Command Palette
Search for a command to run...
思维链中缺乏全局规划:揭示LLM的潜在规划时域
思维链中缺乏全局规划:揭示LLM的潜在规划时域
Liyan Xu Mo Yu Fandong Meng Jie Zhou
摘要
本研究源于对思维链(Chain-of-Thought, CoT)动态机制的先前互补性观察:大型语言模型(LLMs)在CoT显现之前,已展现出对后续推理过程的隐式规划,这在一定程度上削弱了显式CoT的重要性;然而,对于需要多步推理的任务,CoT依然至关重要。为深化对LLM内部状态与其显性推理轨迹之间关系的理解,本文通过我们提出的探测方法——Tele-Lens,系统性地考察了LLM在不同任务领域中隐藏状态的隐式规划强度。实证结果表明,LLM呈现出一种短视的规划视野,主要依赖增量式状态转移,缺乏对全局路径的精确规划。基于这一特性,我们提出了一项关于提升CoT不确定性估计的假设,并验证了仅需少量CoT位置即可有效表征整条推理路径的不确定性。此外,我们进一步强调了挖掘CoT动态特性的价值,并证明了在不造成性能下降的前提下,可实现对CoT绕行(bypass)的自动识别。相关代码、数据与模型已开源,详见:https://github.com/lxucs/tele-lens。
一句话总结
清华大学的徐立言等人提出 Tele-Lens 方法,用于探测大语言模型(LLM)的潜在规划能力,揭示其推理具有“短视”特征;他们证明,仅需少量 CoT 关键位置即可实现不确定性估计,并可在不损失性能的前提下跳过 CoT 步骤,从而推进多步任务中的高效推理。
主要贡献
- 我们引入 Tele-Lens,一种探测方法,分析 LLM 在 12 个不同数据集上的隐藏状态,揭示模型表现出短视规划视野——更倾向于局部过渡而非全局推理计划,尤其在复杂的多步任务中。
