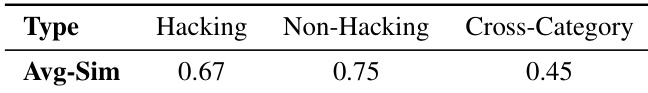Command Palette
Search for a command to run...
实时对齐的奖励模型:超越语义
实时对齐的奖励模型:超越语义
摘要
基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)是实现大语言模型(Large Language Models, LLMs)与人类偏好对齐的关键技术,然而其易受奖励过优化(reward overoptimization)问题的影响:即策略模型过度拟合奖励模型,转而利用虚假的奖励信号模式,而非忠实捕捉人类的真实意图。以往的缓解方法主要依赖于表面语义信息,难以有效应对因策略分布持续变化所引发的奖励模型(Reward Model, RM)与策略模型之间的错位问题。这一缺陷不可避免地导致奖励偏差不断加剧,进一步恶化了奖励过优化现象。为解决上述局限,本文提出一种新型轻量级RLHF框架——R2M(Real-Time Aligned Reward Model)。R2M突破了传统奖励模型仅依赖预训练语言模型语义表征的局限,转而利用策略模型在强化学习过程中的动态隐藏状态(即策略反馈),实时捕捉策略分布的变化趋势,从而实现与策略模型动态分布的同步对齐。该方法为提升奖励模型性能开辟了一条具有前景的新路径,即通过实时整合策略模型的反馈信息,增强奖励模型的适应性与鲁棒性。
一句话总结
来自多个机构的研究人员提出了 R2M,这是一种轻量级的 RLHF 框架,通过实时隐藏状态反馈动态对齐奖励模型与策略变化,克服奖励过优化问题,不再依赖静态语义表示,从而更好地捕捉训练过程中不断演变的人类意图。
主要贡献
- R2M 通过动态对齐奖励模型与策略不断演化的隐藏状态来解决 RLHF 中的奖励过优化问题,缓解分布偏移,无需重新训练或额外标注数据。
- 该框架通过将策略反馈集成到评分头中来增强奖励模型,实现实时适应策略行为,同时保持计算效率并与现有 RLHF 流程兼容。
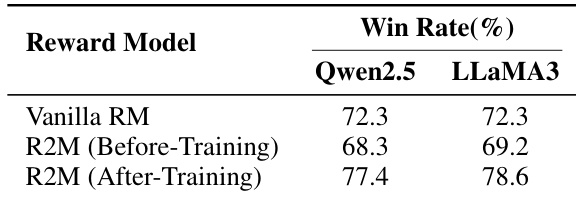
- 在 UltraFeedback 和 TL;DR 数据集上评估,R2M 将 AlpacaEval 胜率提升 5.2%–8.0%,TL;DR 胜率提升 6.3%,在计算开销极小的情况下展现出稳定提升。
