Command Palette
Search for a command to run...
CodeOCR:视觉语言模型在代码理解中的有效性研究
CodeOCR:视觉语言模型在代码理解中的有效性研究
Yuling Shi Chaoxiang Xie Zhensu Sun Yeheng Chen Chenxu Zhang Longfei Yun Chengcheng Wan Hongyu Zhang David Lo Xiaodong Gu
摘要
大规模语言模型(Large Language Models, LLMs)在源代码理解任务中取得了显著成果,然而随着软件系统规模的持续扩大,计算效率已成为制约其进一步发展的关键瓶颈。当前,这些模型普遍采用基于文本的范式,将源代码视为线性排列的标记序列,导致上下文长度与计算开销呈线性增长。随着多模态大语言模型(Multimodal Large Language Models, MLLMs)的快速发展,一种新的优化路径应运而生:将源代码以渲染图像的形式进行表示。与文本不同,图像在不损失语义信息的前提下具有更强的可压缩性。通过调整图像分辨率,可在保持视觉模型可识别性的前提下,将原始表示的标记数量压缩至其极小比例。为系统评估该方法的可行性,我们首次开展了针对MLLM在代码理解任务中有效性的全面研究。实验结果表明:(1)MLLMs能够在实现高达8倍标记压缩率的同时,仍保持对代码的有效理解能力;(2)MLLMs能够有效利用诸如语法高亮等视觉线索,在4倍压缩率下显著提升代码补全性能;(3)在代码克隆检测等理解任务中,模型表现出对视觉压缩的极强鲁棒性,部分压缩比率甚至优于原始文本输入。本研究揭示了MLLM在代码理解任务中所蕴含的巨大潜力及其当前存在的局限性,表明向图像模态的代码表示方式转变,有望成为实现更高效推理的重要技术路径。
