保持强大的通用合成性能。
数据集
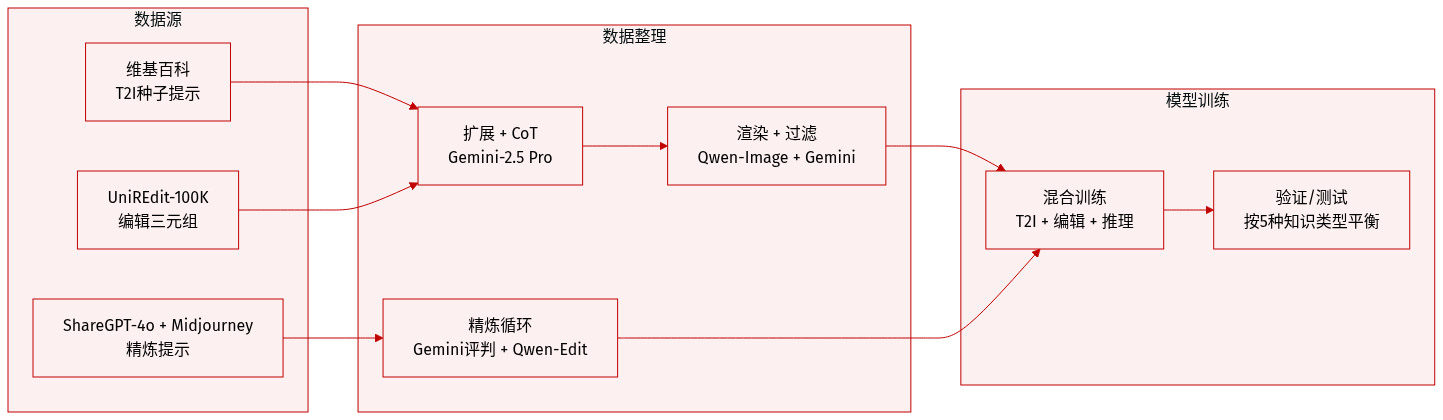
作者采用两阶段数据构建流程训练 UniReason,以支持图像合成中的世界知识增强多模态推理。以下是数据的组成、处理与使用方式:
-
数据集组成与来源
- 为文生图(T2I)生成与图像编辑而构建。
- 从 Wikipedia 获取种子提示,从 UniREdit-Data-100K 获取编辑三元组,从 ShareGPT-4o-Image 与 Midjourney 提示中获取优化训练数据。
- 覆盖五个世界知识类别:文化常识、自然科学、空间推理、时间推理与逻辑推理。
-
各子集关键细节
- T2I 生成:种子提示手动从 Wikipedia 编写;使用 Gemini-2.5 Pro 扩展并配对 CoT 推理;通过 Qwen-Image 渲染图像。
- 图像编辑:使用 UniREdit-Data-100K 三元组;辅以 Gemini-2.5 Pro 生成的推理轨迹。