- 基于这种短视行为,我们提出并验证“木桶”假说:CoT 推理中的不确定性可通过少量关键位置捕捉,无需完整路径计算即可提升不确定性估计准确率最高达 6%。
- 我们证明,CoT 跳过(自动跳过不必要的推理步骤)可被可靠检测并应用,且不会降低性能,凸显建模 CoT 动态在效率与校准方面的实用价值。
引言
作者利用探测技术探究大语言模型(LLM)在生成思维链(CoT)输出前是否在内部规划完整的推理链——鉴于 CoT 在支持复杂多步推理中的关键作用,这是一个核心问题。先前研究观点不一:一些研究认为早期隐藏状态已编码未来推理路径,而另一些则认为由于 Transformer 架构限制,CoT 仍不可或缺。作者引入 Tele-Lens,一种低秩适配器,探测 12 个不同任务中的隐藏状态,揭示 LLM 表现出短视规划视野——主要支持局部过渡而非全局计划,仅在简单任务中早期状态可能暗示粗略答案概要。基于此,他们提出并验证两个应用:“木桶”假说用于不确定性估计(聚焦关键 CoT 位置可提升准确率最高达 6%),以及在无需 CoT 时自动跳过 CoT 的方法,实现 16.2% 的跳过率且性能损失可忽略。
数据集
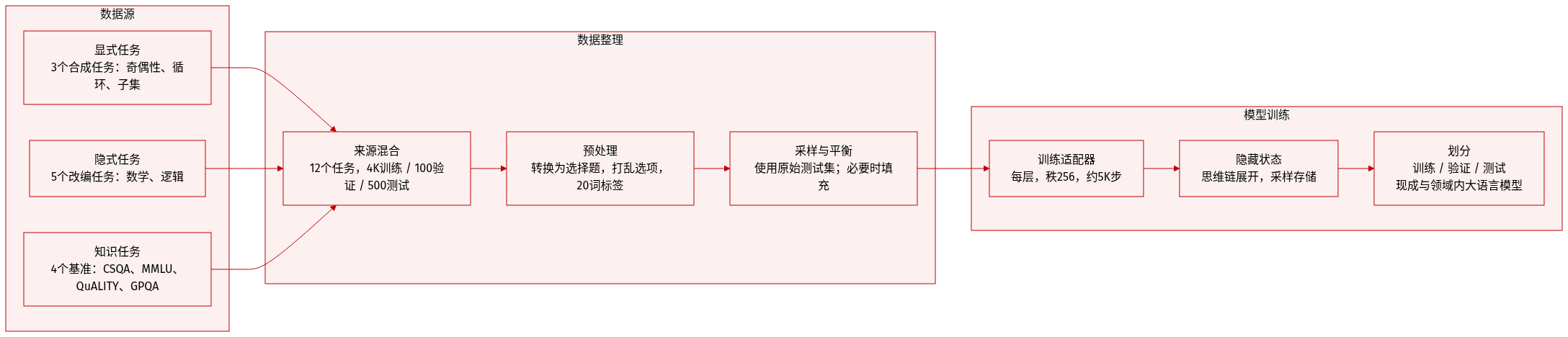
作者使用涵盖 12 个任务的多样化多任务数据集,分为三类:显式组合任务、隐式组合任务、知识与语义任务。
-
显式组合任务(3 个任务,合成生成):
- 奇偶性:随机数字序列(长度 5–100),目标数字来自 {1,2,7,8},标签 = 计数的奇偶性。
- 环路:随机边列表(4–100 条边),生成单环或双环,标签基于两个随机顶点间路径的存在性。
- 子和:随机整数列表(长度 2–50,值 1–9),标签 = 通过动态规划计算的最大子序列和的最低位数字。