一句话总结
来自上海交通大学、新加坡管理大学等机构的研究人员提出,将源代码作为压缩图像输入多模态大语言模型(MLLM),在保持性能的同时实现最高达 8 倍的 token 减少,利用语法高亮等视觉线索提升代码理解与克隆检测效率。
主要贡献
- 随着代码库增长,传统 LLM 因 token 线性增长面临效率瓶颈;本工作首创使用渲染后的代码图像作为可压缩替代方案,在保持语义理解的前提下实现最高 8 倍 token 减少。
- 多模态 LLM 能有效利用语法高亮等视觉特征,在 4 倍压缩下提升代码补全准确率,证明视觉线索比纯文本输入更能增强性能。
- 代码克隆检测任务在图像压缩下表现强韧性,部分压缩比甚至优于原始文本输入,验证图像表示是可扩展代码理解的高效可行路径。
引言
作者利用多模态大语言模型(MLLM)探索将源代码表示为图像而非文本,旨在降低代码库增长带来的计算成本。传统 LLM 将代码视为线性 token 序列,压缩易失真且效率低;尽管 MLLM 具备视觉能力,此前工作缺乏对代码图像的系统性评估。本文主要贡献为一项全面实证研究,表明 MLLM 能有效理解代码图像——即使在高达 8 倍压缩下——部分任务如克隆检测甚至优于文本基线。作者还引入 CODEOCR 工具,用于渲染具有视觉增强的可压缩代码图像,并识别模型特异性韧性模式与最优渲染策略。
数据集
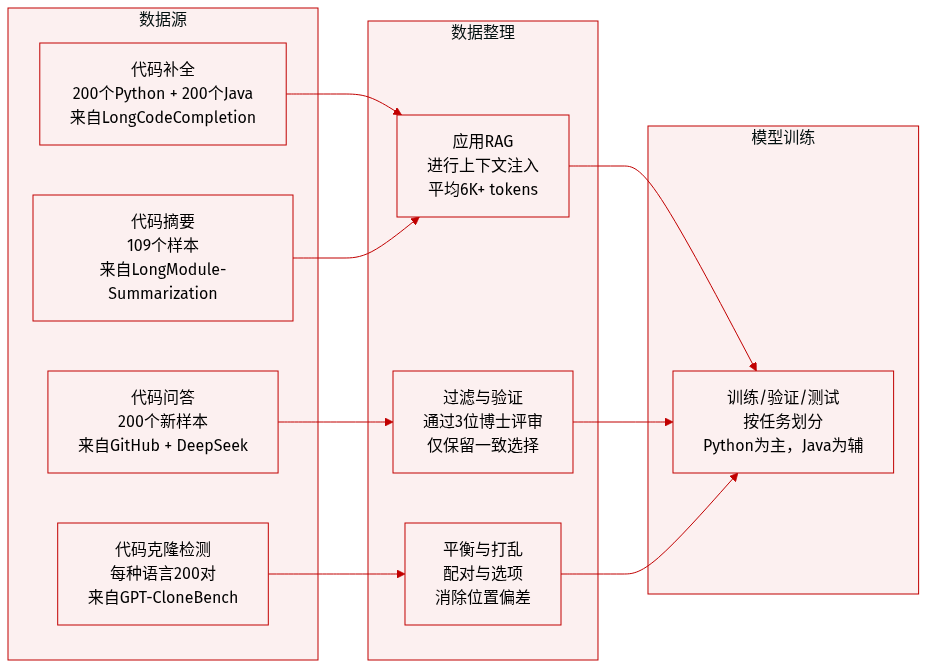
作者采用四个精选基准任务评估视觉代码理解能力,各任务针对不同理解层级,并采用特定指标与上下文处理方式:
-
代码补全:
采用 LongCodeCompletion(Guo 等,2023)中的 200 个 Python 和 200 个 Java 样本,取自挑战性子集(Shi 等,2025a)。应用 RAG 注入相关代码上下文(Python 平均 6,139 token,Java 平均 5,654 token)。评估指标为 Exact Match 和 Edit Similarity。 -
代码摘要:
基于 LongModule-Summarization(Bogomolov 等,2024),共 109 个样本,平均 6,184 token。使用 CompScore —— 通过 DeepSeek-V3.2 作为评判模型的指标 —— 并采用双向平均确保公平性(得分 0–100)。 -
代码克隆检测:
来自 GPT-CloneBench(Alam 等,2023),聚焦 Type-4 语义克隆。每种语言采样 200 个平衡对(100 正例,100 负例)(Python 平均 125 token,Java 平均 216 token)。评估指标为 Accuracy 和 F1。 -
代码问答:
构建新 200 样本数据集,避免 LongCodeQA(Rando 等,2025)中的数据泄露。爬取 35 个 2025 年 8 月后 GitHub 仓库,通过 DeepSeek-V3.2 生成 1,000 个候选问答对,再经 3 名博士验证确保问题有效性、上下文必要性与答案无歧义性。最终数据集打乱顺序以消除位置偏差。评估指标为 Accuracy。
所有 token 长度使用 Qwen-3-VL 的 tokenizer 计算。数据集用于跨语言代码理解探究,以 Python 为主,Java 用于扩展分析。
方法
作者采用多模态流水线,使大语言模型能将源代码作为视觉输入处理,绕过传统文本分词。框架始于将源代码渲染为高分辨率图像——默认 2240×2240 像素——以兼容常见基于 patch 的视觉编码器。该分辨率可确保图像被划分为固定大小的 patch(如 14×14 像素)时无部分 tile,保留视觉保真度。渲染图像可包含语法高亮或加粗样式以增强视觉线索,并与文本指令提示一同处理。