- 优化数据:通过代理流程生成 — 初始图像 + 推理 → Gemini-2.5 Pro 反馈 → Qwen-Image-Edit 优化 → Gemini-2.5 Pro 判断改进有效性。
-
数据筛选与质量控制
- 所有样本由 Gemini-2.5 Pro 从三个维度评估:指令对齐性、视觉保真度与推理正确性。
- 仅保留经验证、无幻觉的样本。
- 优化阶段包含对比评估,确保视觉与语义上的可测量改进。
-
训练使用与处理
- 训练数据混合 T2I 与编辑样本,每个样本均配对结构化推理轨迹。
- 混合比例未明确说明,但强调在五个知识类别中均衡覆盖。
- 未提及裁剪或元数据构建;重点在于推理轨迹生成与迭代优化监督。
方法
作者利用一个统一的多模态推理框架,称为 UniReason,旨在通过交织文本推理与视觉优化支持文生图(T2I)生成与图像编辑。该架构基于 Bagel 的混合 Transformer(MoT)基础,集成 ViT 编码器以处理多模态输入,并在单一模型内实现联合理解与生成。多模态理解被形式化为基于上下文的下一个标记预测,最小化负对数似然:
Ltext=−t=1∑Tlogpθ(xt∣x<t,C),其中 xt 为目标标记,x<t 为前置标记,C 为多模态上下文。图像生成在 VAE 潜在空间中通过修正流进行,最小化潜在流匹配损失:
Limage=Et∼U(0,1)∥uθ(zt,t;C)−u⋆(zt,t)∥γ2,其中 u∗ 为目标速度,uθ 为学习到的时变速度场。
该框架分两个顺序阶段运行。第一阶段“世界知识增强文本推理”通过生成包含领域特定知识(如风格、对象属性或空间约束)的推理轨迹启动合成,随后生成初始草图图像。该阶段由数据流程支持:使用世界知识来源(如常识、自然科学)扩展种子提示,通过 Gemini 2.5 Pro 生成推理链,再由 Qwen-Image 渲染图像并验证。
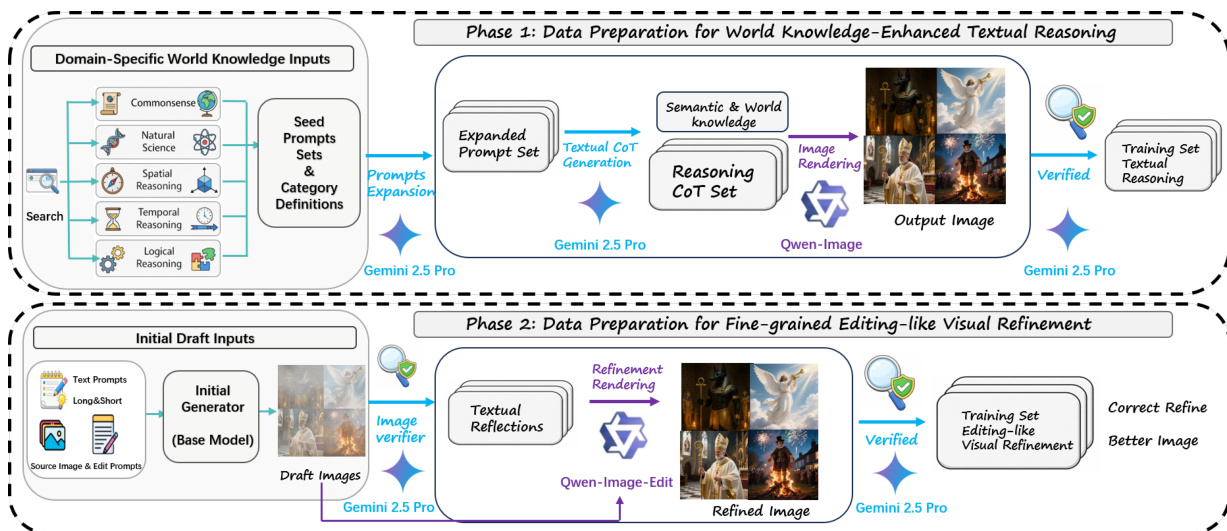
第二阶段“细粒度编辑式视觉优化”通过反思草图的不足之处迭代改进。模型生成文本反思,识别不一致或缺失细节(如对象存在性、属性准确性或美学质量),并可选地进行第二轮推理以引导视觉优化。此过程模拟图像编辑,形成协同循环:T2I 生成受益于编辑专长,反之亦然。优化数据通过代理流程构建:初始生成器产生草图,验证器(Gemini 2.5 Pro)输出结构化编辑指令,优化教师(Qwen-Image-Edit)应用指令,最终评判器仅保留改进输出。