- 三个任务均可完全控制,标签分布均衡。
-
隐式组合任务(5 个任务,改编自现有数据集):
- 数学:GSM8K、MATH、AIME —— 原为自由形式;使用 GPT-4.1 为每题生成 4 个干扰项转为多选题。
- 逻辑:MuSR、Zebra —— 自然语言推理任务,含软性或符号约束。
- MATH 使用 MATH-500 测试集;AIME’25 仅包含测试集全部 30 道题。
-
知识与语义任务(4 个任务,采样自现有基准):
- CSQA、MMLU、QuALITY、GPQA —— 侧重知识检索与语义理解。
- QuALITY 使用 RAG 风格片段(最大 2K 上下文)以提升效率。
- 所有多选题答案选项均打乱以减少位置偏差。
-
数据集划分与处理:
- 每个任务最多包含 4K 训练 / 100 验证 / 500 测试问题。
- 非合成任务的训练/验证集从原始测试集采样;若不足,则从训练/验证集抽取。
- 最终答案探测使用固定 20 个 token 标签集:{A–E, F, YES, NO, even, odd, 0–9}。
-
模型使用与元数据:
- 用于训练每层 Transformer 的 Tele-Lens 适配器(秩 256),约 5K 步训练并采用早停。
- 隐藏状态从 CoT 推理轨迹收集(测试最大长度 16,384;训练/验证采样 5–10% 以减少存储)。
- 每层数据集规模:现成 LLM —— 2.4M 训练 / 81K 验证 / 11M 测试隐藏状态;领域内 LLM —— 2.5M / 57K / 2.7M。
- 标签编码目的性维度:下一 token ID、最终答案 token、CoT 长度等。
方法