参见框架图,其展示四阶段处理流水线。阶段 1:输入为渲染代码图像 I∈RH×W×3 与自然语言指令。阶段 2:编码阶段,图像被切分为 patch,视觉 Transformer 编码器生成视觉嵌入序列 V=Encoder(I)={v1,v2,…,vN},其中每个 vi 表示一个 patch 的视觉特征。同时,文本提示被分词为子词单元,并通过查找表映射为文本嵌入。
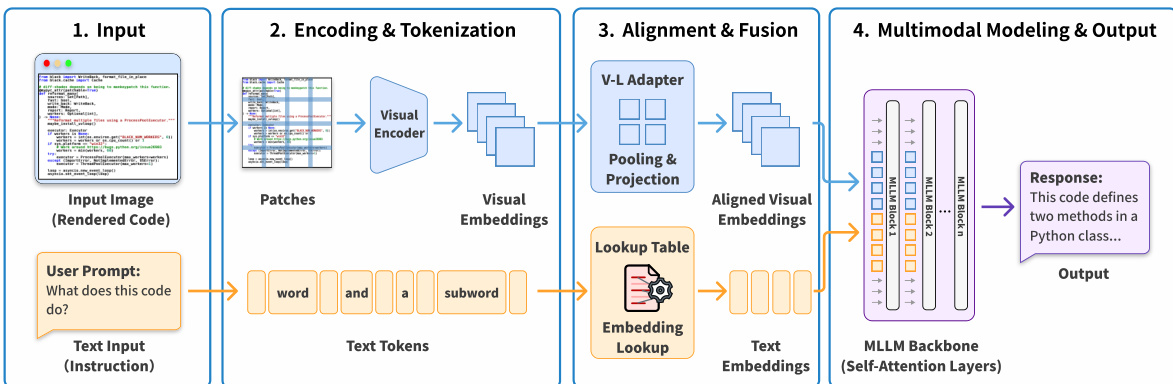
阶段 3:对齐与融合。V-L 适配器应用池化操作(如 2×2 patch 合并),将相邻视觉嵌入压缩为更密集表示。例如,池化操作通过拼接和 MLP 投影合并四个 patch:
Tv=MLP(Concat(vi,i,vi+1,i,vi,i+1,vi+1,i+1))这在保留语义结构的同时减少视觉 token 数量。对齐后的视觉嵌入随后与文本嵌入拼接,形成统一输入序列:
Input=[Tv;Ttext]阶段 4:MLLM 主干,通常由自注意力层组成,处理融合序列生成响应。与依赖离散语法的纯文本模型不同,MLLM 直接从像素数据解读连续视觉模式(如缩进、括号对齐、颜色编码),实现对代码结构的空间推理。
为优化成本与效率,作者引入动态分辨率压缩。从高分辨率基础图像出发,应用双线性下采样实现目标压缩比(1×, 2×, 4×, 8×),视觉 token 数减少至原始文本 token 数的 1/k。这允许用户在视觉保真度与 token 节省间权衡,同时保持下游任务性能。
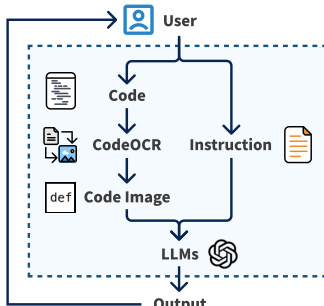
