Command Palette
Search for a command to run...
Kimi K2.5:视觉智能体智能
Kimi K2.5:视觉智能体智能
摘要
我们推出Kimi K2.5,一款开源的多模态智能体模型,旨在推动通用智能体智能的发展。K2.5强调文本与视觉模态的联合优化,使两种模态相互增强,具体包括联合文本-视觉预训练、零视觉监督微调(zero-vision SFT)以及联合文本-视觉强化学习等一系列技术。在此多模态基础之上,K2.5引入了“智能体蜂群”(Agent Swarm)机制,这是一种自驱动的并行智能体编排框架,能够动态地将复杂任务分解为异构的子问题,并实现并行执行。大量实验评估表明,Kimi K2.5在编程、视觉理解、推理以及智能体任务等多个领域均取得了当前最优(SOTA)性能。此外,Agent Swarm相较单智能体基线方法,可将延迟降低最高达4.5倍。我们已公开发布经过后训练的Kimi K2.5模型检查点,以促进未来在智能体智能领域的研究与实际应用。
一句话总结
Kimi 团队推出 Kimi K2.5,这是一款开源多模态智能体模型,通过新颖的训练技术和 Agent Swarm——一种并行编排框架——联合优化文本与视觉,效率提升高达 4.5 倍,并在编码、视觉、推理及智能体任务中实现前沿性能。
主要贡献
- Kimi K2.5 通过早期融合预训练、零视觉监督微调和跨模态强化学习,引入文本-视觉联合优化,实现模态间的双向增强,在推理、编码和视觉基准测试中达到最先进性能。
- 该模型采用 Agent Swarm——一种并行智能体编排框架,可动态将任务分解为并发子任务,推理延迟最高降低 4.5 倍,同时提升任务级 F1 分数,优于顺序基线。
- 基于 MoonViT-3D 架构,支持原生分辨率编码和 3D ViT 视频压缩,K2.5 支持可变分辨率输入和长视频处理,其开源检查点旨在加速通用智能体智能的研究。
引言