作者利用一种名为 Tele-Lens 的探测机制,从大语言模型在思维链(CoT)推理过程中产生的中间隐藏状态中提取目的性信号。该方法扩展了 Logit Lens 范式,引入带非线性的低秩适配器,将隐藏状态转换为词汇表规模的预测,同时最小化计算开销和过拟合。对于推理轨迹 T={t1,t2,..,tn} 中的每个 token ti,第 k 层的隐藏状态 Hik 通过瓶颈适配器转换为 Hik,然后通过冻结的语言模型头部投影,得到词汇表 V 上的概率分布 Pik:
Hik=GeLU((Hik+Embk(δ))Ak)BkPik(V∣ti,Ak,Bk,Embk,δ)=Softmax(HikL)其中,Ak∈Rd×r 和 Bk∈Rr×d 是低秩适配器矩阵,Embk 可选地编码位置偏移 δ 以预测未来 token。冻结的 LM 头部 L∈Rd×∣V∣ 确保与模型原生输出空间对齐。
Tele-Lens 在每个隐藏状态上探测三个不同的目的性维度:后续 token 预测(使用带偏移感知的嵌入)、推理长度估计(通过 Hik 上的回归头)、直接最终答案预测(省略 Embk)。这使得能够精细分析内部表征如何演进以完成任务。
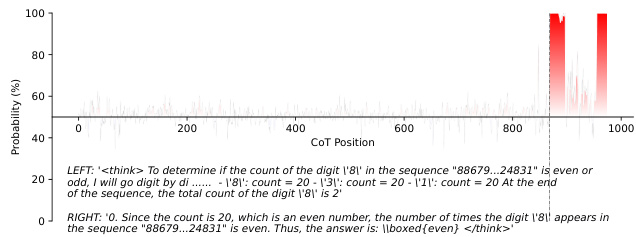
如下图所示,CoT 位置上的概率分布揭示了 Tele-Lens 如何识别关键推理步骤——例如,检测序列中数字 '8' 的最终计数,并将高置信度与最终断言对齐。这说明该方法不仅捕捉 token 级预测,还捕捉推理的目的性结构。
该框架适用于两类 LLM 主干:现成模型如 Qwen3-32B(原生支持 CoT),以及通过 GRPO 强化学习从 Qwen2.5-7B-Instruct 训练的领域内 LLM。后者提供了一个可控环境,以研究特定任务的推理动态,避免通用架构的干扰因素。