CODEOCR 中间件实现该流水线。如工作流图所示,用户输入代码与指令,CODEOCR 渲染为语法高亮图像并动态压缩以满足指定 token 预算。结果图像与文本指令一同输入 MLLM,模型输出返回用户。内部,CODEOCR 使用 Pygments 进行语法分析,Pillow 进行渲染,支持六种核心语言,通过 Pygments 解析器生态系统可扩展至 500+ 语言。
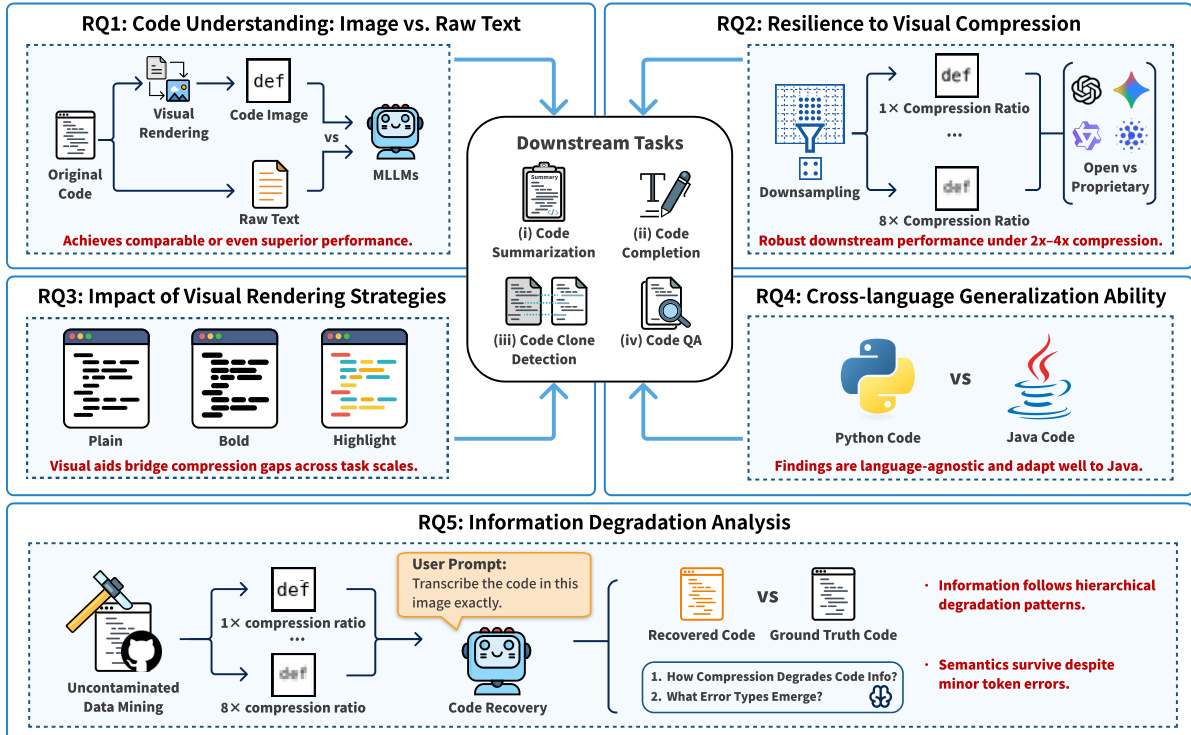
实证设计如研究概览图所示,评估四个下游任务(代码摘要、补全、克隆检测、问答)中的五个研究问题。作者对比视觉代码输入与原始文本基线,评估压缩韧性、渲染策略(纯文本、加粗、高亮)、跨语言泛化能力及压缩下信息退化情况。系统性评估证实,视觉代码表示不仅匹配甚至常优于文本性能,尤其在压缩下,并能稳健适应不同编程语言。
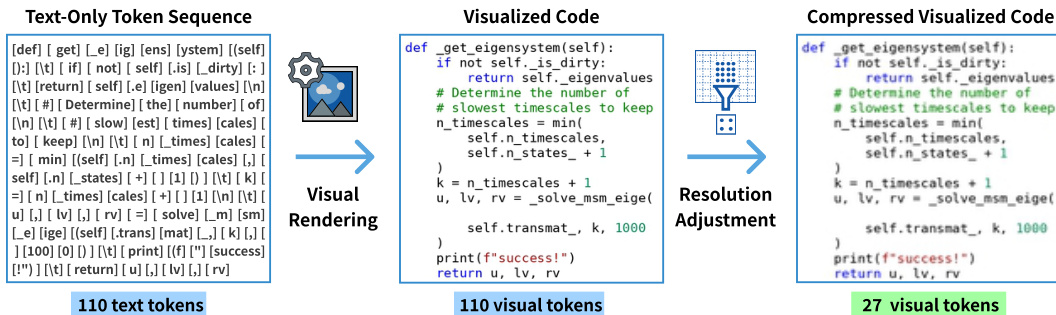
视觉渲染与压缩过程进一步在转换图中说明:110 个文本 token 经渲染转为 110 个视觉 token,再经分辨率调整压缩为 27 个视觉 token——在不牺牲任务性能前提下实现显著 token 节省。
该架构使 MLLM 能将代码视为视觉对象,解锁结构化内容表示的新模态,同时保持与现有文本指令范式的兼容性。
实验
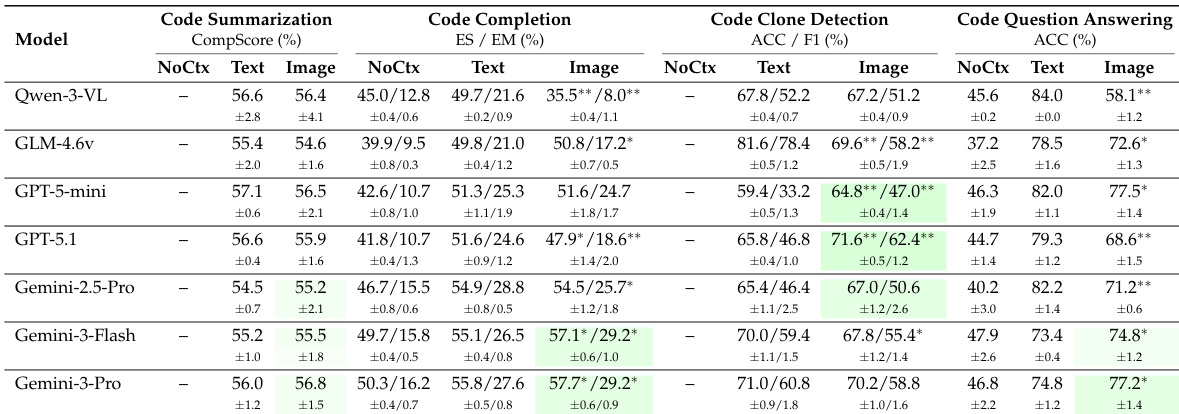
- LLM 能有效理解代码图像,在克隆检测和代码补全等关键任务中匹配或超越文本基线性能,尤其在 Gemini-3-Pro 和 GPT-5.1 等模型上表现突出。
- 视觉压缩(最高 8 倍)在摘要与克隆检测中容忍良好,但代码补全与问答在多数模型下超过 2–4 倍压缩后性能下降,仅顶级模型如 Gemini-3-Pro 在压缩下表现提升。