训练通过两阶段监督微调策略进行。第一阶段冻结理解分支,仅在标准 T2I 与编辑数据集上训练生成分支,以强化基础合成能力。第二阶段解冻所有参数,在交错推理数据上联合训练两个分支,监督推理轨迹与优化图像,而初始草图保持无监督。整体损失为加权和:
L=λtextLtext+λimgLimg,其中 Ltext 与 Limg 分别为文本与图像损失,λtext、λimg 为平衡其贡献的标量权重。
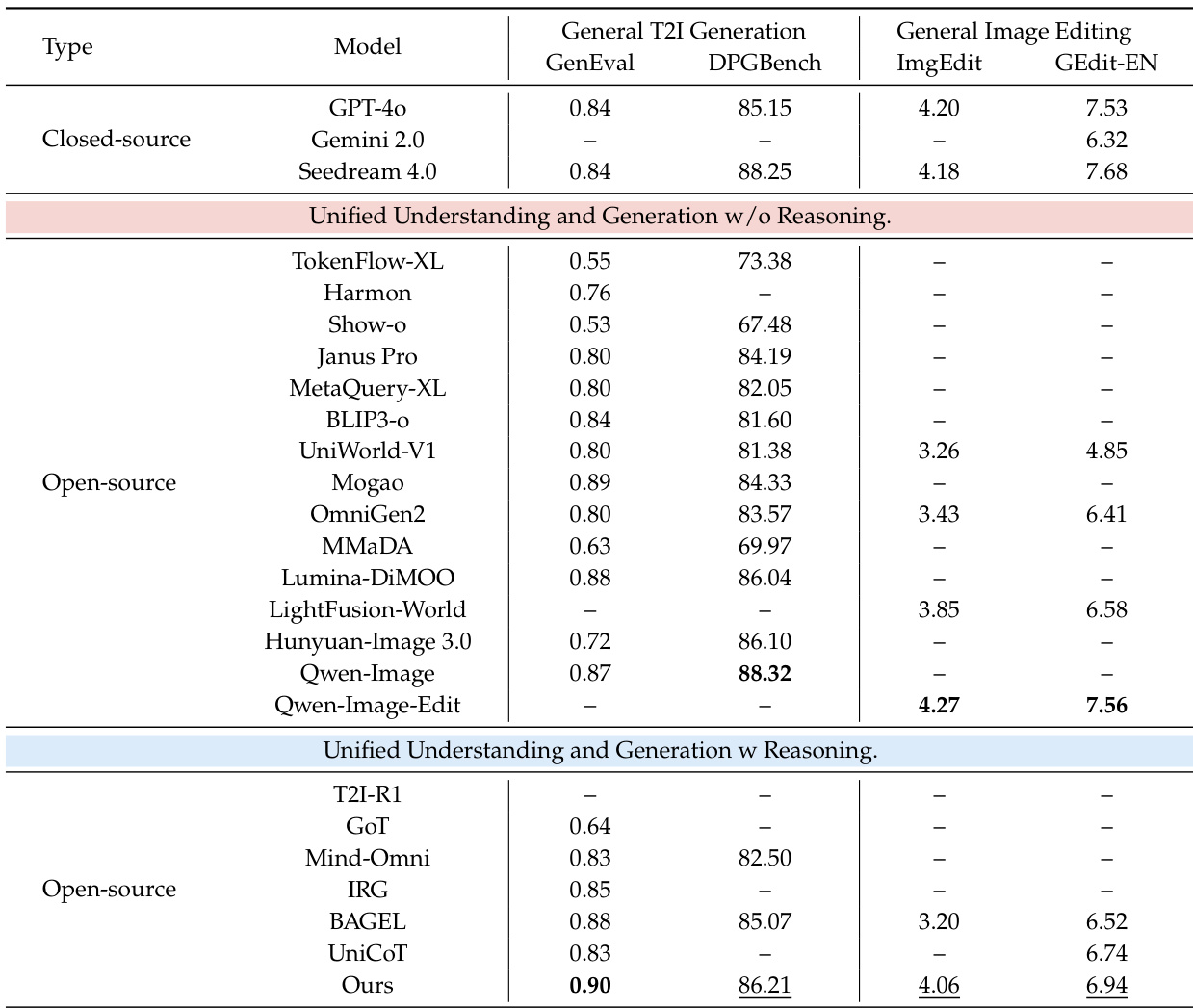
实验
- 两阶段训练成功将知识增强推理与视觉优化整合进统一多模态模型,显著提升知识密集型任务性能。
- 该模型优于领先的开源统一模型,在关键基准测试中达到或超越 GPT-4o 与 Gemini 2.0 等闭源模型,尤其在文化、空间与科学推理方面表现突出。
- 它保持强大的通用生成与编辑能力,在通用基准测试中超越 Qwen-Image 与 Seedream 4.0 等系统,且不依赖外部大语言模型。