参见上图框架示意图,其展示了一个图路径查找问题的 CoT 轨迹。模型明确枚举从源顶点到目标顶点的边遍历,最终得出二元答案。Tele-Lens 可探测每个中间步骤——例如第 31 步后的状态——以预测最终答案或估计剩余推理长度,从而揭示隐藏状态中嵌入的内部规划结构。
实验
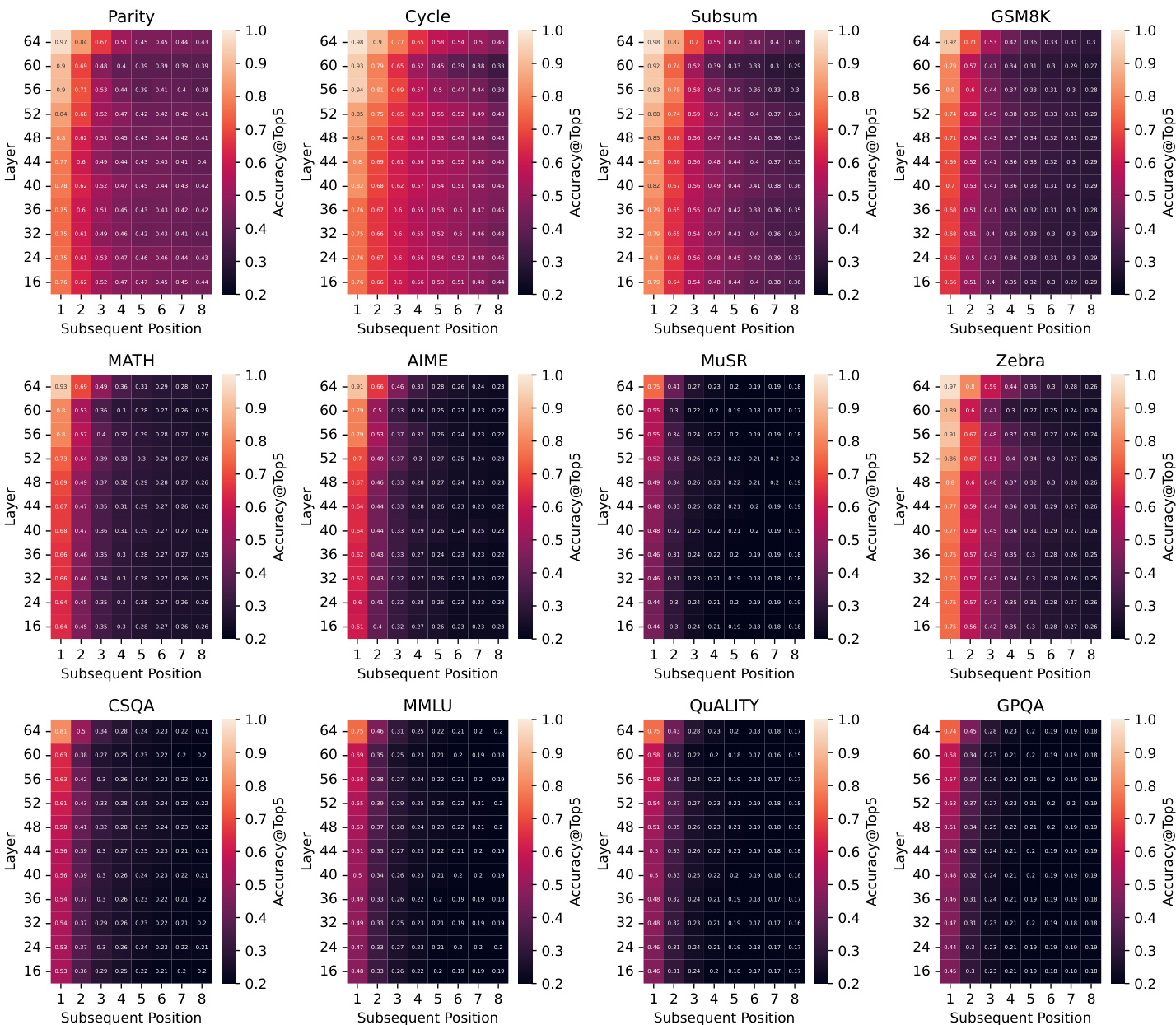
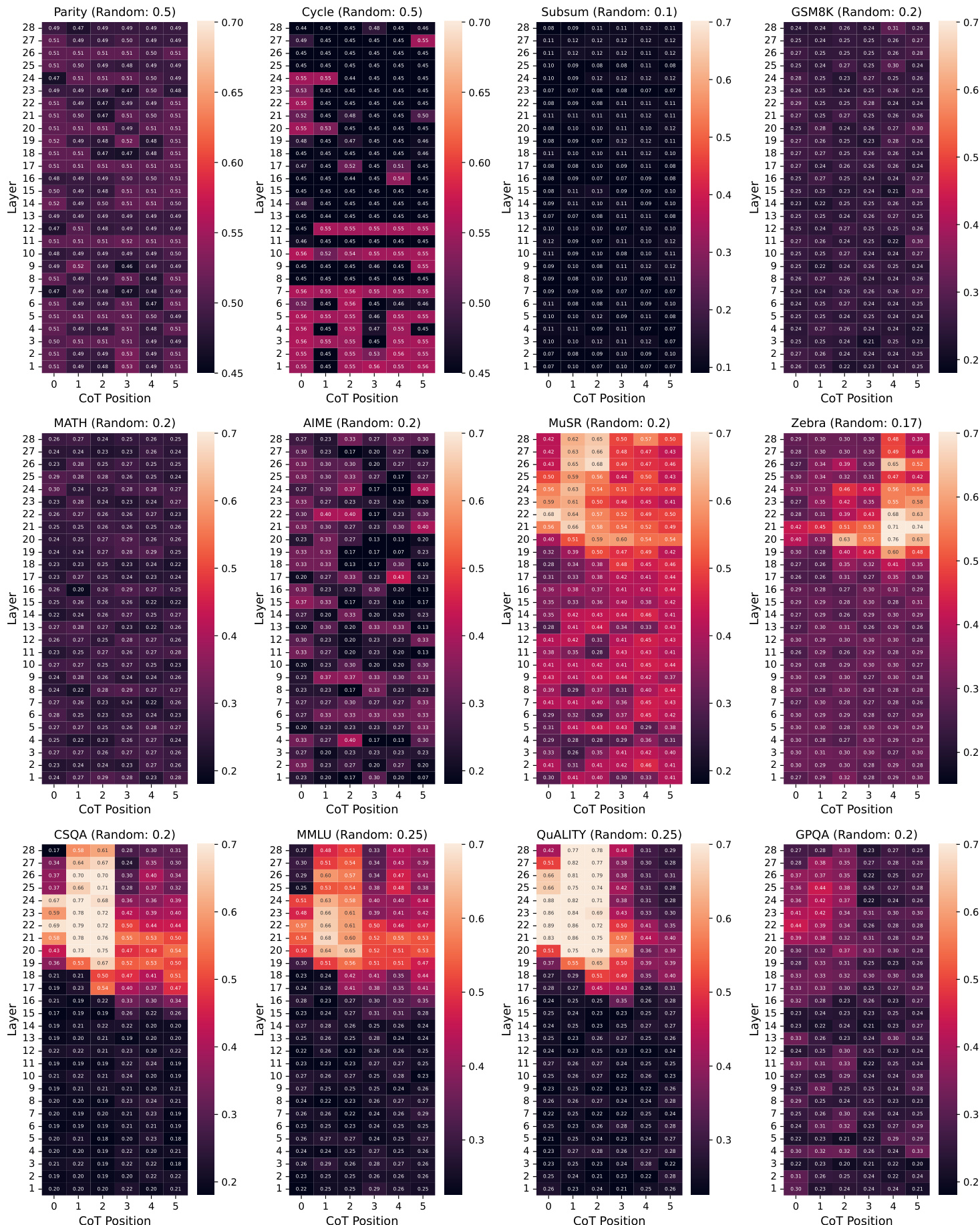
- LLM 表现出短视规划视野,精确的最终答案规划仅在推理末期出现,而非起始阶段,尤其在 Parity 和 Cycle 等组合任务中。
- 早期隐藏状态可能显示粗略信号暗示答案概要,尤其在 CSQA 等语义任务中,但这些信号反映模糊感知而非结构化规划,其准确率低于直接作答或完整 CoT。
- LLM 对后续推理步骤的预见能力有限,预测准确率在超过下一两个 token 后急剧下降,仅在结构模块化任务中因模式可辨而略有维持。
- CoT 早期对全局推理长度的预测效果差;某些任务中看似相关的关联实为可观察输入启发式,而非真实规划。
- 训练领域内 LLM 可产生更短、更果断的 CoT 轨迹,尽管规模更小但仍具竞争力,验证了稳定推理路径的有效诱导。
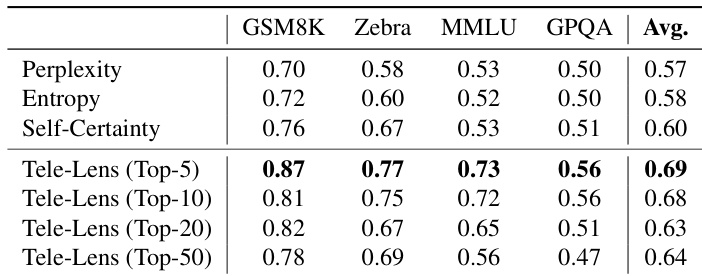
- CoT 的不确定性可通过聚焦少数关键“枢纽”token 而非平均整个轨迹来更好估计,显著提升校准效果。
- 早期 CoT 信号可识别 CoT 是否不必要,从而在简单任务中安全跳过而不损害整体准确率,降低计算负载。
作者使用 Tele-Lens 探测 LLM 隐藏状态预测 CoT 轨迹中后续 token 的能力,揭示在多数任务中,预测准确率在超过下一两个步骤后急剧下降。虽然 Parity 和 Cycle 等结构化任务显示出稍强的持续预见能力,但整体模式表明 LLM 缺乏长期规划能力,主要以短视视野运行。这种有限预见能力在领域内和现成模型中均存在,表明这是当前 LLM 推理动态的一个基本特征。