作者利用联合文本-视觉预训练与强化学习构建 Kimi K2.5——一款开源多模态智能体模型,提升跨模态推理与任务执行能力。以往模型常将视觉与语言分开处理,限制了其处理需双模态协同的复杂现实智能体任务的能力。Kimi K2.5 引入 Agent Swarm 框架,动态将任务拆分为并行子智能体,延迟最高降低 4.5 倍,同时在编码、视觉和推理基准测试中提升性能。通过开源模型,团队推动可扩展通用智能体智能的广泛研究。
数据集
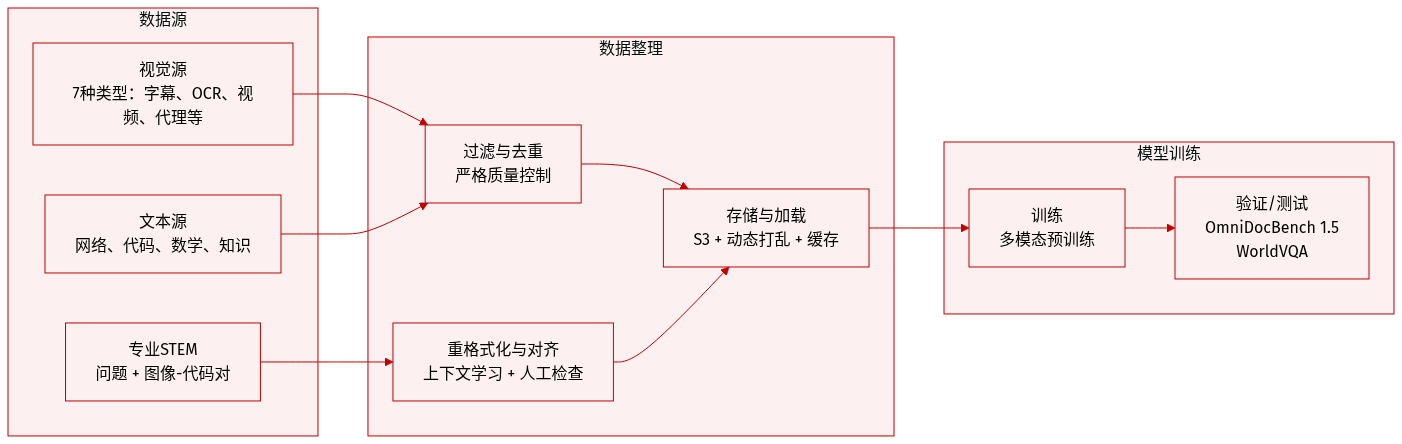
-
作者使用多模态预训练语料,划分为七类视觉数据:描述、交错、OCR、知识、感知、视频和智能体数据。描述数据确保模态对齐,减少合成内容以降低幻觉。来自书籍和网页的交错数据支持多图及长上下文学习。OCR 数据涵盖多语言、密集和多页文档。知识数据使用布局解析的学术材料构建视觉推理能力。
-
针对 STEM 推理,作者通过定向检索和网络爬取构建专用解题语料。无明确问题的原始材料通过上下文学习重构为结构化学术问题(K-12 至大学级别)。图像-代码对(涵盖 HTML、React、SVG)将抽象代码与渲染视觉对齐,弥合视觉与代码模态。
-
智能体与时间理解数据包括桌面、移动端和网页的 GUI 截图与操作轨迹,辅以人工标注演示。视频数据支持长达数小时的理解和细粒度时空感知。定位数据增加边界框、点引用及新轮廓级分割任务,实现像素级感知。
-
所有视觉数据均经过严格过滤、去重和质量控制,确保多样性与有效性。
-
文本语料涵盖四大领域:网络文本、代码、数学和知识。代码数据被加权扩展,包含仓库级代码、问题、评审、提交及 PDF 和网页文本中的代码相关文档,以提升跨文件推理及智能体编码任务(如补丁生成和单元测试)。
-
监督微调阶段,作者使用 K2、K2 Thinking 和专有专家模型合成高质量回复。领域特定流水线结合人工标注、提示工程与多阶段验证,生成包含多样化提示和推理路径的指令微调数据,训练模型实现交互推理和工具调用。
-
数据存储于兼容 S3 的对象存储中。加载基础设施支持动态混洗、混合、分词和序列打包;在保留空间元数据的同时实现随机增强;通过种子管理确保训练确定性;并通过分层缓存高效扩展。统一平台管理数据注册、可视化、统计、跨云同步和生命周期治理。