引言
作者利用 RLHF 期间策略模型不断演化的隐藏状态,动态对齐奖励模型与实时分布偏移,解决传统奖励建模的关键局限。先前方法要么依赖静态语义表示,要么需要昂贵的重新训练,无法在策略演化时有效纠正错位——导致奖励过优化,即模型利用表面线索而非真正的人类意图。R2M 引入一种轻量级、即插即用的框架,通过策略反馈调整奖励模型的评分头,无需重新训练完整模型或新增标注数据。这实现了持续对齐,减少奖励操纵,并在对话和摘要任务中以极低计算开销提升性能。
数据集

- 作者从 UltraFeedback 的偏好子集中采样 100 对“优选”和 100 对“拒绝”的查询-响应对,提取 LLaMA3-8B-Instruct 特定层(6、12、18、24、30)的隐藏状态。
- 对每对样本,将词元级隐藏状态平均为单个向量,然后计算每层 200 个向量间的余弦相似度,每层生成 19,900 对。
- 这些对被划分为两个子集:同类(相同偏好标签)和跨类(不同标签),分别计算平均余弦相似度。
- 在第 30 层,采样 300 对样本,将其隐藏状态相似度与 Skywork-Reward-V2-Llama-3.1-8B 的奖励差异相关联。
- 对于 TL;DR 任务,每训练步从 TL;DR 数据集中采样 2048 个查询,每个响应最多生成 50 个词元,使用 RL 与算法 1 训练 1M 轨迹。
- 使用 Pythia-2.8B-TL;DR-SFT 作为策略模型,Pythia-2.8B-TL;DR-RM 作为奖励模型,学习率为 3e-6,Ω=0.6,组大小为 4。
- 训练后,使用 GPT-4 作为评判器评估摘要质量,与 TL;DR 中的参考摘要比较以计算胜率。
方法
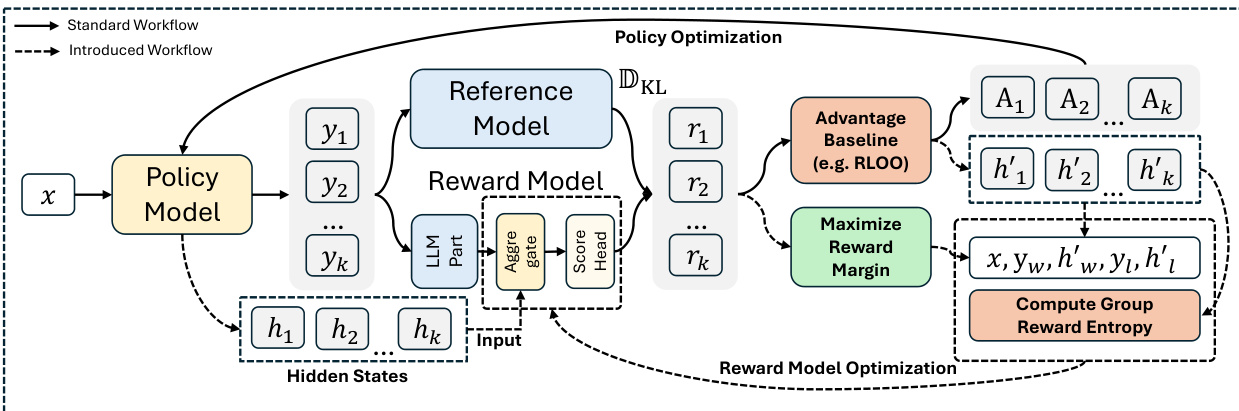
作者提出一种新颖架构 R2M,旨在 RLHF 的 RL 优化阶段通过引入实时策略反馈来增强奖励模型。核心创新在于将策略模型的内部隐藏状态结构化地整合进奖励模型的评分机制,使奖励模型能够动态适应策略的演化分布。这通过两个关键模块实现:序列到词元交叉注意力机制和基于时间步的加权组合策略,二者均在迭代优化循环中运行。