- 消融研究证实,每个组件——两阶段训练、文本推理与视觉优化——均逐步提升结果,其中推理贡献最大。
- 图像编辑能力与优化效果直接相关,强调在统一推理框架内联合训练生成与编辑的必要性。
- 定性结果显示,该模型能处理复杂推理场景并优化人脸、文本与手势等细节,提升准确性与视觉保真度。
作者采用两阶段训练方法,增强统一多模态模型在图像生成与编辑中的能力,同时融入显式推理。结果表明,该模型在知识密集型任务中优于其他开源统一模型,并在特定基准测试中达到或超越闭源系统,尤其在文化、空间与科学推理方面表现优异。它在通用生成与编辑任务中也保持强大性能,展现出广泛能力而不牺牲通用性。
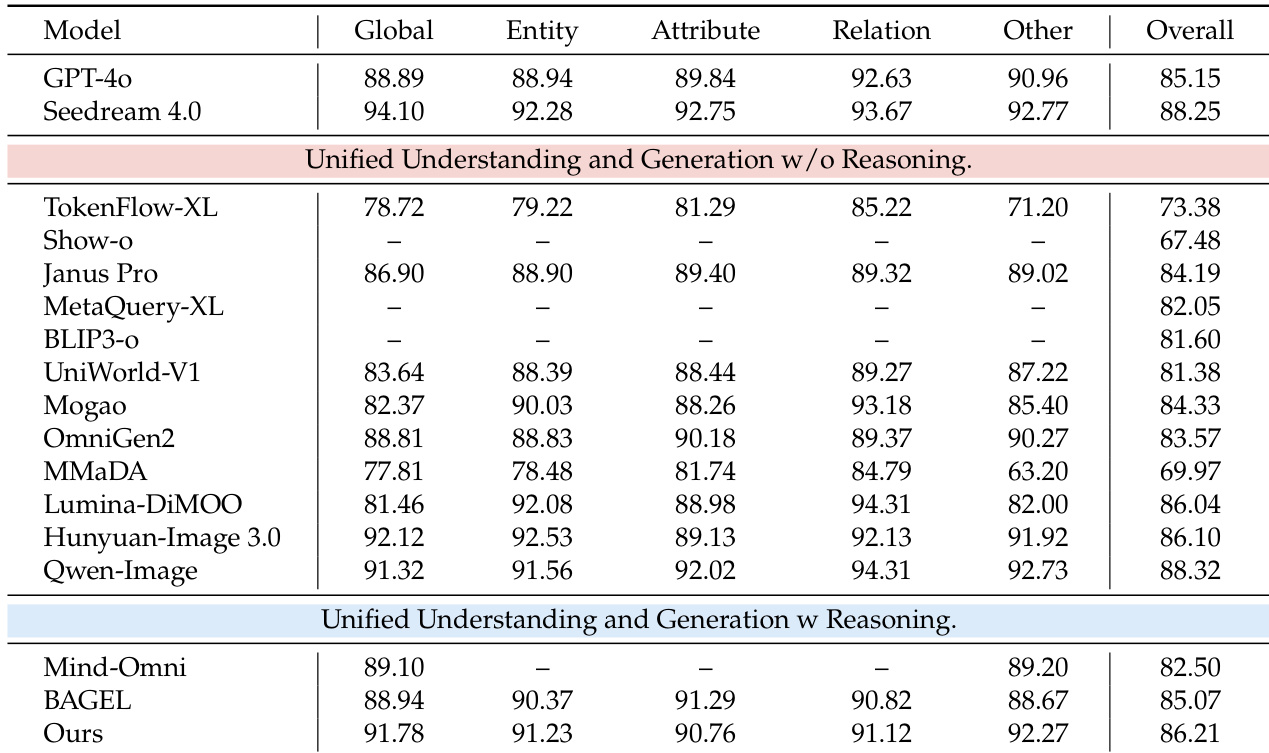
作者通过渐进式消融研究,展示依次添加两阶段训练、推理与优化组件可提升知识密集型基准测试性能。结果表明每个阶段均显著贡献,其中推理在 WISE 上带来最大提升,优化进一步提升所有任务得分。这表明将显式推理与视觉优化整合进统一框架,可增强知识处理与输出质量。
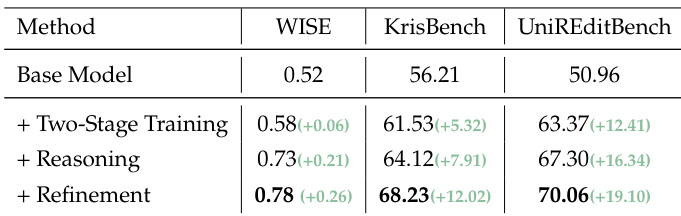