-
评估包括 OmniDocBench 1.5(使用归一化 Levenshtein 距离)和 WorldVQA(用于细粒度视觉与地理知识)。
方法
作者基于 Kimi K2 MoE Transformer 主干构建统一多模态架构,实现文本与视觉模态的智能体智能。核心框架整合原生分辨率 3D 视觉编码器(MoonViT-3D)、MLP 投影器和语言模型,实现视觉与文本表示的无缝联合优化。预训练期间,模型处理约 15 万亿混合视觉-文本标记,训练全程以恒定比例早期融合视觉标记,增强跨模态对齐。架构上,MoonViT-3D 为图像与视频共享嵌入空间:连续帧分组为时空体,展平为 1D 序列,通过共享编码器处理并结合时序池化实现 4 倍压缩,从而在固定上下文窗口内支持更长视频理解。
参见框架图,展示智能体编排机制。系统引入 Agent Swarm——一种动态并行执行框架,其中可训练编排器创建并委托任务至冻结子智能体。该解耦架构避免端到端联合优化,缓解信用分配模糊与训练不稳定。编排器学习将复杂任务分解为可并行子任务(如分配领域专家或事实核查员),并基于环境反馈调度执行。训练目标由复合 PARL 奖励引导,平衡子智能体实例化、任务完成与整体性能,辅以防止串行崩溃与虚假并行的项。关键步骤(定义为主智能体步骤总和加上每阶段最大子智能体步骤)作为资源约束,激励延迟最小化并行化。
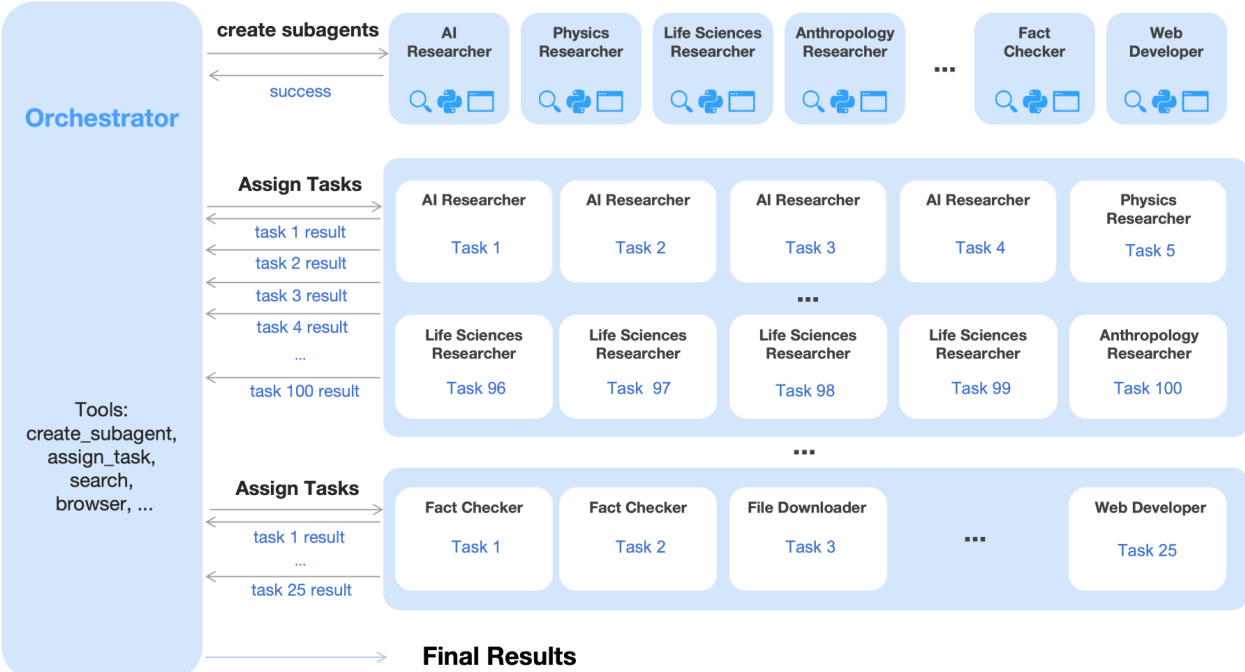
后训练流程始于零视觉 SFT,仅文本监督微调通过 IPython 中的程序化操作代理图像操作,激活视觉推理能力。此方法避免了人工设计视觉轨迹导致的泛化能力下降。随后,在按能力而非模态组织的领域(知识、推理、编码、智能体)中应用联合多模态 RL,使用统一生成式奖励模型(GRM)评估异构轨迹,无模态障碍。基于结果的视觉 RL 针对定位、图表理解和 STEM 任务,不仅提升视觉性能,也提升 MMLU-Pro 和 GPQA-Diamond 等文本基准,体现跨模态双向增强。