如框架图所示,整体工作流始于轨迹采样,当前策略模型为每个查询生成 K 个响应。同时,收集每个查询-响应对的策略模型最后一层隐藏状态。这些隐藏状态记为 hi,j,作为策略反馈信号。在奖励标注阶段,奖励模型通过其 LLM 组件处理查询-响应对,获得标准奖励词元嵌入(RTE)Hlasti,j。与普通奖励建模的关键区别在此出现:策略反馈 hi,j 通过交叉注意力模块注入奖励模型。该模块将 RTE 作为查询,策略隐藏状态作为键和值,执行序列到词元注意力操作,生成聚合 RTE Hlasti,j,融合语义与策略状态信息。
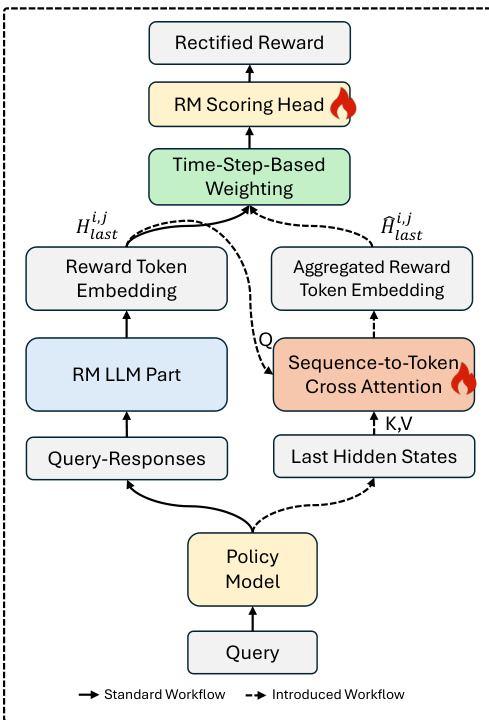
最终奖励词元嵌入 Hfini,j 通过结合原始 RTE 与聚合 RTE,并使用基于时间步的加权函数 ω(t) 构建。该函数定义为 ω(t)=max(21cos(Ttπ)+21,Ω),确保训练初期模型更依赖已建立的语义表示,而后期逐步强调策略反馈以适应分布偏移。最终标量奖励通过将 Hfini,j 输入评分头 ϕ 计算得出。
训练过程是迭代且轻量的。在策略优化步骤(更新策略模型 πθ 及其隐藏状态)后,触发独立的奖励模型优化阶段。该阶段不重新训练奖励模型的完整 LLM 组件,而是仅更新交叉注意力模块和评分头 ϕ,使用新颖的组奖励熵布拉德利-特里(GREBT)损失。该损失结合标准布拉德利-特里目标(从偏好对 (xi,yi,w,hi,w,yi,l,hi,l) 学习)与组奖励熵(GRE)正则化项。GRE 项定义为 −∑j=1Kpi,jlogpi,j,其中 pi,j 是组内标准化奖励的 softmax,明确鼓励奖励多样性以缓解“组退化”问题(即奖励模型为组内所有响应分配几乎相同的分数)。总损失为 LGREBT(i;φ)=(1−α)LBT(i;φ)+αLGRE(i;φ),其中 α 控制权衡。这种迭代轻量优化使奖励模型能基于最新策略状态持续优化评分,且计算成本极低。
实验
- Transformer 策略的深层隐藏状态与人类偏好和奖励分数高度相关,验证其可用于超越语义特征增强奖励模型。
- R2M 将策略反馈集成到奖励建模中,在对话和摘要任务上持续优于 vanilla RL 和基线方法,展示广泛适用性及与人类偏好的更优对齐。
- 策略反馈至关重要:冻结 R2M 或用噪声替代反馈会降低性能,确认利用隐藏状态的自适应更新是获得提升的必要条件。
- R2M 显著提高奖励模型的准确性和校准能力,支持更激进但稳定的策略更新,同时避免触发奖励过优化。