作者在通用图像编辑基准测试中评估其模型,显示其在具备推理能力的统一模型中获得最高总分。结果表明,其在“添加”、“调整”与“替换”等细粒度编辑类别中表现强劲,同时在 GEdit-EN 上保持有竞争力的分数。这表明该模型能平衡通用编辑能力与推理增强控制。
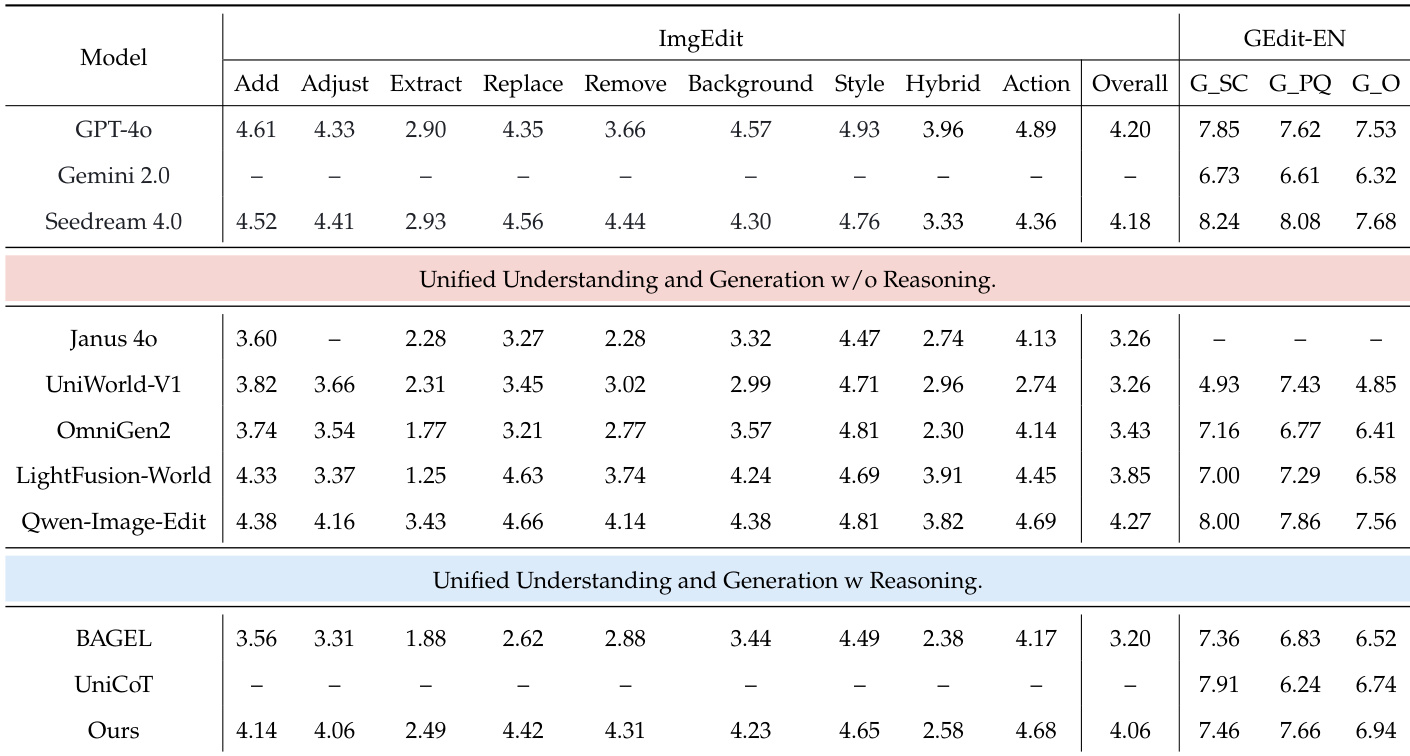
作者使用具备显式推理与优化机制的统一多模态模型,在知识密集型图像生成与编辑任务中达到开源系统中的最佳表现。结果表明,该模型优于同类统一模型,并在特定基准测试中媲美 GPT-4o 与 Gemini 2.0 等闭源系统,尤其在事实与概念推理方面表现突出。该模型同时保持强大的通用生成与编辑能力,展现出广泛适用性而不牺牲通用性。
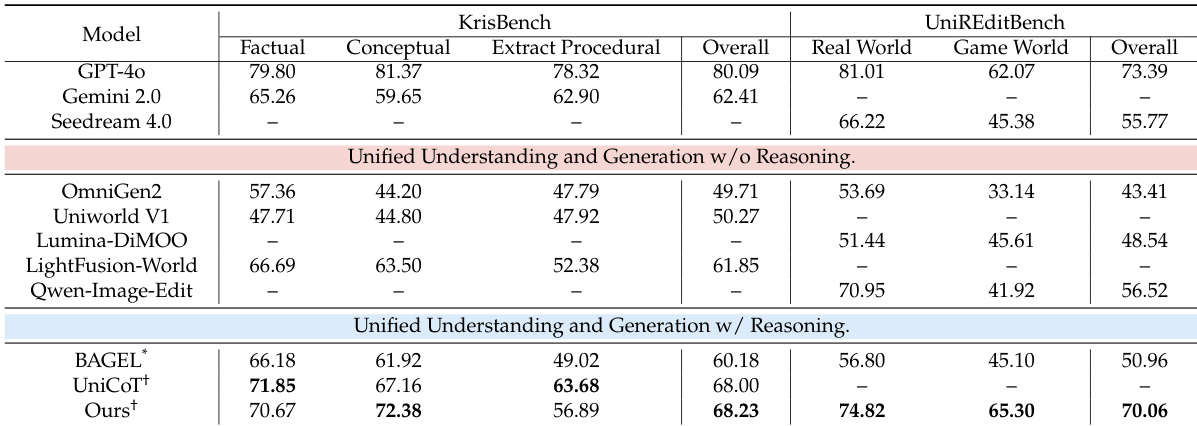
作者采用两阶段训练方法,增强统一多模态模型在文生图生成与图像编辑中的能力,同时融入推理。结果表明,该模型在通用基准测试中达到开源系统中的最佳表现,并在特定知识密集型任务中优于多个闭源模型。它在生成与编辑中均保持强大泛化能力,表明推理整合并未损害广泛能力。