强化学习算法采用标记级裁剪策略目标,在长视野、多步骤工具使用场景中稳定训练。奖励函数结合基于规则的结果信号、预算控制激励与评估用户复杂体验的 GRM。为协调推理质量与计算效率,作者引入 Toggle——一种训练启发式方法,交替预算约束与无约束阶段,根据问题难度与模型精度动态调整优化。这使模型生成更简洁推理,同时保持对更高计算预算的可扩展性。
训练基础设施通过解耦编码器流程(DEP)优化,将视觉编码器计算与主 Transformer 主干分离。DEP 在所有 GPU 上执行视觉前向传播以平衡负载,丢弃中间激活以减少内存,并在反向传播中重新计算,实现相对于纯文本训练 90% 的多模态训练效率。统一智能体 RL 环境支持异步、协程式任务执行,配备可插拔组件(工具集、评判器、提示多样化),支持高达 100,000 个并发智能体任务的可扩展编排。
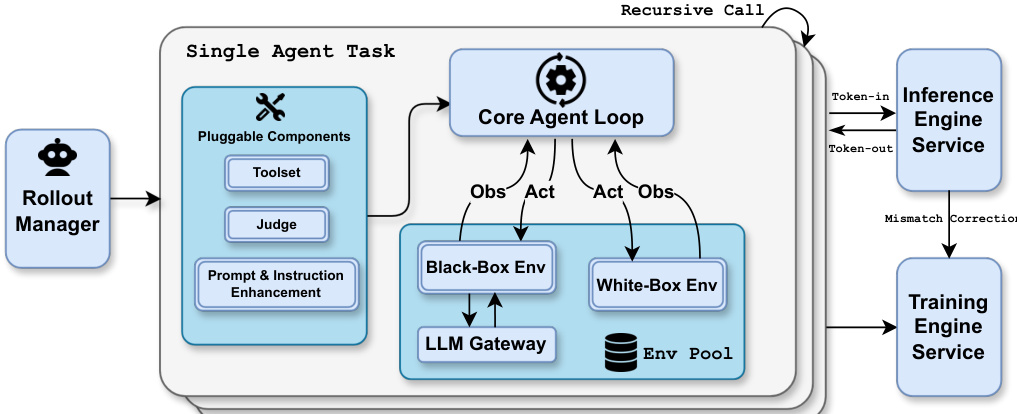
如下图所示,系统在大规模多模态任务中展示能力,如分析总计 24 小时、40GB 游戏视频的 32 个片段。编排器生成子智能体并行处理各视频,提取帧、识别关键事件并聚合结果为综合 HTML 展示。此工作流体现系统通过动态并行分解处理海量异构工作负载,同时保持连贯长上下文理解的能力。

实验
- 预训练期间采用中等视觉比例的早期融合策略,相比后期高视觉比例策略,获得更优多模态性能,挑战传统方法,支持原生多模态训练。
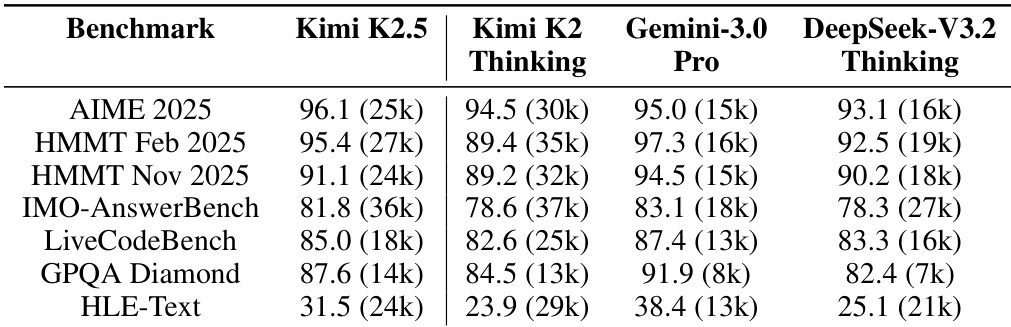
- Kimi K2.5 在推理、编码、智能体搜索、视觉、视频理解及计算机使用等多领域达到最先进或具竞争力性能,常优于领先专有模型。
- Agent Swarm 架构通过并行子智能体执行、动态调度和主动上下文管理,显著提升复杂智能体任务性能,提高准确率与速度。
- 系统通过高效处理长上下文、多步骤及工具密集型任务,展现强大现实能力,在需合成、检索和自主执行的基准测试中表现优异。