- 语法高亮与加粗渲染在低至中等压缩(1x–4x)下显著增强代码图像理解能力,尤其对高级模型,但在高压缩下收益递减。
- 发现跨编程语言泛化:性能、压缩韧性与增强收益的核心模式在 Java 与 Python 中均成立。
- 压缩分层退化代码信息:token 错误最先出现,中等压缩下出现行错误,高压缩下块错误主导;Gemini-3 模型维持低块错误率,解释其下游性能稳定。
- 视觉代码处理引入的延迟开销可忽略,支持实用部署,压缩甚至可带来速度提升。
结果表明,大语言模型能有效理解图像形式的代码,部分模型在多项编程任务中达到或超越文本输入性能。表现因模型与任务显著差异,先进模型如 Gemini-3-Pro 对视觉压缩强韧,受益于语法高亮或加粗渲染;较弱模型常在压缩下退化。发现跨语言泛化,视觉代码处理引入极小延迟开销,支持实用部署。
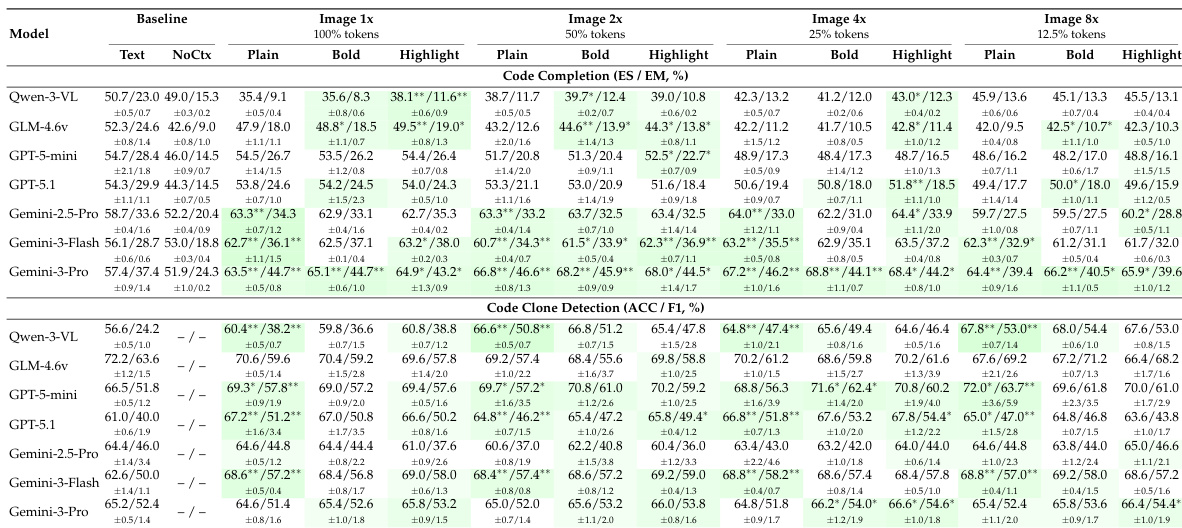
作者在不同压缩级别与渲染风格下,评估七个 MLLM 在代码理解任务中的表现。结果表明,视觉代码表示可匹配或超越文本性能,尤其在克隆检测与摘要任务中,强模型如 Gemini-3-Pro 在高压缩下仍保持稳健。语法高亮与加粗等视觉增强在中等压缩下提升性能,但在极端压缩下收益递减。
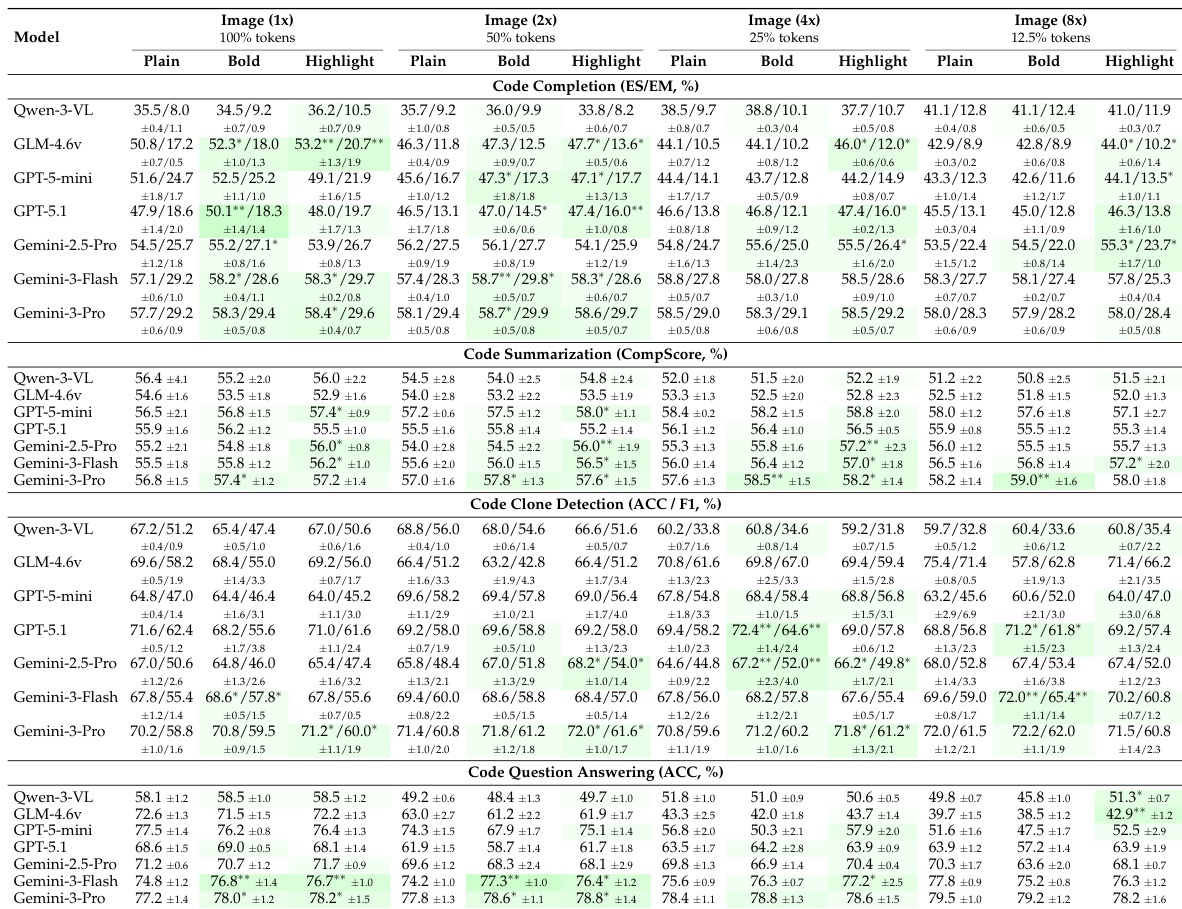
结果表明,大语言模型能有效理解图像形式的代码,部分模型在多项编程任务中达到或优于文本输入性能。表现因模型与任务差异显著,Gemini-3-Pro 在原始与压缩视觉输入中均表现稳定,而开源模型如 Qwen-3-VL 和 GLM-4.6v 在视觉或压缩条件下显著退化。语法高亮与加粗等视觉增强在中等压缩水平提升性能,但在高压缩比下因图像清晰度降低而收益递减。