- 消融研究确认 R2M 所有组件——反馈集成、混合 GREBT 损失和迭代更新——均为不可或缺;移除任一均导致显著性能下降。
- R2M 计算效率高,引入极小开销却实现显著提升,得益于轻量级注意力反馈聚合和部分模型更新。
- 隐藏状态能有效检测奖励过优化模式和策略分布偏移,支持 R2M 的双重策略:动态奖励适应与更深层语义对齐。
作者通过 R2M 将策略反馈集成到奖励模型训练中,持续优于包括预训练和迭代更新奖励模型在内的基线方法。结果表明,仅使用策略反馈而不进行模型适应会降低性能,而完整 R2M 训练显著提升 GRPO 和 RLOO 框架下的胜率。这表明,由策略反馈引导的迭代奖励模型更新对有效对齐人类偏好至关重要。
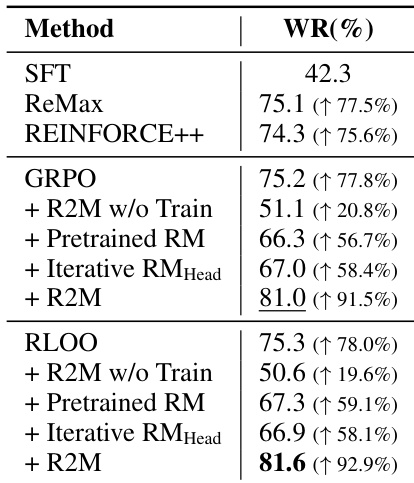
作者通过 R2M 将策略反馈集成到奖励模型训练中,在对话和摘要任务的多个评估指标上持续优于基线方法。结果表明,使用策略衍生隐藏状态的迭代更新显著提升奖励模型准确性和与人类偏好的对齐,消融研究确认 R2M 的每个组件均对性能有显著贡献。该方法支持更激进且有效的策略更新,同时避免触发奖励过优化,展示其在真实 RLHF 设置中的鲁棒性。
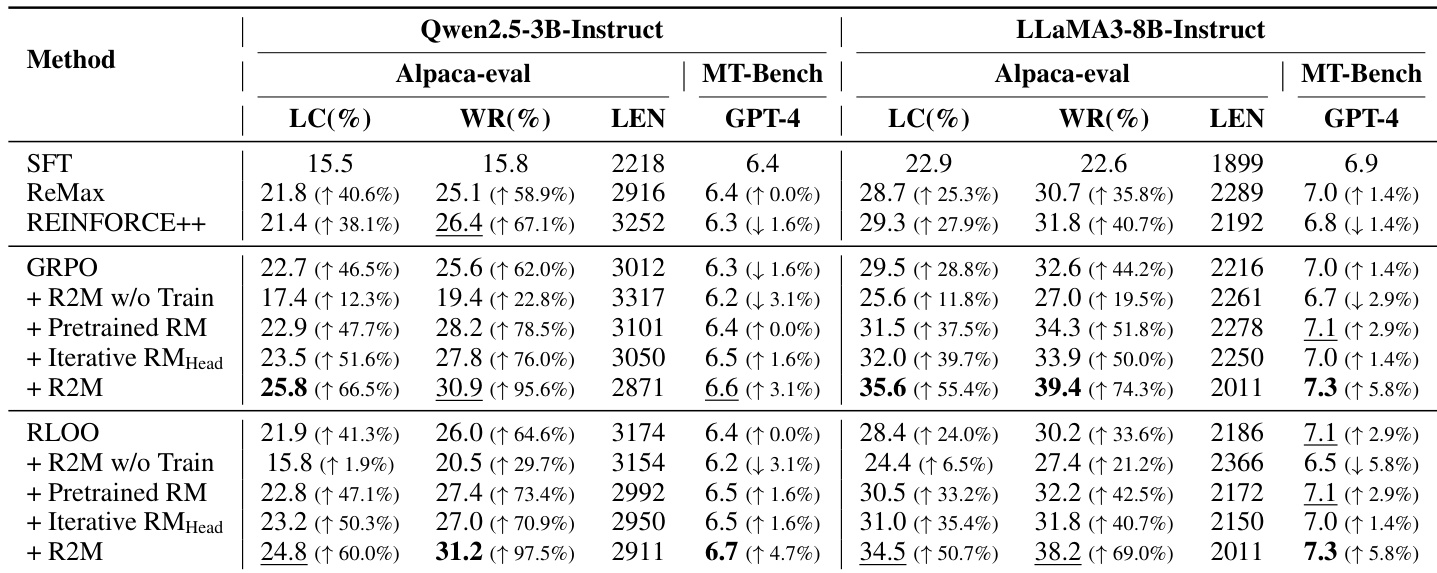
作者通过 R2M 将策略反馈集成到奖励模型训练中,持续优于包括冻结和噪声增强变体在内的基线方法。结果表明,使用策略衍生隐藏状态更新奖励模型对性能提升至关重要,静态或未训练反馈仅带来微小改进。完整 R2M 方法实现最高胜率,确认与策略动态的迭代对齐可提升奖励信号质量和模型与人类偏好的对齐。
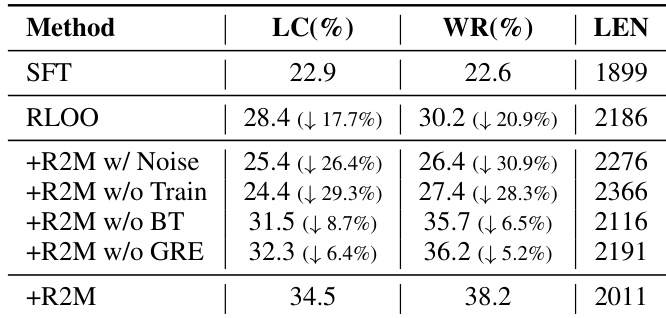
作者使用 R2M 通过训练中整合策略反馈迭代更新奖励模型,显著提升其在偏好预测上的准确性。结果表明,训练后 R2M 优于 vanilla 奖励模型及其预训练版本,确认策略反馈增强奖励与人类偏好的对齐。此提升在不同策略模型中保持一致,源于模型利用深层隐藏状态进行更可靠的奖励分配。
作者使用隐藏状态相似度区分表现出奖励过优化的响应与正常输出,发现同类相似度显著高于跨类相似度。这支持将策略隐藏状态作为检测奖励操纵行为的指标。结果表明,此类语义和状态信号可帮助对齐奖励模型与真实人类偏好并缓解过优化。