- Agent Swarm 的性能提升在高复杂度、可扩展场景中最显著,验证架构并行性转化为超越效率的质变能力。
作者使用智能体群框架动态编排多个专用子智能体,在复杂智能体任务上显著优于单智能体配置。结果表明,该方法不仅提升准确率(尤其在需广泛探索或并行分解的基准上),还通过并行化将执行时间减少 3 至 4.5 倍。群架构通过隔离子任务上下文实现主动上下文管理,在扩展有效上下文长度的同时保持推理完整性。

作者发现,预训练期间以较低比例早期注入视觉标记,相比中后期高比例注入,即使在固定标记预算下,整体多模态性能更强。结果表明,早期融合更好保留文本能力,带来更稳定训练动态,支持原生多模态预训练方法。此策略从一开始就实现视觉与语言表示的更平衡联合优化。

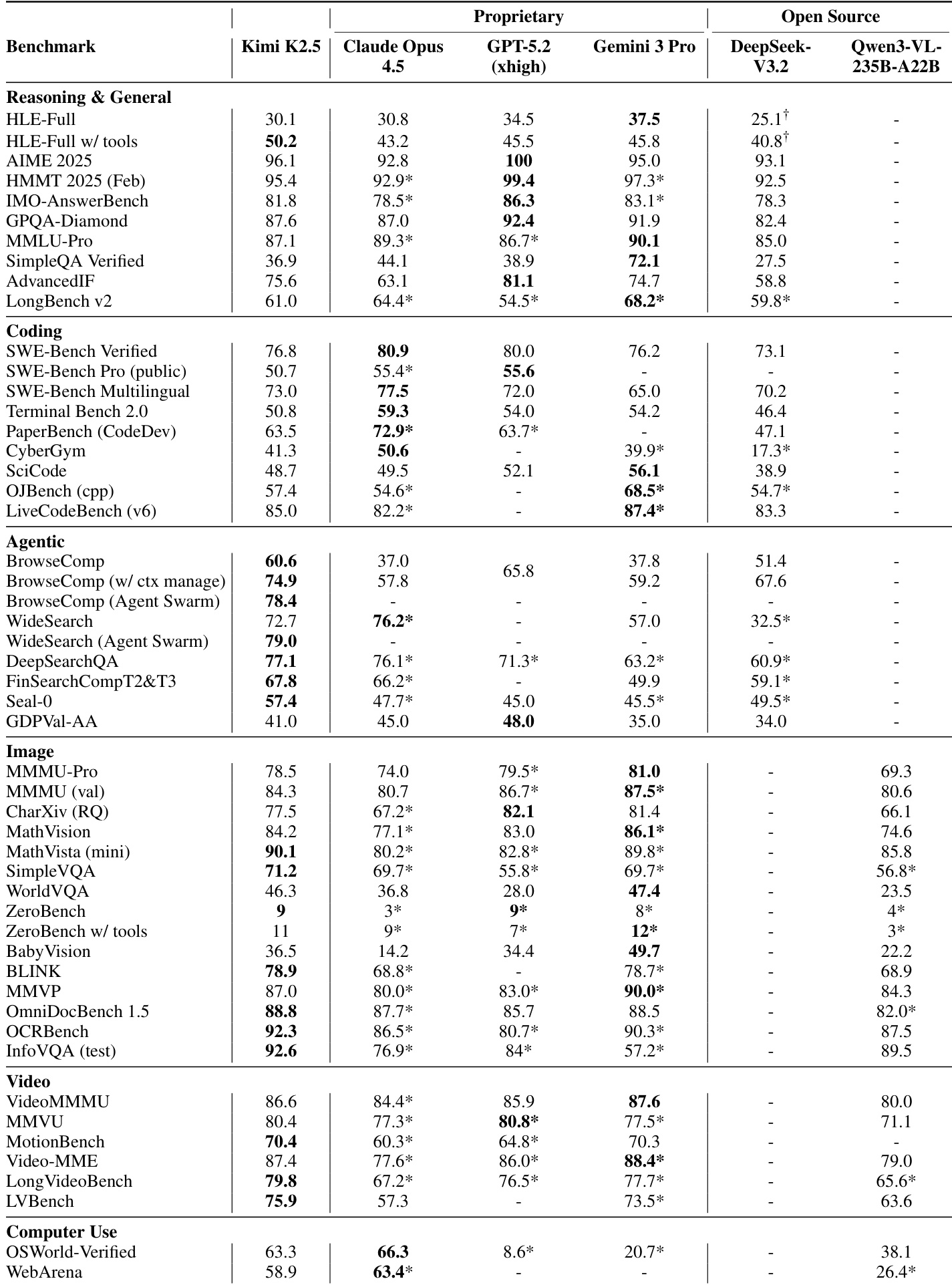
结果表明,Kimi K2.5 在推理、编码、智能体、视觉、视频及计算机使用基准测试中达到具竞争力或领先性能,常在可比评估设置下匹敌或超越 Claude Opus 4.5 和 GPT-5.2 等顶级专有模型。模型在复杂智能体任务和长上下文推理中表现突出,其 Agent Swarm 框架通过并行子智能体编排在准确率与效率上均带来显著提升。其原生多模态预训练策略(早期以中等比例整合视觉)支持稳健跨模态性能,不牺牲语言能力。
作者使用固定标记预算比较多模态预训练策略,发现早期融合低视觉比例优于后期高视觉比例训练,表明从开始平衡联合优化模态可获得更稳健表示。结果表明,Kimi K2.5 在推理、编码、智能体及多模态基准测试中达到具竞争力或更优性能,常匹敌或超越专有模型,尽管使用中等视觉整合和高效上下文管理。智能体群框架进一步提升性能并减少执行时间,通过并行、上下文分片的子智能体执行,不牺牲推理完整性。
作者在初始预训练后使用视觉强化学习阶段增强多模态能力。结果表明,在 MMLU-Pro、GPQA-Diamond 和 LongBench v2 等多个基准测试中持续提升,表明针对性视觉微调有效提升推理和长上下文任务性能。这表明预训练后视觉对齐对更广泛多模态能力有实质贡献。