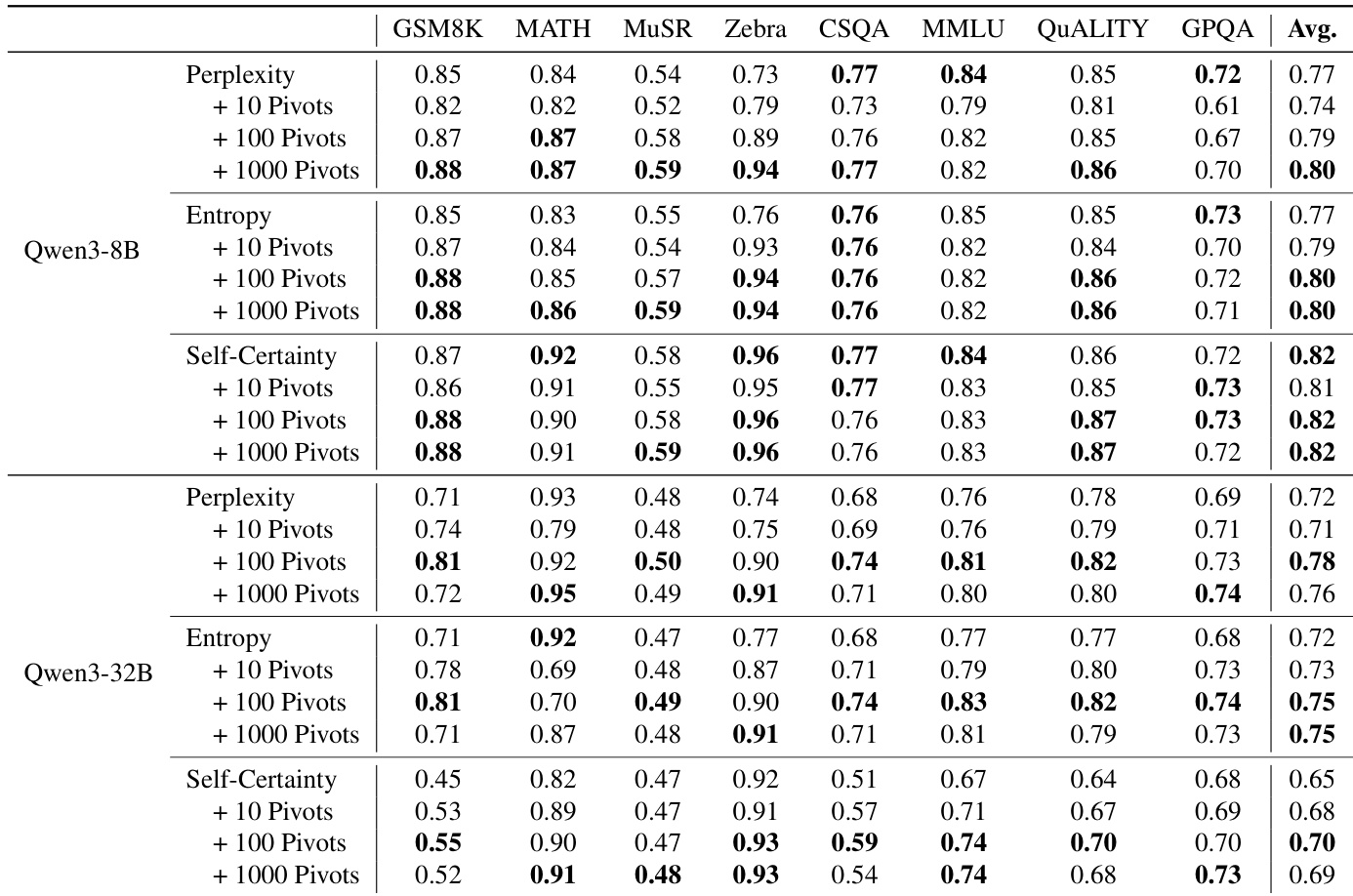
作者基于 CoT 轨迹中的潜在信号使用 top-k 枢纽选择策略以改进不确定性估计,相比完整路径基线最高实现 9% 的绝对 AUROC 提升。结果表明,聚焦少量关键推理步骤比聚合整个链的信号能提供更可靠的不确定性度量。该方法在多个指标和模型规模上持续提升性能,支持“推理不确定性由关键逻辑跳跃而非整体 token 置信度主导”的假说。
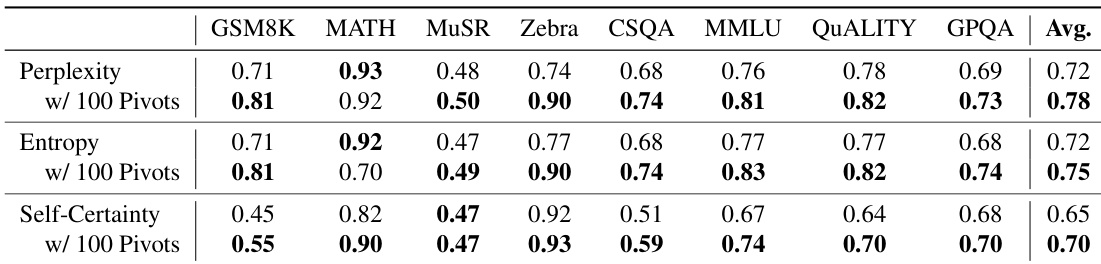
作者使用 Tele-Lens 从 CoT 轨迹中的关键位置提取潜在信号,发现聚焦少量高置信度 token 显著提升不确定性估计。结果表明,仅选择前 5 个枢纽位置即可获得最佳校准效果,优于完整轨迹平均值及困惑度或熵等标准指标。这支持“推理不确定性由少数决定性步骤而非整个链主导”的假说。
作者使用 Tele-Lens 通过分析早期 CoT 位置和 Transformer 层上的最终答案预测准确率来探测 LLM 中的潜在规划。结果表明,精确的最终答案规划在推理开始时基本不存在,仅在组合任务接近完成时才出现;而语义任务可能在早期显示模糊预测信号,但这些信号无法转化为更好的任务性能。这表明 LLM 以短视规划视野运行,依赖逐步探索而非全局预见。
作者基于内部 token 级信号使用 top-k 枢纽选择策略估计推理不确定性,发现聚焦少量关键位置显著优于完整轨迹平均值的校准效果。结果在 Qwen3-8B 和 Qwen3-32B 模型上均一致提升,使用仅 5 个枢纽 token 时 AUROC 最高提升达 9%。这支持“思维链推理中的不确定性由少数决定性逻辑步骤而非整个轨迹主导”的假说。